Velkommen til den tredje – og sidste – del af denne blogserie, der udforsker, hvordan PostgreSQL-ydelsen udviklede sig gennem årene. Den første del så på OLTP-arbejdsbelastninger, repræsenteret ved pgbench-tests. Den anden del så på analytiske / BI-forespørgsler ved hjælp af en delmængde af det traditionelle TPC-H-benchmark (i det væsentlige en del af effekttesten).
Og denne sidste del ser på fuldtekstsøgning, dvs. evnen til at indeksere og søge i store mængder tekstdata. Den samme infrastruktur (især indekserne) kan være nyttig til at indeksere semistrukturerede data som JSONB-dokumenter osv., men det er ikke det, denne benchmark fokuserer på.
Men lad os først se på historien om fuldtekstsøgning i PostgreSQL, hvilket kan virke som en mærkelig funktion at tilføje til et RDBMS, traditionelt beregnet til lagring af strukturerede data i rækker og kolonner.
Historien om fuldtekstsøgning
Da Postgres blev open source i 1996, havde den ikke noget, vi kunne kalde fuldtekstsøgning. Men folk, der begyndte at bruge Postgres, ønskede at lave intelligente søgninger i tekstdokumenter, og LIKE-forespørgslerne var ikke gode nok. De ønskede at være i stand til at lemmatisere termerne ved hjælp af ordbøger, ignorere stopord, sortere de matchende dokumenter efter relevans, bruge indekser til at udføre disse forespørgsler og mange andre ting. Ting du ikke med rimelighed kan gøre med de traditionelle SQL-operatorer.
Heldigvis var nogle af disse mennesker også udviklere, så de begyndte at arbejde på dette – og det kunne de, takket være at PostgreSQL var tilgængelig som open source over hele verden. Der har været mange bidragydere til fuldtekstsøgning gennem årene, men i første omgang blev denne indsats ledet af Oleg Bartunov og Teodor Sigaev, vist på det følgende billede. Begge er stadig store PostgreSQL-bidragydere og arbejder på fuldtekstsøgning, indeksering, JSON-understøttelse og mange andre funktioner.

Teodor Sigaev og Oleg Bartunov
Oprindeligt blev funktionaliteten udviklet som et eksternt "bidrag"-modul (i dag vil vi sige, det er en udvidelse) kaldet "tsearch", udgivet i 2002. Senere blev dette forældet af tsearch2, hvilket væsentligt forbedrede funktionen på mange måder, og i PostgreSQL 8.3 (frigivet i 2008) denne var fuldt integreret i PostgreSQL-kernen (dvs. uden behov for overhovedet at installere nogen udvidelse, selvom udvidelserne stadig blev leveret for bagudkompatibilitet).
Der har været mange forbedringer siden da (og arbejdet fortsætter, f.eks. for at understøtte datatyper som JSONB, forespørgsel ved hjælp af jsonpath osv.). men disse plugins introducerede det meste af den fuldtekstfunktionalitet, vi har i PostgreSQL nu – ordbøger, fuldtekstindeksering og forespørgselsfunktioner osv.
Benchmark
I modsætning til OLTP / TPC-H benchmarks, er jeg ikke bekendt med nogen fuldtekst benchmark, der kunne betragtes som "industristandard" eller designet til flere databasesystemer. De fleste af de benchmarks, jeg kender til, er beregnet til at blive brugt med en enkelt database/produkt, og det er svært at overføre dem meningsfuldt, så jeg var nødt til at tage en anden rute og skrive mit eget benchmark i fuld tekst.
For år siden skrev jeg archie – et par python-scripts, der tillader download af PostgreSQL-postlistearkiver og indlæser de parsede meddelelser i en PostgreSQL-database, som derefter kan indekseres og søges. Det aktuelle øjebliksbillede af alle arkiver har ~1M rækker, og efter indlæsning af det i en database er tabellen omkring 9,5 GB (indekserne tæller ikke med).
Hvad angår forespørgslerne, kunne jeg nok generere nogle tilfældige, men jeg er ikke sikker på, hvor realistisk det ville være. Heldigvis fik jeg for et par år siden en prøve på 33.000 faktiske søgninger fra PostgreSQL-webstedet (dvs. ting, folk rent faktisk søgte i fællesskabets arkiver). Det er usandsynligt, at jeg kunne få noget mere realistisk/repræsentativt.
Kombinationen af disse to dele (datasæt + forespørgsler) virker som et godt benchmark. Vi kan simpelthen indlæse dataene og køre søgningerne med forskellige typer fuldtekstforespørgsler med forskellige typer indekser.
Forespørgsler
Der er forskellige former for fuldtekstforespørgsler – forespørgslen kan ganske enkelt vælge alle matchende rækker, den kan rangordne resultaterne (sortere dem efter relevans), returnere kun et lille antal eller de mest relevante resultater osv. Jeg kørte benchmark med forskellige typer forespørgsler, men i dette indlæg vil jeg præsentere resultater for to simple forespørgsler, som jeg synes repræsenterer den overordnede adfærd ganske pænt.
- VÆLG id, emne FRA beskeder WHERE body_tsvector @@ $1
- SELECT id, subject FROM beskeder WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
Den første forespørgsel returnerer simpelthen alle matchende rækker, mens den anden returnerer de 100 mest relevante resultater (dette er noget, du sandsynligvis ville bruge til brugersøgninger).
Jeg har eksperimenteret med forskellige andre typer forespørgsler, men alle opførte sig i sidste ende på en måde, der ligner en af disse to forespørgselstyper.
Indekser
Hver besked har to hoveddele, som vi kan søge i – emne og krop. Hver af dem har en separat tsvector-kolonne og indekseres separat. Budskabsemnerne er meget kortere end brødtekster, så indekserne er naturligvis mindre.
PostgreSQL har to typer indekser, der er nyttige til fuldtekstsøgning - GIN og GiST. De vigtigste forskelle er forklaret i dokumenterne, men kort sagt:
- GIN-indekser er hurtigere til søgninger
- GiST-indekser er tabsgivende, dvs. kræver genkontrol under søgninger (og derfor er langsommere)
Vi plejede at hævde, at GiST-indekser er billigere at opdatere (især med mange samtidige sessioner), men dette blev fjernet fra dokumentationen for noget tid siden på grund af forbedringer i indekseringskoden.
Dette benchmark tester ikke adfærd med opdateringer – det indlæser simpelthen tabellen uden fuldtekstindekser, bygger dem på én gang og udfører derefter 33.000 forespørgsler på dataene. Det betyder, at jeg ikke kan udtale mig om, hvordan disse indekstyper håndterer samtidige opdateringer baseret på dette benchmark, men jeg mener, at dokumentationsændringerne afspejler forskellige nylige GIN-forbedringer.
Dette burde også matche mailinglistens arkivbrug ganske godt, hvor vi kun ville tilføje nye e-mails en gang imellem (få opdateringer, næsten ingen skrivesammenfald). Men hvis din applikation laver mange samtidige opdateringer, bliver du nødt til at benchmarke det på egen hånd.
Hardwaren
Jeg lavede benchmark på de samme to maskiner som før, men resultaterne/konklusionerne er næsten identiske, så jeg vil kun præsentere tallene fra den mindre, dvs.
- CPU i5-2500K (4 kerner/tråde)
- 8 GB RAM
- 6 x 100 GB SSD RAID0
- kerne 5.6.15, ext4 filsystem
Jeg har tidligere nævnt, at datasættet har næsten 10 GB, når det er indlæst, så det er større end RAM. Men indekserne er stadig mindre end RAM, hvilket er det, der betyder noget for benchmark.
Resultater
OK, tid til nogle tal og diagrammer. Jeg vil præsentere resultater for både dataindlæsninger og forespørgsler, først med GIN og derefter med GiST-indekser.
GIN / dataindlæsning
Ladningen er ikke specielt interessant, synes jeg. For det første har det meste (den blå del) intet med fuldtekst at gøre, fordi det sker før de to indekser er oprettet. Det meste af denne tid bruges på at analysere meddelelserne, genopbygge mailtrådene, vedligeholde listen over svar og så videre. Noget af denne kode er implementeret i PL/pgSQL triggere, noget af det er implementeret uden for databasen. Den ene del, der potentielt er relevant for fuldtekst, er at bygge tsvektorerne, men det er umuligt at isolere den tid, der bruges på det.
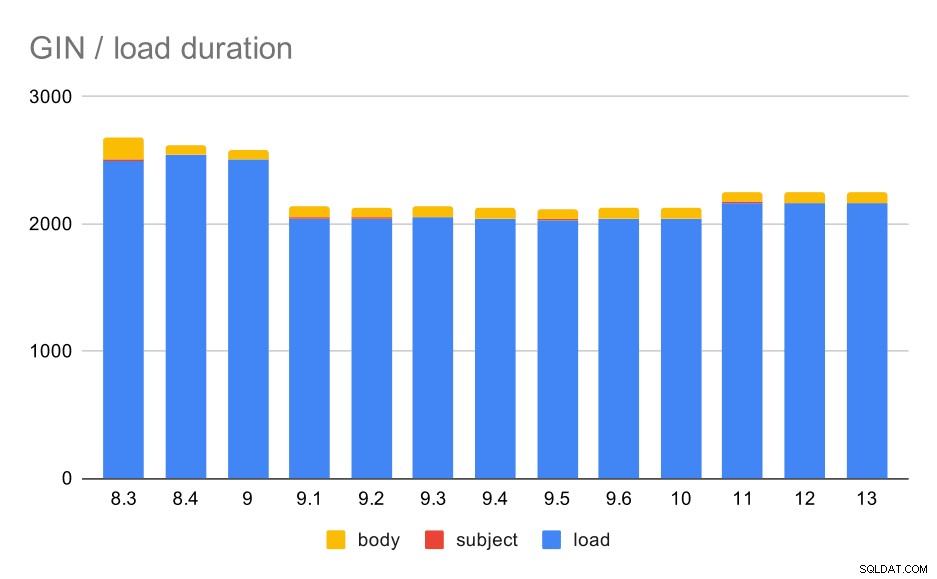
Dataindlæsningsoperationer med en tabel og GIN-indekser.
Følgende tabel viser kildedataene for dette diagram – værdier er varighed i sekunder. LOAD inkluderer parsing af mbox-arkiverne (fra et Python-script), indsættelse i en tabel og diverse yderligere opgaver (genopbygning af e-mail-tråde osv.). SUBJECT/BODY INDEX refererer til oprettelse af fuldtekst GIN-indeks på emne/body-kolonner, efter at dataene er indlæst.
| INDLÆS | EMNEINDEKS | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Det er klart, at ydeevnen er ret stabil – der har været en ret betydelig forbedring (omtrent 20%) mellem 9,0 og 9,1. Jeg er ikke helt sikker på, hvilken ændring der kan være ansvarlig for denne forbedring - intet i 9.1-udgivelsesnoterne virker klart relevant. Der er også en klar forbedring i opbygningen af GIN-indekserne i 8.4, hvilket halverer tiden. Hvilket selvfølgelig er rart. Interessant nok ser jeg heller ikke noget åbenlyst relateret udgivelsesbemærkning til dette.
Hvad med størrelserne på GIN-indekserne? Der er meget mere variation, i det mindste indtil 9.4, hvorefter størrelsen af indekser falder fra ~1GB til kun omkring 670MB (ca. 30%).
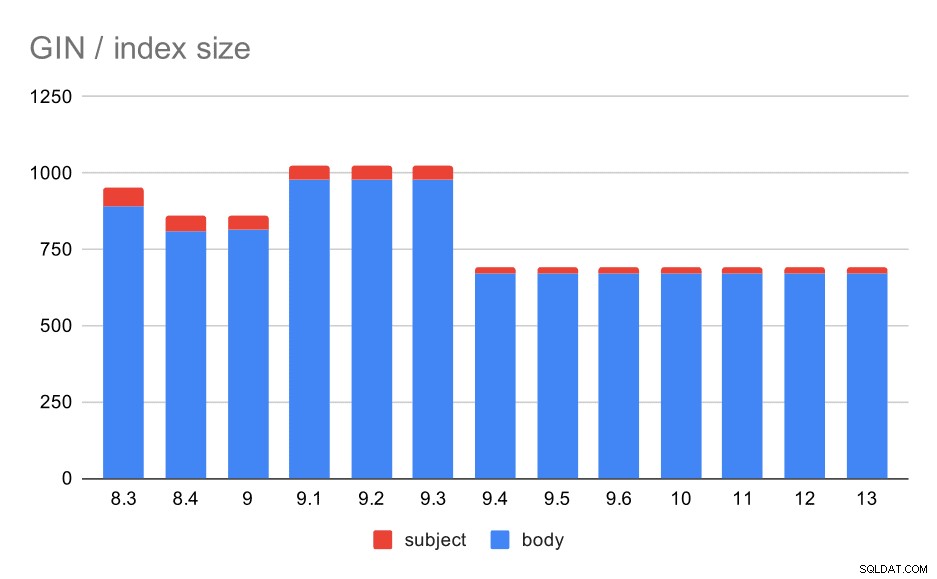
Størrelse af GIN-indekser på meddelelsens emne/brødtekst. Værdier er megabyte.
Følgende tabel viser størrelserne af GIN-indekser på meddelelsestekst og emne. Værdierne er i megabyte.
| BODY | EMNE | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
I dette tilfælde tror jeg, vi med sikkerhed kan antage, at denne hastighed er relateret til denne vare i 9.4 release notes:
- Reducer GIN-indeksstørrelsen (Alexander Korotkov, Heikki Linnakangas)
Størrelsesvariabiliteten mellem 8,3 og 9,1 synes at skyldes ændringer i lemmatisering (hvordan ord omdannes til den "grundlæggende" form). Bortset fra størrelsesforskellene returnerer forespørgslerne på disse versioner f.eks. et lidt anderledes antal resultater.
GIN / forespørgsler
Nu er hoveddelen af dette benchmark - forespørgselsydeevne. Alle de tal, der præsenteres her, er for en enkelt klient - vi har allerede diskuteret klientskalerbarhed i den del, der er relateret til OLTP-ydelse, resultaterne gælder også for disse forespørgsler. (Desuden har denne særlige maskine kun 4 kerner, så vi ville alligevel ikke komme ret langt med hensyn til skalerbarhedstest.)
SELECT id, subject FROM messages WHERE tsvector @@ $1
Først søger forespørgslen efter alle matchende dokumenter. For søgninger i "emne"-kolonnen kan vi lave omkring 800 forespørgsler i sekundet (og det falder faktisk lidt i 9.1), men i 9.4 skyder det pludselig op til 3000 forespørgsler i sekundet. For "body"-kolonnen er det grundlæggende den samme historie - 160 forespørgsler i starten, et fald til ~90 forespørgsler i 9.1 og derefter en stigning til 300 i 9.4.
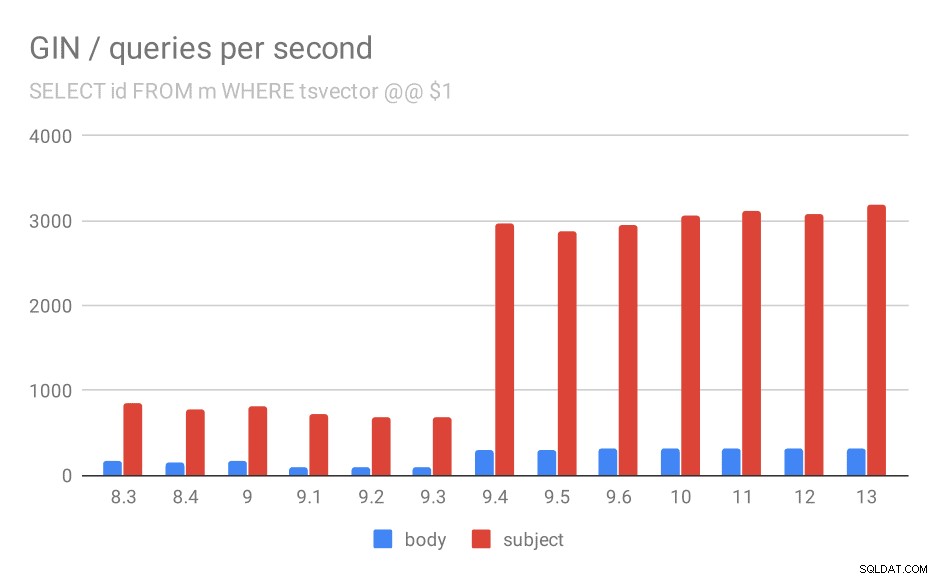
Antal forespørgsler pr. sekund for den første forespørgsel (henter alle matchende rækker).
Og igen, kildedata – tallene er gennemløb (forespørgsler pr. sekund).
| BODY | EMNE | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Jeg tror, vi roligt kan antage, at forbedringen i 9.4 er relateret til dette element i udgivelsesnoter:
- Forbedre hastigheden af multi-key GIN-opslag (Alexander Korotkov, Heikki Linnakangas)
Så endnu en 9.4-forbedring i GIN fra de samme to udviklere – Alexander og Heikki gjorde tydeligvis meget godt arbejde med GIN-indekser i 9.4-udgivelsen 😉
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
For forespørgslen, der rangerer resultaterne efter relevans ved hjælp af ts_rank og LIMIT, er den overordnede adfærd næsten nøjagtig den samme, det er ikke nødvendigt at beskrive diagrammet i detaljer, tror jeg.
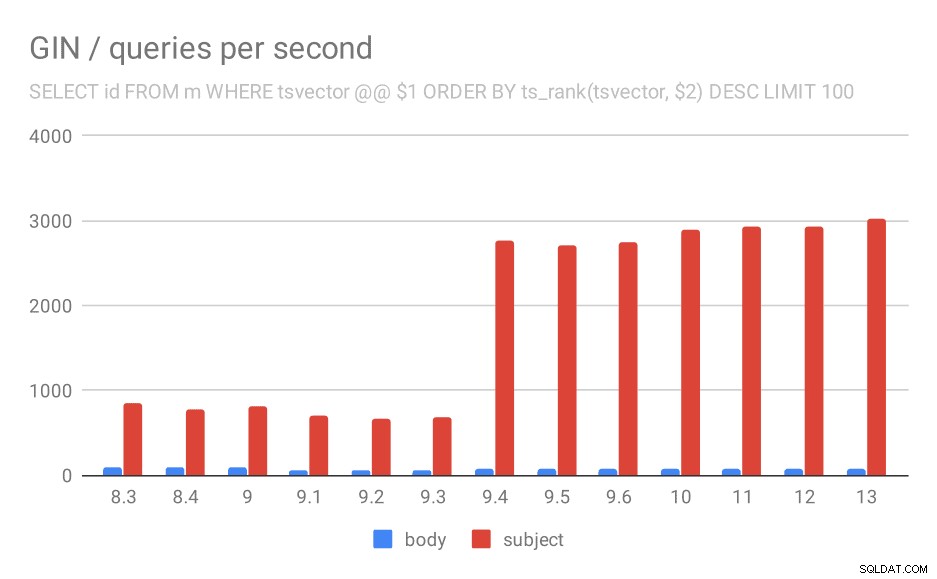
Antal forespørgsler pr. sekund for den anden forespørgsel (henter de mest relevante rækker).
| BODY | EMNE | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Der er dog et spørgsmål - hvorfor faldt ydeevnen mellem 9,0 og 9,1? Der ser ud til at være et ret markant fald i gennemstrømningen – med omkring 50 % for kropssøgninger og 20 % for søgninger i meddelelsesemner. Jeg har ikke en klar forklaring på, hvad der skete, men jeg har to observationer …
For det første ændrede indeksstørrelsen sig - hvis du ser på det første diagram "GIN / indeksstørrelse" og tabellen, vil du se indekset på meddelelseskroppe vokset fra 813 MB til omkring 977 MB. Det er en markant stigning, og det kan måske forklare noget af afmatningen. Problemet er imidlertid, at indekset over emner slet ikke voksede, men alligevel blev forespørgslerne også langsommere.
For det andet kan vi se på, hvor mange resultater forespørgslerne returnerede. Det indekserede datasæt er nøjagtigt det samme, så det virker rimeligt at forvente det samme antal resultater i alle PostgreSQL-versioner, ikke? Nå, i praksis ser det sådan ud:
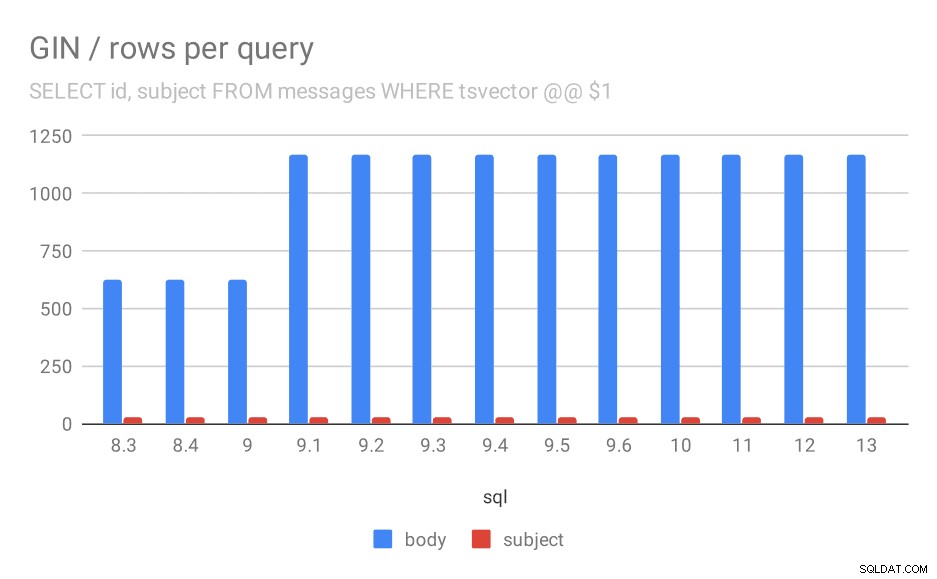
Antal rækker returneret for en forespørgsel i gennemsnit.
| BODY | EMNE | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Det er klart, at i 9.1 fordobles det gennemsnitlige antal resultater for søgninger i meddelelsestekster pludselig, hvilket er næsten perfekt proportionalt med afmatningen. Antallet af resultater for emnesøgninger forbliver dog det samme. Jeg har ikke en særlig god forklaring på dette, bortset fra at indekseringen ændrede sig på en måde, der gør det muligt at matche flere beskeder, men gør det lidt langsommere. Hvis du har bedre forklaringer, vil jeg gerne høre dem!
GiST / dataindlæsning
Nu er den anden type fuldtekstindekser - GiST. Disse indekser er tabsgivende, dvs. kræver genkontrol af resultaterne ved hjælp af værdier fra tabellen. Så vi kan forvente lavere gennemløb sammenlignet med GIN-indekserne, men ellers er det rimeligt at forvente nogenlunde det samme mønster.
Indlæsningstiderne matcher faktisk GIN næsten perfekt - indeksoprettelsestiderne er forskellige, men det overordnede mønster er det samme. Fremskyndelse i 9.1, lille opbremsning i 11.
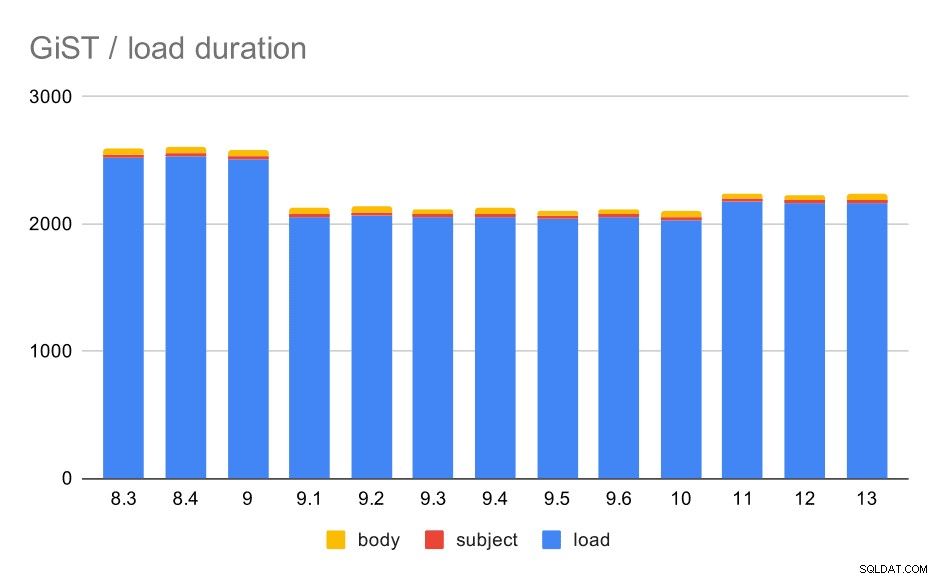
Dataindlæsningsoperationer med en tabel og GiST-indekser.
| INDLÆS | EMNE | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Indeksstørrelsen forblev dog næsten konstant - der var ingen GiST-forbedringer svarende til GIN i 9.4, hvilket reducerede størrelsen med ~30%. Der er en stigning i 9.1, hvilket er endnu et tegn på, at fuldtekstindekseringen blev ændret i den version for at indeksere flere ord.
Dette understøttes yderligere af, at det gennemsnitlige antal resultater med GiST er nøjagtigt det samme som for GIN (med en stigning på 9,1).
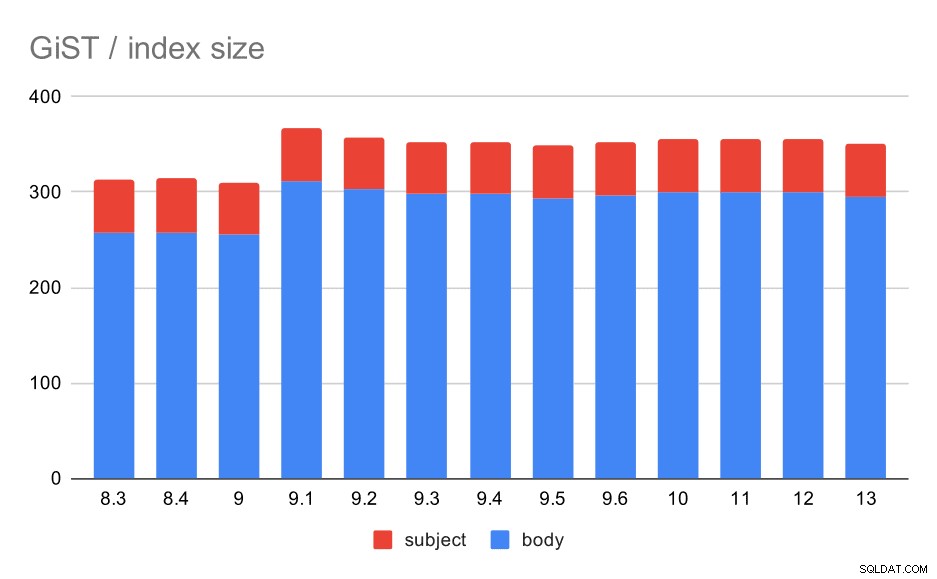
Størrelse af GiST-indekser på meddelelsens emne/brødtekst. Værdier er megabyte.
| BODY | EMNE | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
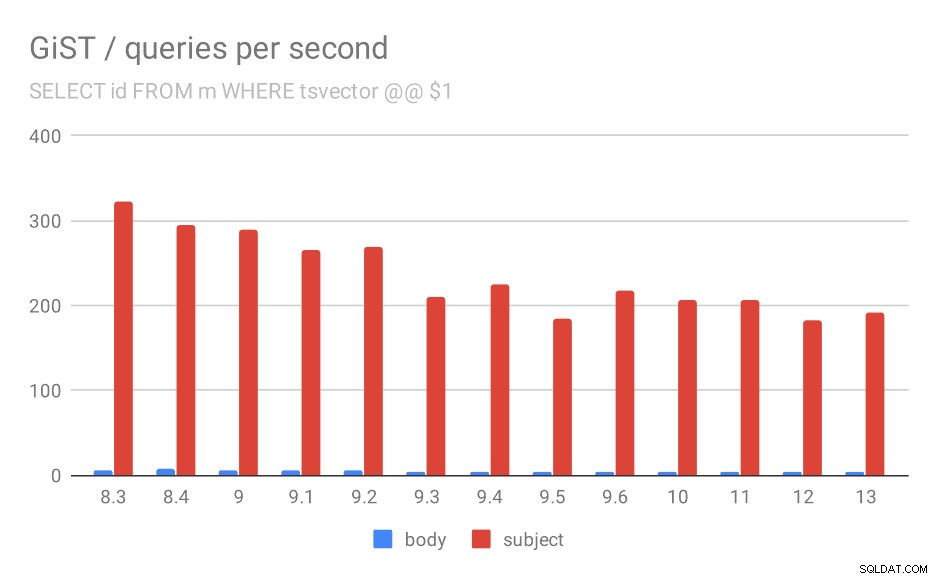
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
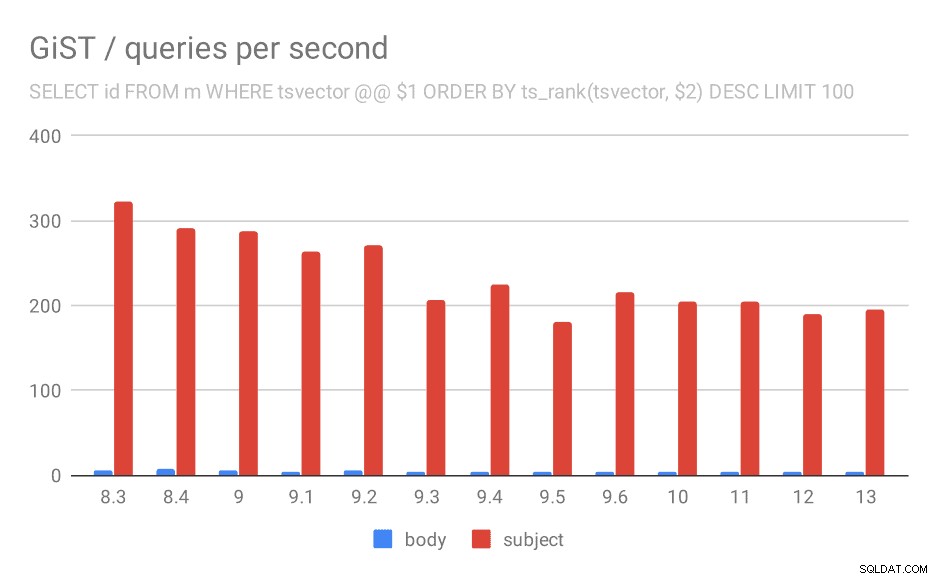
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).