Høj tilgængelighed er et krav for mange systemer, uanset hvilken teknologi du bruger. Dette er især vigtigt for databaser, da de gemmer data, som applikationer er afhængige af. Afhængigt af kravene er der forskellige måder at implementere et High Availability-miljø for PostgreSQL på, men det er altid nødvendigt at bruge et komplementært værktøj, da de indbyggede PostgreSQL-funktioner ikke er nok.
I denne blog vil vi se, hvordan man implementerer Percona Distribution til PostgreSQL for høj tilgængelighed, og hvilken slags værktøjer der er nødvendige for at gøre det.
Percona-distribution til PostgreSQL
Det er en samling værktøjer til at hjælpe dig med at administrere dit PostgreSQL-databasesystem. Det installerer PostgreSQL og supplerer det med et udvalg af udvidelser, der gør det muligt at løse væsentlige praktiske opgaver effektivt, herunder:
- pg_repack :Den genopbygger PostgreSQL-databaseobjekter.
- pgaudit :Det giver detaljeret logføring af sessioner eller objekter via standard PostgreSQL-logningsfaciliteten.
- pgBackRest :Det er en backup- og gendannelsesløsning til PostgreSQL.
- Patroni :Det er en High Availability-løsning til PostgreSQL.
- pg_stat_monitor :Den indsamler og samler statistik for PostgreSQL og giver histogramoplysninger.
- En samling af yderligere PostgreSQL-bidragsudvidelser.
Høj tilgængelighed på PostgreSQL
Der er forskellige arkitekturer for PostgreSQL høj tilgængelighed, men den mest almindelige er at have en Master-Slave-topologi (Primær-Standby). Den er baseret på én primær database med en eller flere standby-noder. Disse standby-databaser forbliver synkroniserede (eller næsten synkroniserede) med den primære, afhængigt af om replikeringen er synkron eller asynkron. Hvis hovedserveren fejler, indeholder standby næsten alle data fra hovedserveren og kan hurtigt omdannes til den nye primære databaseserver.
Men en master-slave-opsætning er ikke nok til effektivt at sikre høj tilgængelighed, da du også skal håndtere fejl. Når en fejl er opdaget, bør du være i stand til at vælge en standby-knude og failover til den med den mindre forsinkelse som muligt. PostgreSQL i sig selv inkluderer ikke en automatisk failover-mekanisme, så det vil kræve nogle brugerdefinerede scripts eller tredjepartsværktøjer til denne automatisering.
Efter en failover sker, skal applikationen/applikationerne underrettes i overensstemmelse hermed, så de kan begynde at bruge den nye primære node. Du skal også evaluere tilstanden af vores arkitektur efter en failover, fordi du kan køre i en situation, hvor du kun har den nye primære kørende (dvs. du havde en primær og kun én standby-knude før problemet). I så fald bliver du nødt til at tilføje en ny standby-knude på en eller anden måde for at genskabe den master-slave-opsætning, som du oprindeligt havde til High Availability.
For at få det til at fungere, skal du have forskellige værktøjer/tjenester til at hjælpe dig med denne opgave.
Load Balancers
Load balancers er værktøjer, der kan bruges til at styre trafikken fra din applikation for at få mest muligt ud af din databasearkitektur.
Det er ikke kun nyttigt til at balancere belastningen af vores databaser, det hjælper også applikationer med at blive omdirigeret til de tilgængelige/sunde noder og endda specificere porte med forskellige roller.
HAProxy er en belastningsbalancer, der distribuerer trafik fra én oprindelse til en eller flere destinationer og kan definere specifikke regler og/eller protokoller for denne opgave. Hvis en af destinationerne holder op med at svare, markeres den som offline, og trafikken sendes til resten af de tilgængelige destinationer.
Keeplived er en tjeneste, der giver dig mulighed for at konfigurere en virtuel IP inden for en aktiv/passiv gruppe af servere. Denne virtuelle IP er tildelt en aktiv server. Hvis denne server fejler, migreres IP'en automatisk til den "Sekundære" passive server, så den kan fortsætte med at arbejde med den samme IP på en gennemsigtig måde for systemerne.
For at implementere alle disse ting kan du gøre det manuelt, hvilket vil betyde ekstra arbejde og tidskrævende opgaver, eller du kan gøre det fra kun ét system ved hjælp af ClusterControl.
Lad os se, hvordan du importerer din eksisterende Percona Distribution for PostgreSQL til ClusterControl, og derefter hvordan du konfigurerer et High Availability-miljø ved hjælp af HAProxy og Keepalved omkring denne opsætning fra en venlig og brugervenlig grænseflade.
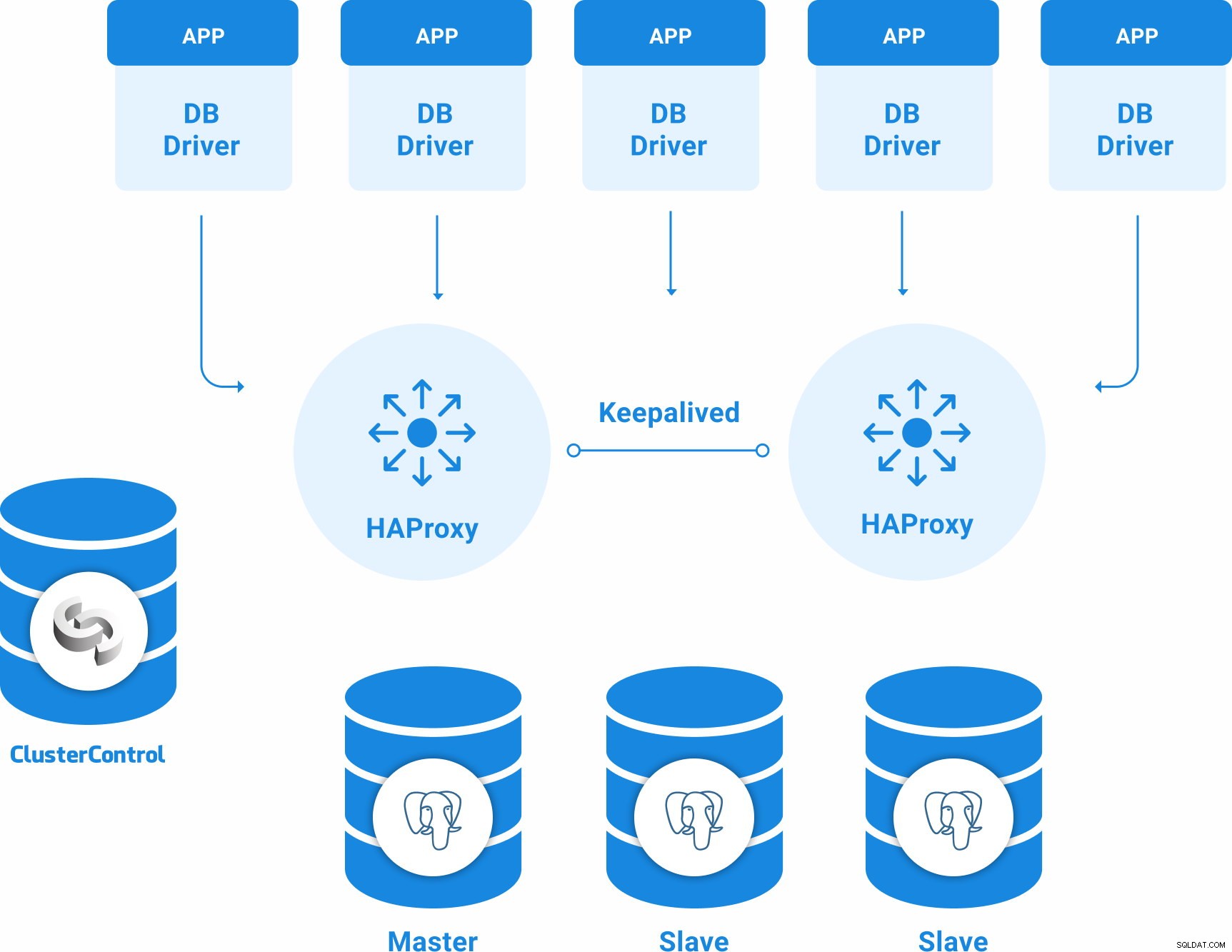
PostgreSQL-topologi for høj tilgængelighed
En grundlæggende High Availability-topologi for PostgreSQL kan være:
- 3 PostgreSQL 12-servere (en primær og to standby-knudepunkter).
- 2 HAProxy Load Balancers.
- Opretholdt konfigureret mellem load balancer-serverne.
- 1 ClusterControl-server
Du vil altså have følgende topologi:
Sådan installeres Percona Distribution til PostgreSQL
Lad os starte med at installere Percona Distribution til PostgreSQL. Til dette eksempel vil vi bruge CentOS 7 og PostgreSQL 12.
Hvis du har din klynge installeret, går du til næste afsnit for at importere din eksisterende database til ClusterControl.
Installer epel-release og percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmAktiver PostgreSQL 12-lageret
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Installer serverpakken
$ yum install percona-postgresql12-serverBemærk, at denne pakke ikke vil installere alle Percona Distribution-komponenter. For at installere disse komponenter skal du bruge de relevante valgfrie pakker som vist nedenfor:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribInitialiser databasen
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKSørg for, at du har den korrekte konfiguration for at kunne konfigurere en PostgreSQL-replikering, svarende til:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onStart derefter databasetjenesten
$ systemctl start postgresql-12Nu, hvis du vil tilføje standby-noder, skal du gentage trin 1, 2 og 3 i alle de knudepunkter, du vil tilføje til klyngen. For disse noder behøver du ikke at konfigurere andet, da ClusterControl vil oprette den tilsvarende konfiguration.
Import af Percona Distribution til PostgreSQL i ClusterControl
Med ClusterControl kan du implementere eller importere forskellige open source-databasemotorer fra det samme system, og kun SSH-adgang og en privilegeret bruger kræves for at bruge det.
Gå til afsnittet "Import" og udfyld de nødvendige oplysninger om din PostgreSQL-server.
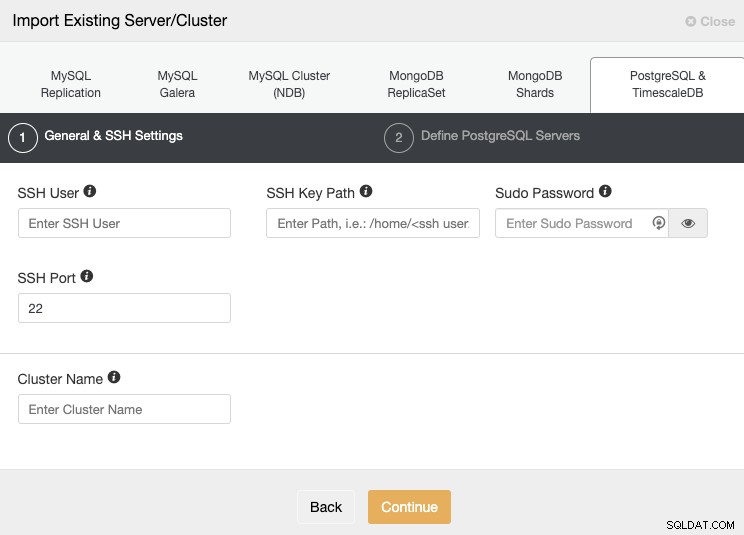
Du skal angive bruger, nøgle eller adgangskode og port for at oprette forbindelse via SSH til dine servere. Du skal også have et navn til din nye klynge, ellers vil ClusterControl tildele dig et generisk navn.
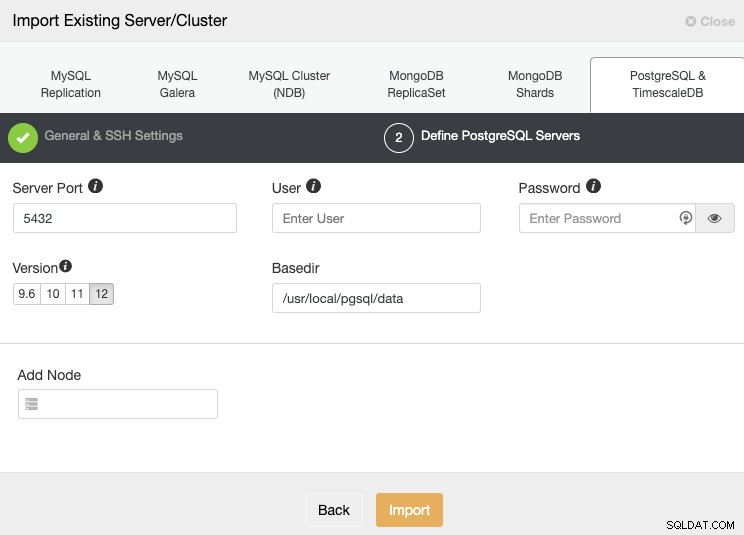
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaselegitimationsoplysningerne, version, basedir og IP-adressen eller værtsnavnet for hver databasenode.
Hvis du ikke har konfigureret replikeringen endnu, skal du blot tilføje IP-adressen eller værtsnavnet for den primære node, da vi senere vil vise dig, hvordan du tilføjer resten af noderne.
Sørg for, at du får det grønne flueben, når du indtaster værtsnavnet eller IP-adressen, hvilket indikerer, at ClusterControl er i stand til at kommunikere med noden. Klik derefter på knappen Importer og vent, indtil ClusterControl afslutter sit job. Du kan overvåge processen i ClusterControl-aktivitetssektionen. Når den er færdig, vil du se den nye klynge på ClusterControl-hovedskærmen. For at tilføje en ny replika skal du gå til klyngehandlingerne og vælge indstillingen "Tilføj replikeringsslave".
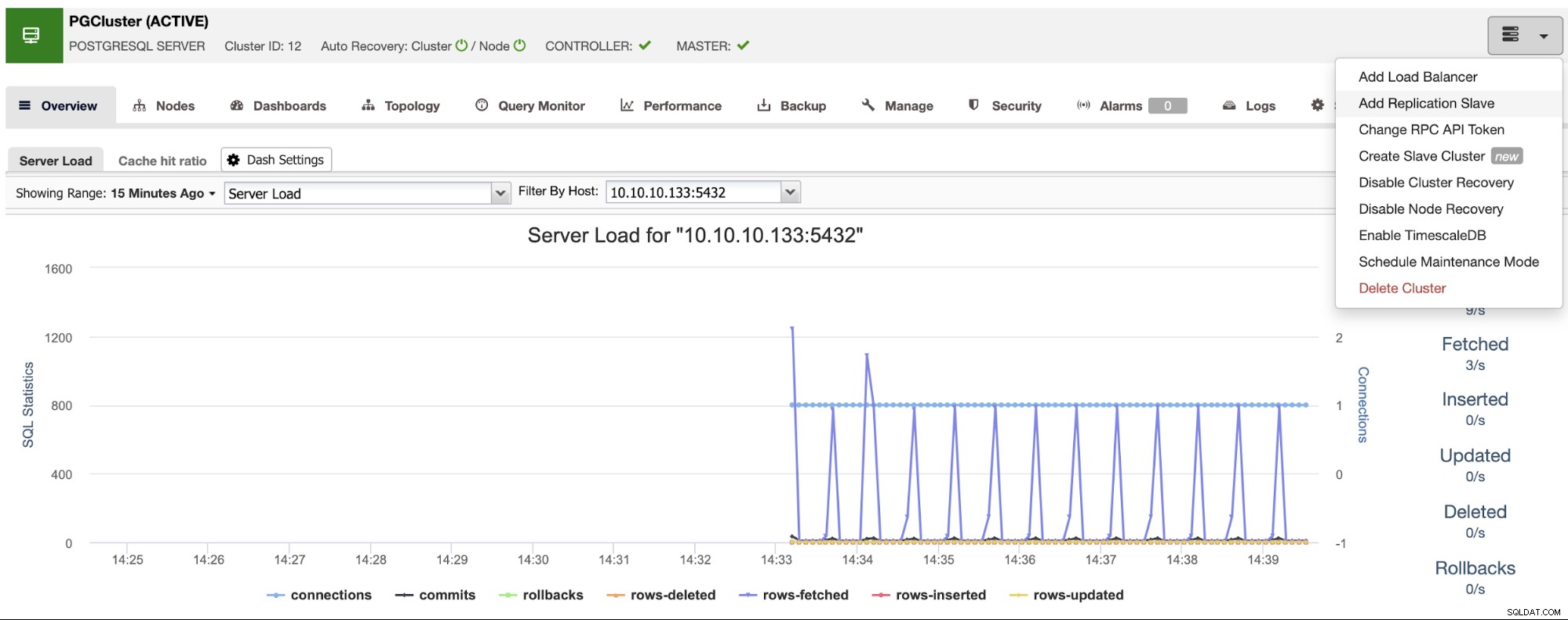
Hvis du fulgte de foregående trin, vil du have Percona Distribution for PostgreSQL installeret i alle standby-noder, så du skal deaktivere "Installer PostgreSQL-software" i dette afsnit.
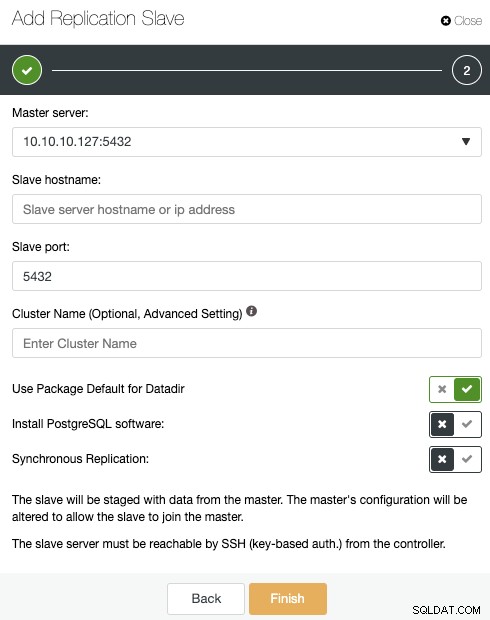
På denne måde vil ClusterControl bruge den installerede Percona Distribution til PostgreSQL-pakker i stedet for for at installere de officielle PostgreSQL-pakker.
Når du er færdig med dette, vil du se alle noderne i klyngen og status for dem alle i oversigtssektionen.
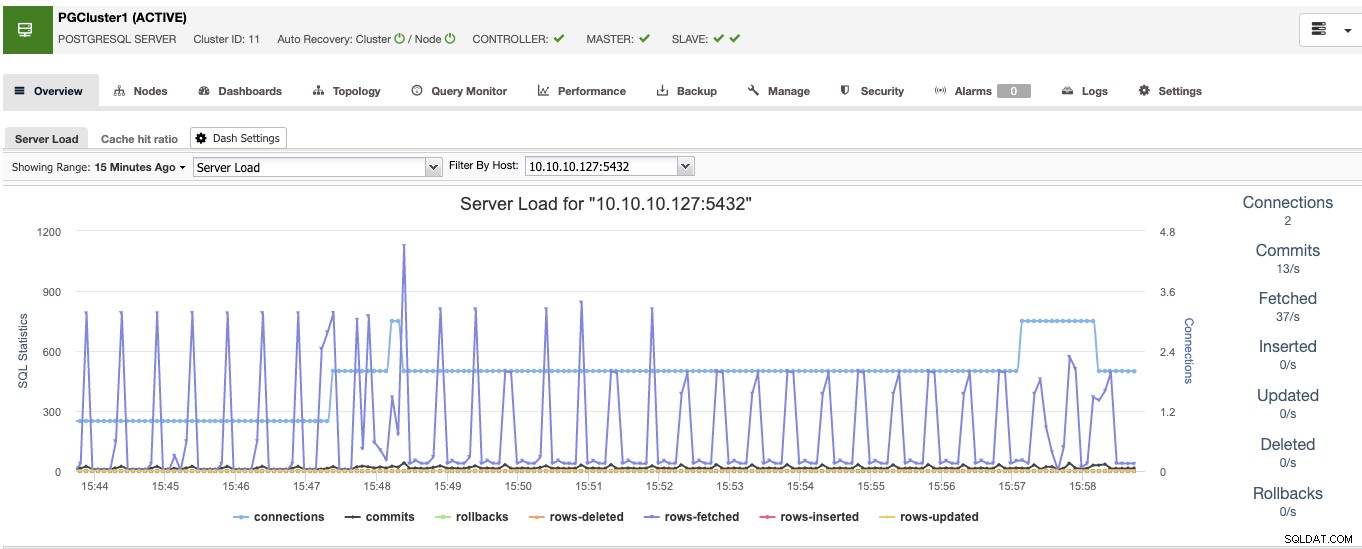
Nu har du databasesiden klar, lad os se, hvordan du fuldfører High Tilgængelighedsmiljø ved at tilføje resten af værktøjerne ved hjælp af ClusterControl.
Load Balancer-implementering
For at udføre en load balancer-implementering skal du vælge muligheden "Add Load Balancer" i klyngehandlinger og udfylde de anmodede oplysninger. 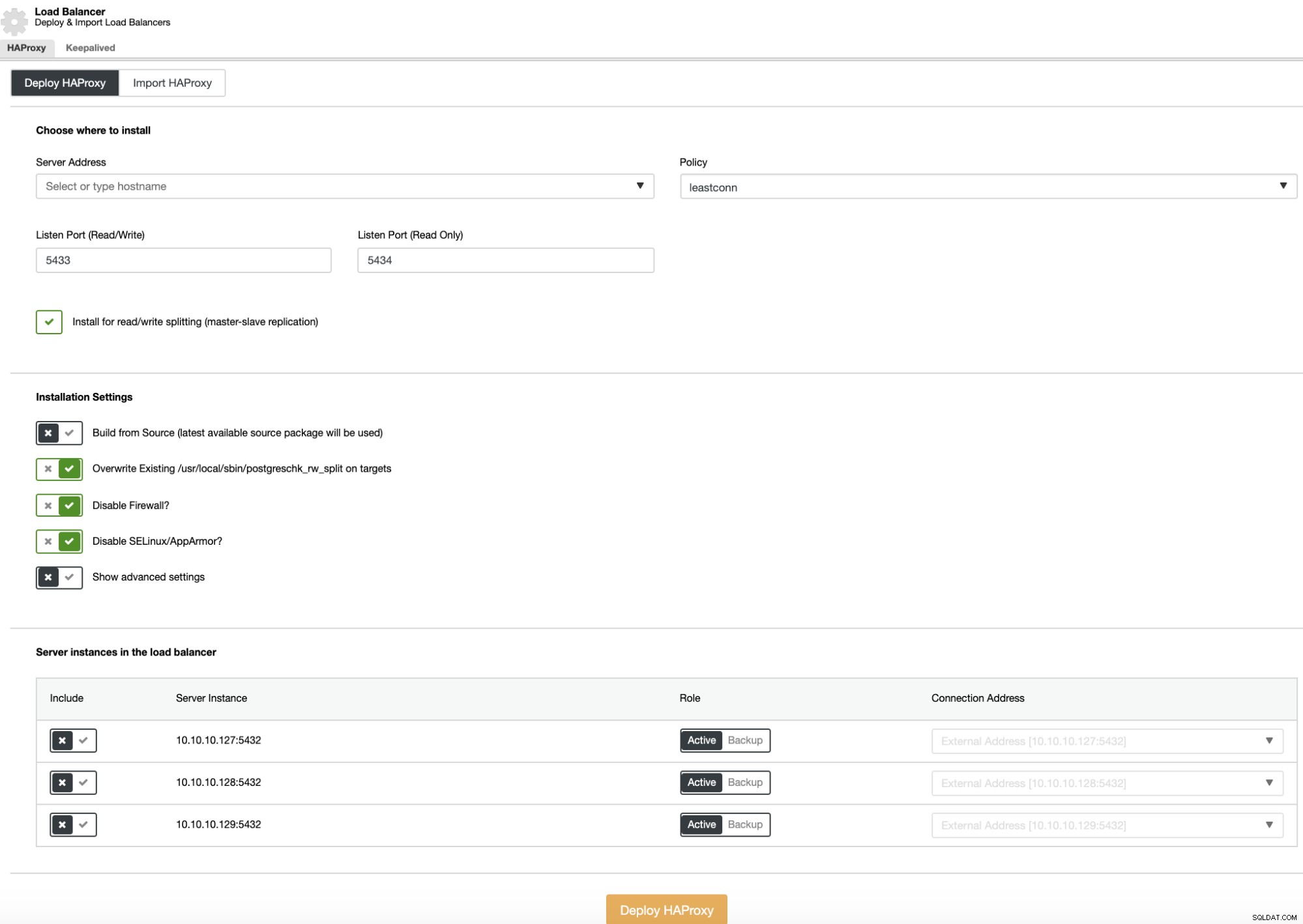
Du behøver kun at tilføje IP-adresse eller værtsnavn, port, politik og de noder, du vil tilføje til load balancer-konfigurationen.
Keelived implementering
For at udføre en Keepalived-implementering skal du vælge klyngen, gå til klyngehandlinger, vælge "Tilføj Load Balancer" og derefter gå til sektionen "Keepalived".
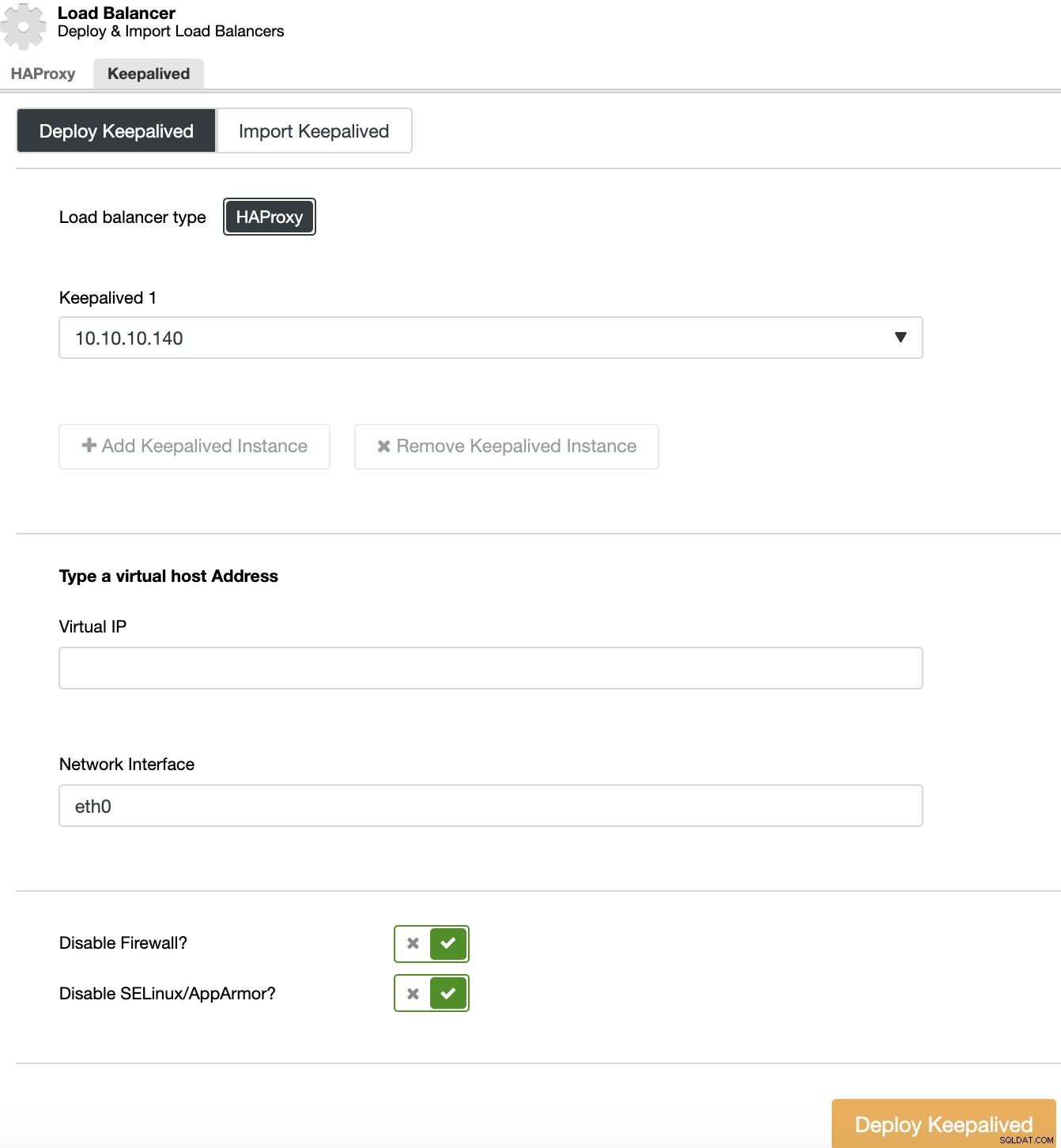
For dit High Availability-miljø skal du vælge load balancer-servere og den virtuelle IP-adresse, som du skal bruge for at få adgang til din klynge. Keepalved konfigurerer denne virtuelle IP i den aktive load balancer og migrerer den fra en load balancer til en anden i tilfælde af fejl, så din opsætning kan fortsætte med at fungere normalt.
Konklusion
Da du endnu ikke kan implementere Percona Distribution til PostgreSQL direkte fra ClusterControl, viste vi dig i denne blog, hvordan du kan administrere det ved hjælp af ClusterControl, og hvordan du tilføjer forskellige værktøjer som HAProxy og Keepalved for at have et miljø med høj tilgængelighed på plads på en nem måde.