SQL Server 2014 SP2 og senere producerer runtime ("faktiske") eksekveringsplaner, der kan omfatte forløbet tid og CPU-brug for hver udførelsesplanoperatør (se KB3170113 og dette blogindlæg af Pedro Lopes).
At tolke disse tal er ikke altid så ligetil, som man kunne forvente. Der er vigtige forskelle mellem rækketilstand og batch-tilstand udførelse, samt vanskelige problemer med rækketilstand parallelisme . SQL Server foretager nogle timing justeringer parallelle planer for at fremme sammenhæng, men de er ikke perfekt gennemført. Dette kan gøre det vanskeligt at drage konklusioner, der justerer lyden.
Denne artikel har til formål at hjælpe dig med at forstå, hvor timingen kommer fra i hvert enkelt tilfælde, og hvordan de bedst kan fortolkes i kontekst.
Opsætning
Følgende eksempler bruger det offentlige Stack Overflow 2013 database (download detaljer), med et enkelt indeks tilføjet:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Testforespørgslerne returnerer antallet af spørgsmål med et accepteret svar, grupperet efter måned og år. De køres på SQL Server 2019 CU9 , på en bærbar computer med 8 kerner og 16 GB hukommelse allokeret til SQL Server 2019-instansen. Kompatibilitetsniveau 150 bruges udelukkende.
Batch Mode seriel udførelse
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Udførelsesplanen er (klik for at forstørre):
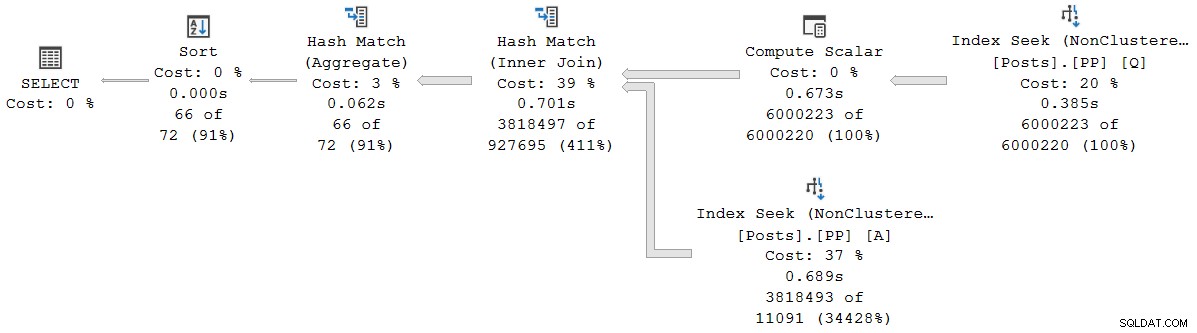
Hver operatør i denne plan kører i batch-tilstand, takket være batch-tilstanden på rowstore Intelligent Query Processing-funktion i SQL Server 2019 (intet kolonnelagerindeks påkrævet). Forespørgslen kører i 2.523 ms med 2.522 ms brugt CPU-tid, når alle nødvendige data allerede er i bufferpuljen.
Som Pedro Lopes bemærker i det tidligere linkede blogindlæg, rapporterede de forløbne tider og CPU-tider for individuel batch-tilstand operatører repræsenterer den tid, der bruges af denne operatør alene .
SSMS viser forløbet tid i den grafiske fremstilling. For at se CPU-tiderne , vælg en planoperatør, og kig derefter i Egenskaber vindue. Denne detaljerede visning viser både forløbet tid og CPU-tid pr. operatør og pr. tråd.
Showplan-tiderne (inklusive XML-repræsentationen) er trunkeret til millisekunder. Hvis du har brug for større præcision, skal du bruge query_thread_profile udvidet hændelse, som rapporterer om mikrosekunder . Outputtet fra denne hændelse for udførelsesplanen vist ovenfor er:
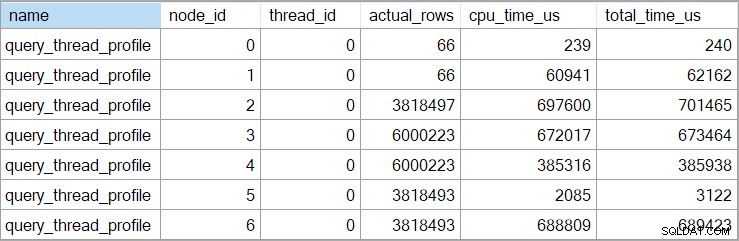
Dette viser den forløbne tid for sammenføjningen (node 2) er 701.465 µs (trunkeret til 701 ms i showplan). Aggregatet har en forløbet tid på 62.162 µs (62 ms). "Spørgsmål"-indekssøgningen vises som kørende i 385 ms, mens den udvidede hændelse viser, at det sande tal for node 4 var 385.938 µs (meget næsten 386 ms).
SQL Server bruger høj præcision QueryPerformanceCounter API til at fange tidsdata. Dette bruger hardware, typisk en krystaloscillator, der producerer tikker med en meget høj konstant hastighed uanset processorhastighed, strømindstillinger eller noget af den art. Uret fortsætter med at køre med samme hastighed, selv under søvn. Se den linkede meget detaljerede artikel, hvis du er interesseret i alle de finere detaljer. Den korte oversigt er, at du kan stole på, at mikrosekundtallene er nøjagtige.
I denne rene batch-mode plan er den samlede udførelsestid meget tæt på summen af de enkelte operatørs forløbne tider. Forskellen skyldes i høj grad arbejde efter erklæringen, der ikke er forbundet med planoperatører (som alle er lukket på det tidspunkt), selvom afkortningen af millisekunder også spiller en rolle.
I rene batch-tilstandsplaner skal du manuelt summere aktuelle og underordnede operatørtider for at opnå den kumulative forløbet tid ved en given node.
Batch Mode Parallel Execution
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Udførelsesplanen er:
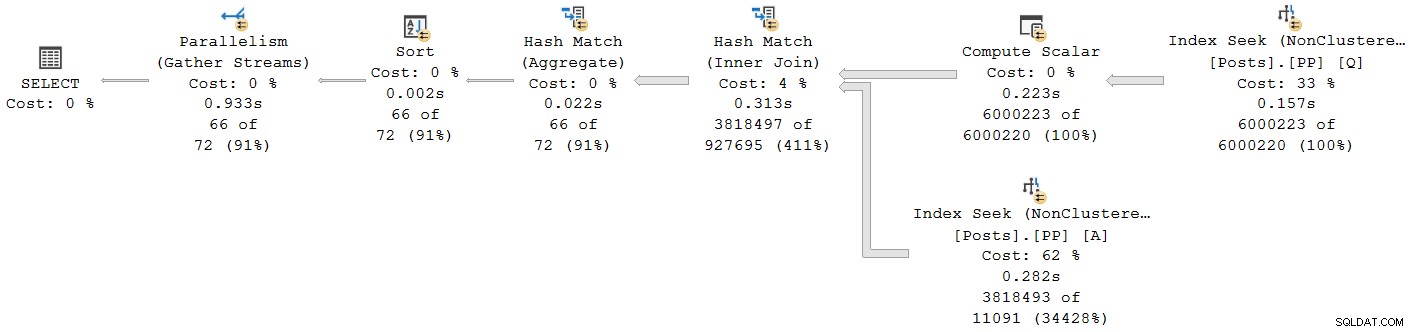
Hver operatør undtagen den endelige samlestrømudveksling kører i batch-tilstand. Samlet forløbet tid er 933ms med 6.673 ms CPU-tid med en varm cache.
Vælger hash-joint og ser i SSMS Egenskaber vindue, ser vi forløbet og CPU-tid pr. tråd for den pågældende operatør:
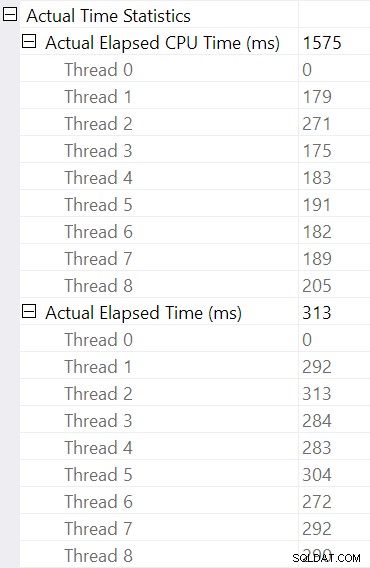
CPU-tiden rapporteret for operatøren er sum af de enkelte tråds CPU-tider. Den rapporterede operatør forløbet tid er maksimum af de forløbne tider pr. tråd. Begge beregninger udføres over de trunkerede millisekundværdier pr. tråd. Som før er den samlede udførelsestid meget tæt på summen af individuelle operatørs forløbne tider.
Parallelle planer i batchtilstand bruger ikke udvekslinger til at fordele arbejde mellem tråde. Batch-operatører er implementeret, så flere tråde kan arbejde effektivt på en enkelt delt struktur (f.eks. hash-tabel). Nogle synkronisering mellem tråde er stadig påkrævet i batch-mode parallelle planer, men synkroniseringspunkter og andre detaljer er ikke synlige i showplan output.
Rækketilstand seriel udførelse
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Udførelsesplanen er visuelt den samme som serieplanen for batchtilstand, men hver operatør kører nu i rækketilstand:
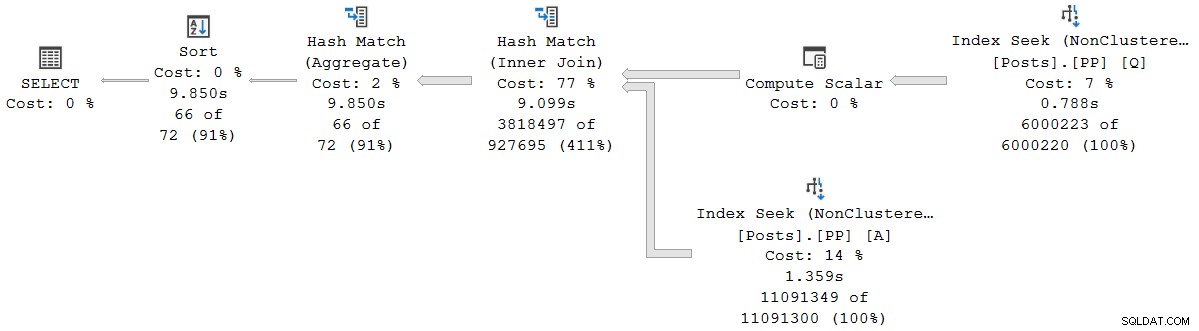
Forespørgslen kører 9.850 ms med 9.845ms CPU-tid. Dette er meget langsommere end den serielle batch-mode-forespørgsel (2523ms/2522ms), som forventet. Endnu vigtigere for den nuværende diskussion, rækketilstanden forløbet operatør og CPU-tider repræsenterer den tid, der bruges af den nuværende operatør og alle dens børn .
Den udvidede hændelse viser også kumulativ CPU og forløbne tider ved hver node (i mikrosekunder):
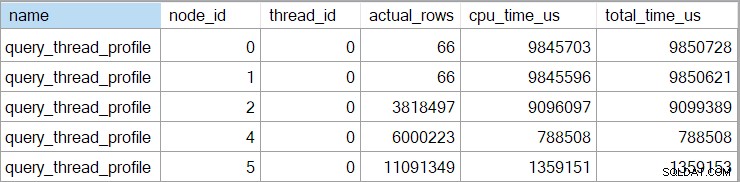
Der er ingen data for beregningsskalaroperatoren (node 3), fordi udførelse af rækketilstand kan udskyde de fleste udtryksberegninger til den operator, der bruger resultatet. Dette er i øjeblikket ikke implementeret til batch-tilstand.
Den rapporterede kumulative forløbet tid for rækketilstandsoperatorer betyder, at den viste tid for den endelige sorteringsoperator stemmer nøje overens med den samlede udførelsestid for forespørgslen (ihvertfald til millisekunders opløsning). Den forløbne tid for hash-joint inkluderer ligeledes bidrag fra de to indekssøgninger under den, såvel som dens egen tid. For at beregne den forløbne tid for rækketilstandens hash join alene, skal vi trække begge søgetider fra den.
Der er fordele og ulemper ved begge præsentationer (kumulativ for rækketilstand, individuel operatør kun for batchtilstand). Uanset hvad du foretrækker, er det vigtigt at være opmærksom på forskellene.
Planer for blandet udførelsestilstand
Generelt kan moderne udførelsesplaner indeholde enhver blanding af rækketilstands- og batchtilstandsoperatører. Batch mode operatørerne vil rapportere tidspunkter kun for sig selv. Rækketilstandsoperatørerne vil inkludere en kumulativ total op til det tidspunkt i planen, inklusive alle børneoperatører. For at være klar over det:En rækketilstandsoperatørs kumulative tider inkluderer enhver batch-tilstand underordnede operatører.
Vi så dette tidligere i planen for parallel batchtilstand:Den endelige (rækketilstand) samlestrømsoperatør havde en vist (kumulativ) forløbet tid på 0,933 s - inklusive alle dens underordnede batchtilstandsoperatører. De andre operatører var alle batch-mode, og derfor rapporterede tidspunkter for den enkelte operatør alene.
Denne situation, hvor nogle planoperatører i samme plan har kumulative tider og andre ikke, vil uden tvivl blive betragtet som forvirrende af mange mennesker.
Rækketilstand Parallel udførelse
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Udførelsesplanen er:

Hver operatør er i rækketilstand. Forespørgslen kører 4.677 ms med 23.311ms CPU-tid (summen af alle tråde).
Som en eksklusiv rækketilstandsplan forventer vi, at alle tider er kumulative . Når man går fra barn til forælder (højre til venstre), burde tiden stige i den retning.
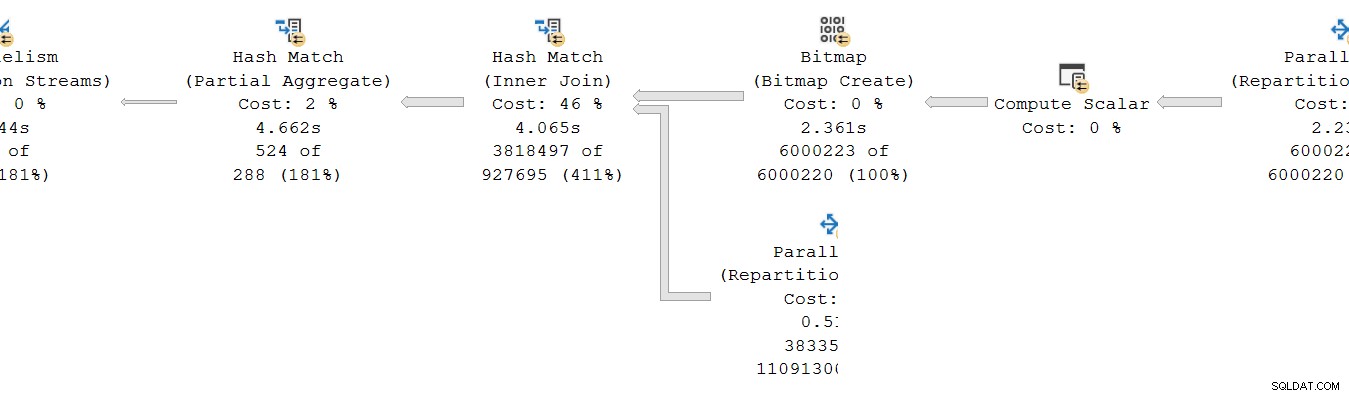
Lad os se på den sektion længst til højre i planen:
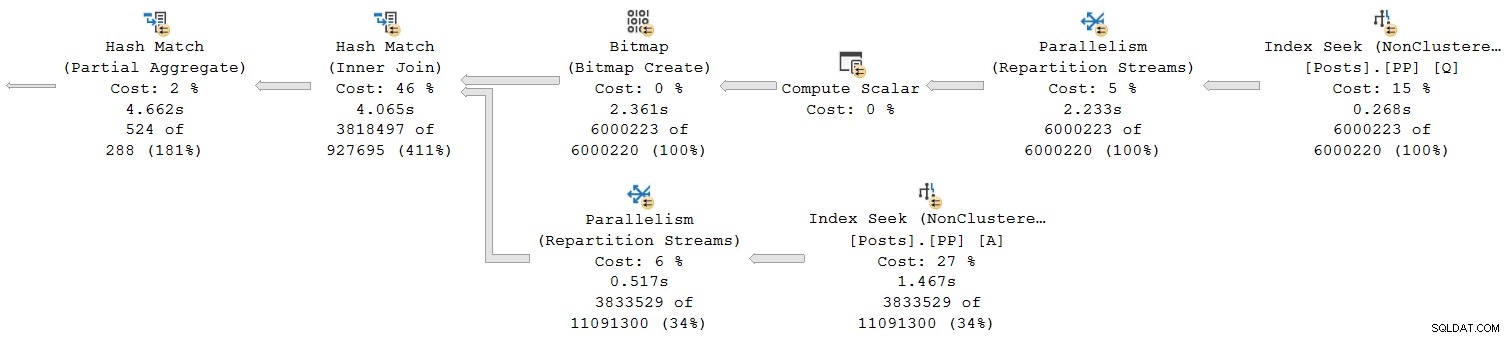
Arbejder fra højre mod venstre på den øverste række, ser kumulative tider bestemt ud til at være tilfældet. Men der er en undtagelse på det nederste input til hash join:Indekssøgningen har en forløbet tid på 1.467s , mens dens forælder genopdelingsstreams har en forløbet tid på kun 0,517s .
Hvordan kan en forælder operatør køre i kortere tid end dets barn hvis forløbne tider er kumulative i rækketilstandsplaner?
Inkonsistente tider
Der er flere dele af svaret på dette puslespil. Lad os tage det stykke for stykke, for det er ret komplekst:
Husk først, at en udveksling (parallelismeoperatør) har to dele. Den venstre hånd (forbruger ) side er forbundet til et sæt tråde, der kører operatører i den parallelle gren til venstre. Højre hånd (producer ) side af centralen er forbundet til et andet sæt tråde, der kører operatører i den parallelle gren til højre.
Rækker fra producentsiden samles i pakker og derefter overført til forbrugersiden. Dette giver en grad af buffring og flowkontrol mellem de to sæt forbundne tråde. (Hvis du har brug for en genopfriskning af udvekslinger og parallelle plangrene, så se venligst min artikel Parallelle eksekveringsplaner – grene og tråde.)
Omfanget af kumulative tider
Ser man på parallelgrenen på producenten side af udvekslingen:
Som sædvanlig kører DOP (grad af parallelisme) yderligere arbejdertråde en uafhængig serie kopi af planoperatørerne i denne filial. Så ved DOP 8 er der 8 uafhængige serielle indekssøgninger, der samarbejder om at udføre rækkeviddescanningsdelen af den overordnede (parallelle) indekssøgningsoperation. Hver enkelt-trådede søgning er forbundet til en anden input (port) på producentsiden af den single shared udvekslingsoperatør.
En lignende situation eksisterer for forbrugeren side af udvekslingen. På DOP 8 er der 8 separate enkelttrådede kopier af denne gren, der alle kører uafhængigt:
Hver af disse enkelttrådede underplaner kører på den sædvanlige måde, hvor hver operatør akkumulerer forløbet og CPU-tid i hver node. Som rækketilstandsoperatorer repræsenterer hver total tid brugt den kumulative total for den aktuelle node og hver af dens børn.
Det afgørende er, at de kumulative totaler inkluder kun operatorer på samme tråd og kun inden for den nuværende gren . Forhåbentlig giver dette intuitiv mening, for hver tråd har ingen idé om, hvad der kan foregå andre steder.
Sådan indsamles rækketilstandsmetrics
Den anden del af puslespillet vedrører den måde, hvorpå rækkeantal og timing-metrikker indsamles i rækketilstandsplaner. Når runtime ("faktisk") planoplysninger er påkrævet, tilføjer eksekveringsmotoren en usynlig profileringsoperatør til umiddelbart venstre (forælder) for hver operatør i planen, der vil blive udført under kørsel.
Denne operatør kan (blandt andet) registrere forskellen mellem det tidspunkt, hvor det overdrog kontrollen til sin underordnede operatør, og det tidspunkt, hvor kontrollen blev returneret. Denne tidsforskel repræsenterer den forløbne tid for den overvågede operatør og alle dens børn , da barnet kalder ind på sit eget barn pr. række og så videre. En operatør kan kaldes mange gange (for at initialisere, derefter én gang pr. række, til sidst for at lukke), så den tid, der indsamles af profileringsoperatøren, er en akkumulering over potentielt mange gentagelser pr. række.
For flere detaljer om profileringsdata indsamlet ved hjælp af forskellige opsamlingsmetoder, se produktdokumentationen, der dækker infrastrukturen for forespørgselsprofilering. For dem, der er interesseret i sådanne ting, er navnet på den usynlige profileringsoperatør, der bruges af standardinfrastrukturen sqlmin!CQScanProfileNew . Som alle rækketilstands-iteratorer har den Open , GetRow og Close metoder blandt andet. Hver metode indeholder kald til Windows QueryPerformanceCounter API til at indsamle den aktuelle timerværdi med høj opløsning.
Da profileringsoperatøren er til venstre måloperatøren måler kun forbrugeren side af udvekslingen. Der er ingen profileringsoperatør for producenten side af udvekslingen (desværre). Hvis der var det, ville det matche eller overskride den forløbne tid vist på indekssøgningen, fordi indekssøgningen og producentsiden kører det samme sæt tråde, og producentsiden af børsen er moderoperatøren for indekssøgningen.
Timing genbesøgt

Med alt det sagt, kan du stadig have problemer med timingen vist ovenfor. Hvordan kan en indekssøgning tage 1.467s at sende rækker til producentsiden af en børs, men forbrugersiden tager kun 0,517 sek. at modtage dem? Uanset separate tråde, buffering og andet, sikkert bør udvekslingen køre (ende-til-ende) længere end søgningen gør?
Nå, ja det gør det, men det er en anden måling fra forløbet eller CPU-tid. Lad os være præcise om, hvad vi måler her.
For rækketilstand forløbet tid , forestil dig et stopur pr. tråd hos hver enkelt operatør. Stopuret starter når SQL Server indtaster koden for en operatør fra dens forælder og stopper (men nulstilles ikke), når denne kode forlader operatøren for at returnere kontrollen til forælderen (ikke til et barn). Forløbet tid inkluderer eventuelle ventetider eller planlægningsforsinkelser – ingen af dem stopper vagten.
Til rækketilstand CPU-tid , forestil dig det samme stopur med de samme egenskaber, bortset fra at det stopper under ventetider og planlægningsforsinkelser. Det akkumulerer kun tid, når operatøren eller en af dens børn aktivt udfører på en skemalægger (CPU). Den samlede tid på et stopur pr. tråd pr. operatør er bygget op af en start-stop-cyklus for hver række.
Lad os anvende det på den aktuelle situation med forbrugersiden af børsen og indekssøgningen:
Husk, at forbrugersiden af børsen og indekssøgningen er i separate afdelinger, så de kører på separate tråde . Forbrugersiden har ingen børn i samme tråd. Indekssøgningen har producentsiden af børsen som sin samme-trådsforælder, men vi har ikke et stopur der.
Hver forbrugertråd starter sit ur, når dens overordnede operatør (sondesiden af hash-forbindelsen) passerer kontrol (f.eks. for at hente en række). Uret bliver ved med at køre, mens forbrugeren henter en række fra den aktuelle byttepakke. Uret stopper når kontrollen forlader forbrugeren og vender tilbage til hash join-sondesiden. Yderligere forældre (det delvise aggregat og dets overordnede børs) vil også arbejde på den række (og kan vente), før kontrollen vender tilbage til forbrugersiden af vores børs for at hente den næste række. På det tidspunkt begynder forbrugersiden af vores udveksling at akkumulere forløbet og CPU-tid igen.
I mellemtiden, uafhængigt af hvad forbrugerens sidegrentråde måtte gøre, indekssøgningen tråde fortsætter med at lokalisere rækker i indekset og føre dem ind i udvekslingen. En indekssøgningstråd starter sit stopur, når producentsiden af børsen beder den om en række. Stopuret sættes på pause, når rækken sendes til centralen. Når børsen beder om den næste række, genoptages stopuret for indekssøgning.
Bemærk, at producentsiden af børsen kan opleve CXPACKET venter, mens udvekslingsbufferne fyldes op, men det vil ikke føje til de forløbne tider, der er registreret ved indekssøgningen, fordi dets stopur ikke kører, når det sker. Hvis vi havde et stopur til producentsiden af børsen, ville den manglende forløbne tid dukke op der.
For at tilnærme en oversigt over situationen visuelt viser følgende diagram, hvornår hver operatør akkumulerer forløbet tid i de to parallelle grene:
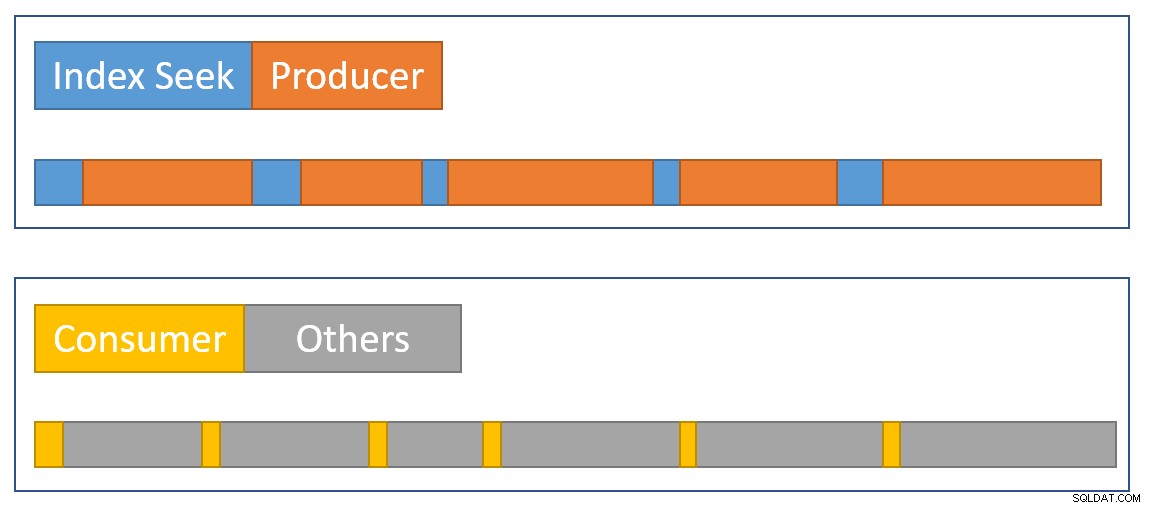
Den blå indekssøgningstidslinjer er korte, fordi det er hurtigt at hente en række fra et indeks. Den orange producenttiderne kan være lange på grund af CXPACKET venter. Den gule forbrugertiderne er korte, fordi det er hurtigt at hente en række fra børsen, når data er tilgængelige. Den grå tidssegmenter repræsenterer tid brugt af de andre operatører (hash join-sondeside, delvist aggregat og dens overordnede børsproducentside) over forbrugersiden af børsen.
Vi forventer, at udvekslingspakkerne fyldes hurtigt ved indekssøgningen, men tømmes langsomt (relativt set) af operatørerne på forbrugersiden, fordi de har mere arbejde at gøre. Det betyder, at pakker i udvekslingen normalt vil være fyldte eller tæt på fulde. Forbrugeren vil hurtigt kunne hente en ventende række, men producenten skal muligvis vente på, at pakkeplads vises.
Det er en skam, at vi ikke kan se forløbne tider på producentsiden af børsen. Jeg har længe været af den opfattelse, at en udveksling burde være repræsenteret af to forskellige operatører i udførelsesplaner. Det ville gøre CXPACKET svært /CXCONSUMER venteanalyse langt mindre nødvendigt, og udførelsesplaner meget lettere at forstå. Børsproducentens operatør ville naturligvis få sin egen profileringsoperatør.
Alternative designs
Der er mange måder, hvorpå SQL Server kan opnå ensartet kumulativ forløbet og CPU-tid på tværs af parallelle grene i princippet . I stedet for at profilere operatører kunne hver række indeholde information om, hvor meget forløbet og CPU-tid den havde optjent indtil videre på sin rejse gennem planen. Med historie forbundet med hver række, ville det ikke være ligegyldigt, hvordan udvekslinger omfordelte rækker mellem tråde og så videre.
Det er ikke sådan produktet er designet, så det er ikke det, vi har (og det kan være ineffektivt alligevel). For at være retfærdig handlede det oprindelige rækketilstandsdesign kun om ting som at indsamle faktiske rækkeantal og antallet af iterationer hos hver operatør. Tilføjelse af forløbet tid pr. operatør til planer var en meget efterspurgt funktion , men det var ikke nemt at inkorporere i de eksisterende rammer.
Når batch-mode-behandling blev tilføjet til produktet, kunne en anden tilgang (kun timing for den nuværende operatør) implementeres som en del af den oprindelige udvikling uden at bryde noget. Igen, i princippet , kunne rækketilstandsoperatører være blevet ændret til at fungere på samme måde som batchtilstandsoperatører, men det ville have krævet en hel del arbejde med at omstrukturere hver eksisterende rækketilstandsoperatør. Det var meget nemmere at tilføje et nyt datapunkt til de eksisterende profileringsoperatører i rækketilstand. På grund af begrænsede tekniske ressourcer og en lang liste af ønskede produktforbedringer, skal kompromiser som dette ofte indgås.
Det andet problem
En anden kumulativ timing-inkonsistens forekommer i den nuværende plan på venstre side:

Ved første øjekast ser det ud til at være det samme problem:Det delvise aggregat har en forløbet tid på 4.662s , men udvekslingen over den kører kun i 2.844s . Den samme grundlæggende mekanik som før er selvfølgelig i spil, men der er en anden vigtig faktor. Et fingerpeg ligger i de mistænkeligt lige gange rapporteret for strømaggregat-, sorterings- og ompartitioneringsudvekslingen.
Husker du de "timingjusteringer", jeg nævnte i indledningen? Det er her, de kommer ind. Lad os se på de individuelle forløbne tider for tråde på forbrugersiden af udvekslingen af omfordelingsstrømme:
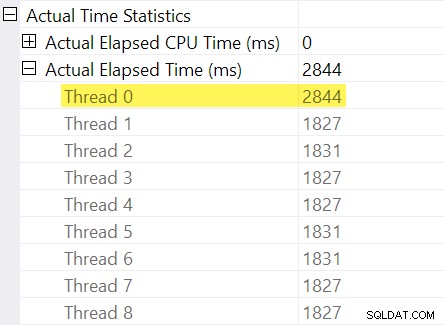
Husk, at planer viser den forløbne tid for en paralleloperatør som maksimum af gange per tråd. Alle 8 tråde havde en forløbet tid omkring 1.830 ms, men der er en ekstra post for "Tråd 0" med 2.844 ms. Faktisk alle operatører i denne parallelle gren (børsforbrugeren, sorteringen og strømaggregatet) har samme 2.844 ms bidrag fra "Tråd 0".
Tråd nul (alias overordnet opgave eller koordinator) kører kun operatører direkte til venstre for den endelige samlestrømsoperatør. Hvorfor er der tildelt arbejde her, i en parallel gren?
Forklaring
Dette problem kan opstå, når der er en blokerende operatør i parallelgrenen nedenunder (til højre for) den nuværende. Uden denne justering ville operatører i den nuværende filial underrapportere forløbet tid med den tid, det tager at åbne den underordnede filial (der er komplicerede arkitektoniske årsager til dette).
SQL Server ser ud til at tage højde for dette ved at registrere den underordnede grenforsinkelse på centralen i den usynlige profileringsoperator. Tidsværdien registreres mod overordnet opgave ("Tråd 0") i forskellen mellem dens første aktive og sidst aktive gange. (Det kan virke mærkeligt at registrere nummeret på denne måde, men på det tidspunkt, hvor nummeret skal registreres, er de yderligere parallelle arbejdertråde ikke blevet oprettet endnu).
I det aktuelle tilfælde er 2.844ms-justeringen opstår overvejende på grund af den tid, det tager hash-joinet at bygge sin hash-tabel. (Bemærk, at denne tid er forskellig fra den totale eksekveringstid for hash-join, som inkluderer den tid, det tager at behandle probesiden af joinforbindelsen).
Behovet for en justering opstår, fordi en hash-join blokerer for dens build-input. (Interessant nok er hashen delvis aggregat i planen betragtes ikke som blokerende i denne sammenhæng, fordi den kun er tildelt en minimal mængde hukommelse, spilder aldrig til tempdb , og stopper simpelthen med at aggregere, hvis den løber tør for hukommelse (og derved vender tilbage til en streamingtilstand). Craig Freedman forklarer dette i sit indlæg, Partial Aggregation).
Eftersom den forløbne tidsjustering repræsenterer en initialiseringsforsinkelse i den underordnede gren, burde SQL Server at behandle "Tråd 0"-værdien som en offset for de målte tal for forløbet tid pr. tråd inden for den aktuelle gren. Tager maksimum af alle tråde, da den forløbne tid generelt er rimelig, fordi tråde har en tendens til at starte på samme tid. Det gør den ikke giver mening at gøre dette, når en af trådværdierne er en offset for alle de andre værdier!
Vi kan lave den korrekte offsetberegning manuelt ved hjælp af de tilgængelige data i planen. På forbrugersiden af børsen har vi:
Den maksimale forløbne tid blandt de ekstra arbejdertråde er 1.831 ms (eksklusive offsetværdien gemt i "Tråd 0"). Tilføjelse af offset på 2.844ms giver i alt 4.675ms .
I enhver plan, hvor tiderne pr. tråd er mindre end offset, vil operatøren forkert vis offset som den samlede forløbne tid. Dette vil sandsynligvis ske, når den tidligere blokerende operatør er langsom (måske et slags eller globalt aggregat over et stort sæt data), og de senere filialoperatører er mindre tidskrævende.
Gensyn med denne del af planen:
Udskiftning af forskydningen på 2.844 ms, der fejlagtigt er tildelt omopdelingsstrømmene, sorterings- og strømaggregatoperatorerne med vores beregnede 4.675 ms værdi placerer deres kumulative forløbne tider pænt mellem de 4.662 ms ved den delvise samlede og 4.676 ms ved de sidste samlestrømme. (Sorteringen og aggregatet fungerer på et lille antal rækker, så deres forløbne tidsberegninger kommer ud på samme måde som sorteringen, men generelt ville de ofte være anderledes):

Alle operatører i planfragmentet ovenfor har 0 ms forløbet CPU-tid på tværs af alle tråde (bortset fra det delvise aggregat, som har 14.891 ms). Planen med vores beregnede tal giver derfor meget mere mening end den viste:
- 4.675 ms – 4.662 ms =13 ms forløbet er et meget mere rimeligt tal for den tid, der forbruges af omfordelingsstrømmene alene . Denne operatør bruger ingen CPU-tid og behandler kun 524 rækker.
- 0ms forløbet (til millisekund opløsning) er rimeligt for den lille sortering og strømaggregat (igen, ekskluderer deres børn).
- 4.676 ms – 4.675 ms =1 ms synes godt for de endelige indsamlingsstrømme at samle 66 rækker på den overordnede opgavetråd for retur til klienten.
Bortset fra den åbenlyse uoverensstemmelse i den givne plan mellem de delvise samlede (4.662 ms) og opdelingsstrømme (2.844 ms), er det urimeligt at tro, at de endelige samlestrømme på 66 rækker kan være ansvarlige for 4.676 ms – 2.844 ms = 1.832 ms af forløbet tid. Det korrigerede tal (1ms) er meget mere nøjagtigt og vil ikke vildlede forespørgselstunere.
Nu, selvom denne forskydningsberegning blev udført korrekt, kan parallelle rækketilstandsplaner ikke viser konsistente kumulative tider i alle tilfælde af de tidligere nævnte årsager. At opnå fuldstændig sammenhæng kan være vanskeligt eller endda umuligt uden større arkitektoniske ændringer.
For at forudse et spørgsmål, der kan opstå på dette tidspunkt:Nej, den tidligere børs- og indekssøgningsanalyse involverede ikke en "Thread 0" offset-beregningsfejl. Der er ingen blokerende operatør under denne central, så der opstår ingen initialiseringsforsinkelse.
Et sidste eksempel
Dette næste eksempelforespørgsel bruger samme database og indeks som før. Jeg vil ikke udforske det for meget detaljeret, fordi det kun tjener til at uddybe punkter, jeg allerede har gjort, for den interesserede læser.
Funktionerne i denne demo er:
- Uden en
ORDER GROUPtip, det viser, hvordan et delvist aggregat ikke betragtes som en blokerende operatør, så der ikke opstår nogen "Tråd 0"-justering ved udvekslingen af ompartitionsstrømme. De forløbne tider er konsistente. - Med tippet introduceres blokeringssorteringer i stedet for et delvist hashaggregat. To forskellige "Tråd 0"-justeringer vises på de to ompartitioneringsudvekslinger. Forløbne tider er inkonsistente på begge grene, på forskellige måder.
Forespørgsel:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Udførelsesplan uden ORDER GROUP (ingen justering, konsekvente tider):

Udførelsesplan med ORDER GROUP (to forskellige justeringer, inkonsistente tidspunkter):

Sammendrag og konklusioner
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.