De fleste OLTP-arbejdsbelastninger involverer tilfældig disk I/O-brug. Ved at vide, at diske (inklusive SSD) er langsommere i ydeevne end at bruge RAM, bruger databasesystemer caching til at øge ydeevnen. Caching handler om at gemme data i hukommelsen (RAM) for hurtigere adgang på et senere tidspunkt.
PostgreSQL bruger også caching af sine data i et rum kaldet shared_buffers. I denne blog vil vi udforske denne funktionalitet for at hjælpe dig med at øge ydeevnen.
Grundlæggende om PostgreSQL-cache
Før vi dykker dybere ned i begrebet caching, lad os få en opfriskning af det grundlæggende.
I PostgreSQL er data organiseret i form af sider af størrelse 8KB, og hver sådan side kan indeholde flere tuples (afhængigt af størrelsen på tuple). En forenklet repræsentation kunne være som nedenfor:
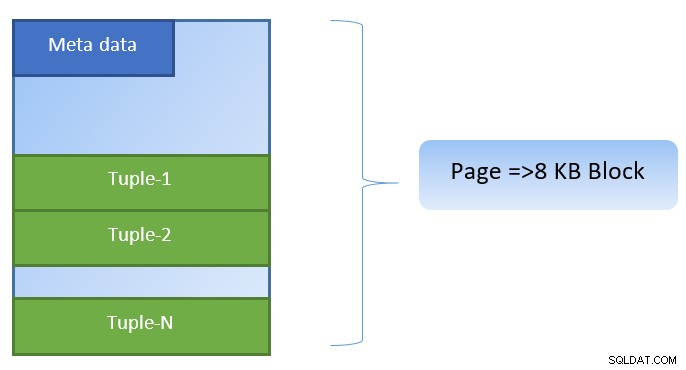
PostgreSQL cacherer følgende for at fremskynde dataadgang:
- Data i tabeller
- Indekser
- Forespørgselsudførelsesplaner
Mens caching af forespørgselsudførelsesplanen fokuserer på at gemme CPU-cyklusser; caching for tabeldata og indeksdata er fokuseret for at spare kostbar disk I/O-drift.
PostgreSQL lader brugere definere, hvor meget hukommelse de vil reservere til at opbevare en sådan cache til data. Den relevante indstilling er shared_buffers i postgresql.conf-konfigurationsfilen. Den endelige værdi af shared_buffers definerer, hvor mange sider der kan cachelagres på ethvert tidspunkt.
Når en forespørgsel udføres, søger PostgreSQL efter siden på disken, som indeholder den relevante tuple, og skubber den i shared_buffers-cachen for lateral adgang. Næste gang den samme tuple (eller en hvilken som helst tuple på samme side) skal tilgås, kan PostgreSQL gemme disk IO ved at læse den i hukommelsen.
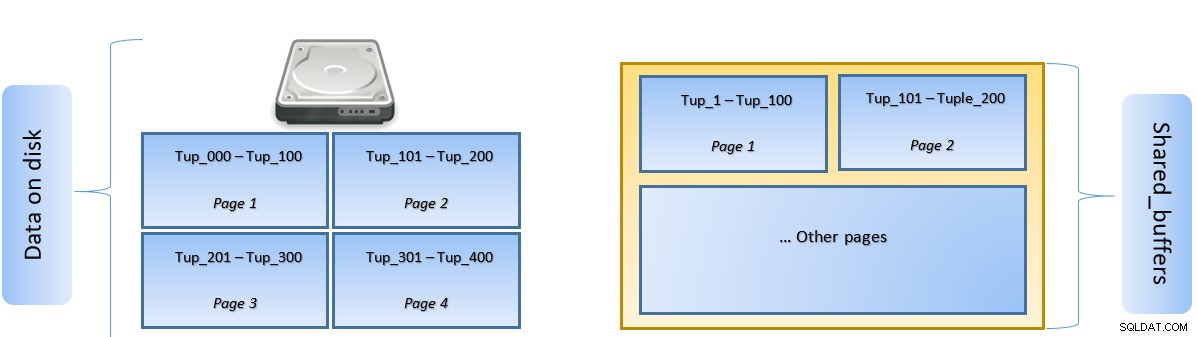
I ovenstående figur, Side-1 og Side-2 af en bestemt tabellen er blevet cachelagret. Hvis en brugerforespørgsel skal have adgang til tuples mellem Tuple-1 til Tuple-200, kan PostgreSQL selv hente den fra RAM.
Men hvis forespørgslen skal have adgang til Tuples 250 til 350, skal den udføre disk I/O for side 3 og side 4. Enhver yderligere adgang til Tuple 201 til 400 vil blive hentet fra cachen og disk I/O vil ikke være nødvendig – hvilket gør forespørgslen hurtigere.
På et højt niveau følger PostgreSQL LRU (senest brugt) algoritme for at identificere de sider, der skal fjernes fra cachen. Med andre ord, en side, der kun er tilgået én gang, har større chancer for udsættelse (sammenlignet med en side, der tilgås flere gange), i tilfælde af at en ny side skal hentes af PostgreSQL til cachen.
PostgreSQL-cache i aktion
Lad os udføre et eksempel og se effekten af cache på ydeevnen.
Start PostgreSQL og hold shared_buffer indstillet til standard 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startOpret forbindelse til serveren og opret en dummy-tabel tblDummy og et indeks på c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Udfyld dummy-data med 200.000 tupler, sådan at der er 10.000 unikke p_id og for hver p_id er der 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Genstart serveren for at rydde cachen. Udfør nu en forespørgsel og kontroller, hvor lang tid det tager at udføre den samme
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msTjek derefter de blokke, der er læst fra disken
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0I ovenstående eksempel blev der læst 1000 blokke fra disken for at finde tæller, hvor c_id =1. Det tog 160 ms, siden der var disk I/O involveret at hente disse poster fra disken.
Udførelsen er hurtigere, hvis den samme forespørgsel udføres igen, da alle blokkene stadig er i cachen på PostgreSQL-serveren på dette stadium
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msog blokerer læst fra disken vs fra cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Det er tydeligt ovenfra, at da alle blokke blev læst fra cachen og ingen disk I/O var påkrævet. Dette gav derfor også resultaterne hurtigere.
Indstilling af størrelsen på PostgreSQL-cachen
Størrelsen af cachen skal indstilles i et produktionsmiljø i overensstemmelse med mængden af tilgængelig RAM samt de forespørgsler, der kræves for at blive udført.
Som et eksempel – shared_buffer på 128 MB er muligvis ikke tilstrækkelig til at cache alle data, hvis forespørgslen skulle hente flere tuples:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Skift shared_buffer til 1024MB for at øge heap_blks_hit.
Faktisk, i betragtning af forespørgslerne (baseret på c_id), i tilfælde af at data reorganiseres, kan et bedre cache-hitforhold også opnås med en mindre shared_buffer.
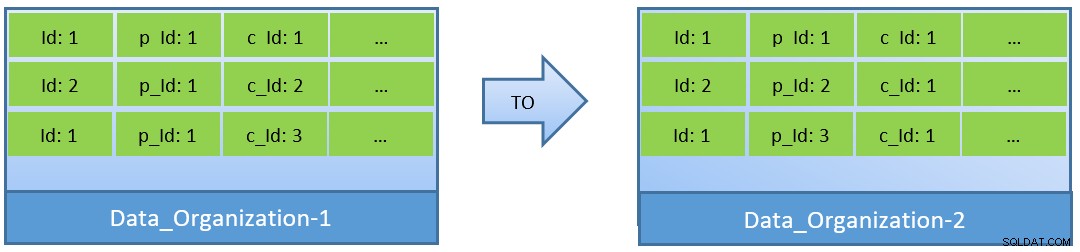
I Data_Organization-1 skal PostgreSQL have 1000 bloklæsninger (og cacheforbrug) ) for at finde c_id=1. På den anden side, for Data_Organisation-2, for den samme forespørgsel, har PostgreSQL kun brug for 104 blokke.
Færre blokke, der kræves til den samme forespørgsel, bruger til sidst mindre cache og holder også forespørgselsudførelsestiden optimeret.
Konklusion
Mens shared_buffer vedligeholdes på PostgreSQL-procesniveau, tages kerneniveaucachen også i betragtning for at identificere optimerede forespørgselsudførelsesplaner. Jeg vil tage dette emne op i en senere serie af blogs.