Der er ikke et perfekt system, hardware eller topologi til at undgå alle de mulige problemer, der kunne ske i et produktionsmiljø. At overkomme disse udfordringer kræver en effektiv DRP (Disaster Recovery Plan), konfigureret i henhold til din applikation, infrastruktur og forretningskrav. Nøglen til succes i disse typer situationer er altid, hvor hurtigt vi kan løse eller komme os over problemet.
I denne blog tager vi et kig på de mest almindelige PostgreSQL-fejlscenarier og viser dig, hvordan du kan løse eller håndtere problemerne. Vi vil også se på, hvordan ClusterControl kan hjælpe os med at komme online igen
Den fælles PostgreSQL-topologi
For at forstå almindelige fejlscenarier skal du først starte med en fælles PostgreSQL-topologi. Dette kan være enhver applikation, der er forbundet til en PostgreSQL Primary Node, som har en replika forbundet til sig.
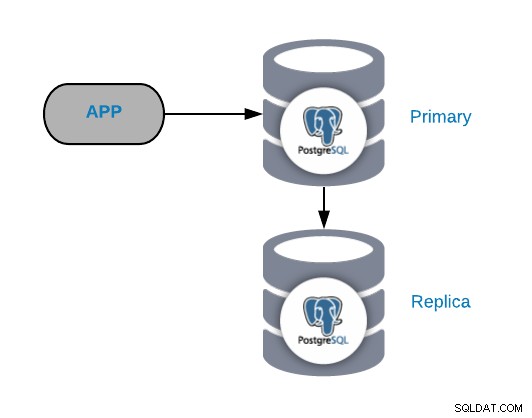
Du kan altid forbedre eller udvide denne topologi ved at tilføje flere noder eller load balancere , men dette er den grundlæggende topologi, vi begynder at arbejde med.
Primær PostgreSQL-nodefejl
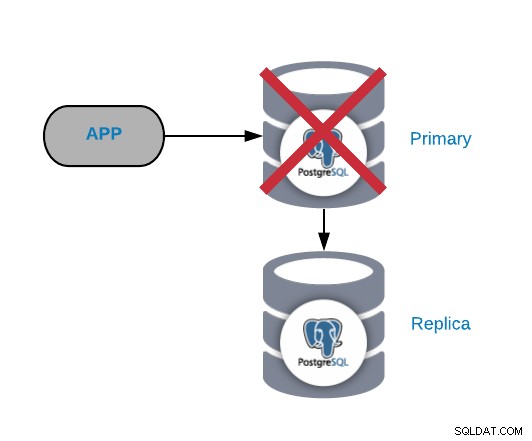
Dette er en af de mest kritiske fejl, da vi bør rette den ASAP, hvis vi ønsker at holde vores systemer online. For denne type fejl er det vigtigt at have en form for automatisk failover-mekanisme på plads. Efter fejlen kan du undersøge årsagen til problemerne. Efter failover-processen sikrer vi, at den mislykkede primære node ikke stadig tror, at den er den primære node. Dette er for at undgå datainkonsistens, når du skriver til det.
De mest almindelige årsager til denne type problemer er en operativsystemfejl, hardwarefejl eller en diskfejl. Under alle omstændigheder bør vi tjekke databasen og styresystemets logfiler for at finde årsagen.
Den hurtigste løsning på dette problem er ved at udføre en failover-opgave for at reducere nedetid. For at fremme en replika kan vi bruge kommandoen pg_ctl promote på slavedatabasenoden, og derefter skal vi sende trafikken fra applikation til den nye primære node. Til denne sidste opgave kan vi implementere en load balancer mellem vores applikation og databasenoderne, for at undgå enhver ændring fra applikationssiden i tilfælde af fejl. Vi kan også konfigurere belastningsbalanceren til at registrere knudefejlen og i stedet for at sende trafik til ham, sende trafikken til den nye primære knude.
Efter failover-processen og sørg for, at systemet fungerer igen, kan vi undersøge problemet, og vi anbefaler altid at have mindst én slaveknude i drift, så i tilfælde af en ny primær fejl, vi kan udføre failover-opgaven igen.
PostgreSQL Replika Node Fejl
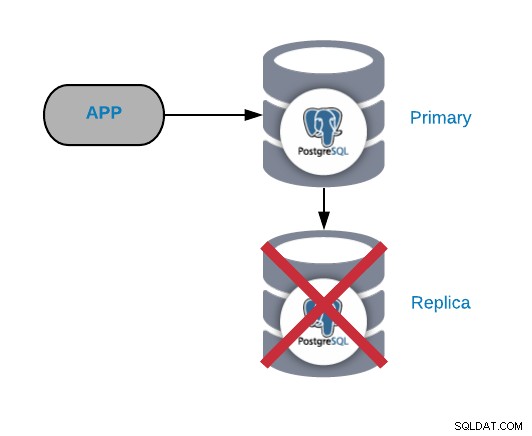
Dette er normalt ikke et kritisk problem (så længe du har mere end en replika og bruger den ikke til at sende den læste produktionstrafik). Hvis du oplever problemer på den primære node og ikke har din replika opdateret, har du et reelt kritisk problem. Hvis du bruger vores replika til rapportering eller big data-formål, vil du sikkert gerne rette det hurtigt alligevel.
De mest almindelige årsager til denne type problemer er de samme, som vi så for den primære node, en operativsystemfejl, hardwarefejl eller diskfejl. Du bør tjekke databasen og operativsystemlogfilerne for at finde årsagen.
Det anbefales ikke at lade systemet fungere uden nogen replika, da du i tilfælde af fejl ikke har en hurtig måde at komme online igen på. Hvis du kun har én slave, bør du løse problemet ASAP; den hurtigste måde at være ved at skabe en ny replika fra bunden. Til dette skal du tage en konsekvent sikkerhedskopi og gendanne den til slaveknuden, og derefter konfigurere replikationen mellem denne slaveknude og den primære knude.
Hvis du ønsker at kende årsagen til fejlen, bør du bruge en anden server til at oprette den nye replika, og derefter se på den gamle for at finde den. Når du er færdig med denne opgave, kan du også omkonfigurere den gamle replika og fortsætte med at fungere som en fremtidig failover-mulighed.
Hvis du bruger replikaen til rapportering eller til big data-formål, skal du ændre IP-adressen for at oprette forbindelse til den nye. Som i det foregående tilfælde er en måde at undgå denne ændring på ved at bruge en load balancer, der kender status for hver server, så du kan tilføje/fjerne replikaer, som du ønsker.
PostgreSQL-replikeringsfejl
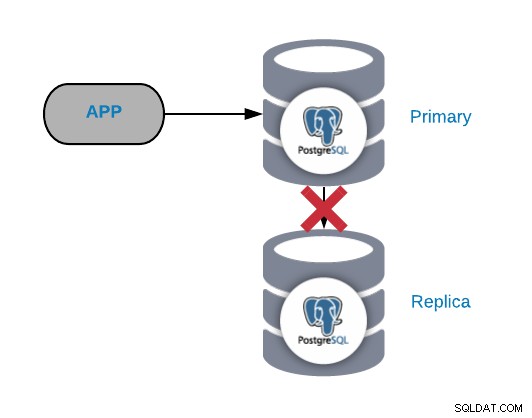
Generelt genereres denne form for problemer på grund af et netværk eller en konfiguration problem. Det er relateret til et WAL-tab (Write-Ahead Logging) i den primære node og den måde, PostgreSQL administrerer replikationen på.
Hvis du har vigtig trafik, laver du checkpoints for ofte, eller du gemmer WALS i kun et par minutter; hvis du har et netværksproblem, har du lidt tid til at løse det. Dine WAL'er ville blive slettet, før du kan sende og anvende dem på replikaen.
Hvis den WAL, som replikaen skal fortsætte med at fungere, blev slettet, skal du genopbygge den, så for at undgå denne opgave, bør vi tjekke vores databasekonfiguration for at øge wal_keep_segments (mængder af WALS, der skal opbevares i pg_xlog-mappen) eller max_wal_senders-parametrene (maksimalt antal WAL-afsenderprocesser, der kører samtidigt).
En anden anbefalet mulighed er at konfigurere archive_mode til og sende WAL-filerne til en anden sti med parameteren archive_command. På denne måde, hvis PostgreSQL når grænsen og sletter WAL-filen, vil vi alligevel have den i en anden sti.
PostgreSQL-datakorruption / datainkonsistens / utilsigtet sletning

Dette er et mareridt for enhver DBA og nok det mest komplekse problem at være rettet, afhængigt af hvor udbredt problemet er.
Når dine data er påvirket af nogle af disse problemer, er den mest almindelige måde at løse det på (og sandsynligvis den eneste) ved at gendanne en sikkerhedskopi. Derfor er sikkerhedskopier den grundlæggende form for enhver katastrofegendannelsesplan, og det anbefales, at du har mindst tre sikkerhedskopier gemt forskellige fysiske steder. Bedste praksis dikterer, at sikkerhedskopieringsfiler skal have én gemt lokalt på databaseserveren (for en hurtigere gendannelse), en anden på en centraliseret backupserver og den sidste i skyen.
Vi kan også skabe en blanding af fuld/inkrementelle/differentielle PITR-kompatible sikkerhedskopier for at reducere vores gendannelsespunktmål.
Håndtering af PostgreSQL-fejl med ClusterControl
Nu hvor vi har set på disse almindelige PostgreSQL-fejlscenarier, lad os se på, hvad der ville ske, hvis vi administrerede dine PostgreSQL-databaser fra et centraliseret databasestyringssystem. En, der er fantastisk i forhold til at nå frem til en hurtig og nem måde at løse problemet, ASAP, i tilfælde af fejl.
ClusterControl giver automatisering til de fleste af PostgreSQL-opgaverne beskrevet ovenfor; alt sammen på en centraliseret og brugervenlig måde. Med dette system vil du nemt være i stand til at konfigurere ting, som manuelt ville tage tid og kræfter. Vi vil nu gennemgå nogle af dets hovedfunktioner relateret til PostgreSQL-fejlscenarier.
Implementer / importer en PostgreSQL-klynge
Når vi kommer ind i ClusterControl-grænsefladen, er den første ting at gøre at implementere en ny klynge eller importere en eksisterende. For at udføre en implementering skal du blot vælge indstillingen Deploy Database Cluster og følge instruktionerne, der vises.
Skalering af din PostgreSQL-klynge
Hvis du går til Cluster Actions og vælger Tilføj replikeringsslave, kan du enten oprette en ny replika fra bunden eller tilføje en eksisterende PostgreSQL-database som en replika. På denne måde kan du have din nye kopi kørende på få minutter, og vi kan tilføje så mange replikaer, som vi ønsker; sprede læst trafik mellem dem ved hjælp af en load balancer (som vi også kan implementere med ClusterControl).
PostgreSQL Automatisk Failover
ClusterControl administrerer failover på din replikeringsopsætning. Den registrerer masterfejl og promoverer en slave med de nyeste data som den nye master. Den fejler også automatisk over resten af slaverne for at replikere fra den nye master. Hvad angår klientforbindelser, udnytter den to værktøjer til opgaven:HAProxy og Keepalived.
HAProxy er en belastningsbalancer, der distribuerer trafik fra en oprindelse til en eller flere destinationer og kan definere specifikke regler og/eller protokoller for opgaven. Hvis nogen af destinationerne holder op med at svare, markeres den som offline, og trafikken sendes til en af de tilgængelige destinationer. Dette forhindrer trafik i at blive sendt til en utilgængelig destination og tab af denne information ved at dirigere den til en gyldig destination.
Keelived giver dig mulighed for at konfigurere en virtuel IP inden for en aktiv/passiv gruppe af servere. Denne virtuelle IP er tildelt en aktiv "Main" server. Hvis denne server fejler, migreres IP'en automatisk til den "Sekundære" server, der blev fundet passiv, hvilket gør det muligt for den at fortsætte med at arbejde med den samme IP på en gennemsigtig måde for vores systemer.
Tilføjelse af en PostgreSQL Load Balancer
Hvis du går til Cluster Actions og vælger Add Load Balancer (eller fra klyngevisningen - gå til Administrer -> Load Balancer), kan du tilføje load balancers til vores databasetopologi.
Konfigurationen, der er nødvendig for at oprette din nye belastningsbalancer, er ret enkel. Du behøver kun at tilføje IP/værtsnavn, port, politik og de noder, vi skal bruge. Du kan tilføje to load balancers med Keepalved imellem dem, hvilket giver os mulighed for at have en automatisk failover af vores load balancer i tilfælde af fejl. Keepalved bruger en virtuel IP-adresse og migrerer den fra en load balancer til en anden i tilfælde af fejl, så vores opsætning kan fortsætte med at fungere normalt.
PostgreSQL-sikkerhedskopier
Vi har allerede diskuteret vigtigheden af at have sikkerhedskopier. ClusterControl giver funktionaliteten til enten at generere en øjeblikkelig backup eller planlægge en.
Du kan vælge mellem tre forskellige sikkerhedskopieringsmetoder, pgdump, pg_basebackup eller pgBackRest. Du kan også angive, hvor sikkerhedskopierne skal opbevares (på databaseserveren, på ClusterControl-serveren eller i skyen), komprimeringsniveauet, påkrævet kryptering og opbevaringsperioden.
PostgreSQL-overvågning og -alarm
Før du kan handle, skal du vide, hvad der sker, så du skal overvåge din databaseklynge. ClusterControl giver dig mulighed for at overvåge vores servere i realtid. Der er grafer med grundlæggende data såsom CPU, netværk, disk, RAM, IOPS, samt databasespecifikke metrics indsamlet fra PostgreSQL-instanserne. Databaseforespørgsler kan også ses fra Query Monitor.
På samme måde som du aktiverer overvågning fra ClusterControl, kan du også opsætte alarmer, som informerer dig om hændelser i din klynge. Disse advarsler kan konfigureres og kan tilpasses efter behov.
Konklusion
Alle bliver i sidste ende nødt til at klare PostgreSQL-problemer og fejl. Og da du ikke kan undgå problemet, skal du være i stand til at løse det ASAP og holde systemet kørende. Vi så også, hvordan brug af ClusterControl kan hjælpe med disse problemer; alt sammen fra en enkelt og brugervenlig platform.
Dette er, hvad vi troede var nogle af de mest almindelige fejlscenarier for PostgreSQL. Vi vil meget gerne høre om dine egne erfaringer, og hvordan du fiksede det.