Denne blog starter en multi-serie, der dokumenterer min rejse med benchmarking af PostgreSQL i skyen.
Den første del indeholder en oversigt over benchmarking-værktøjer og kickstarter det sjove med Amazon Aurora PostgreSQL.
Valg af PostgreSQL Cloud-tjenesteudbydere
For et stykke tid siden stødte jeg på AWS-benchmark-proceduren for Aurora, og tænkte, at det ville være rigtig fedt, hvis jeg kunne tage den test og køre den på andre cloud-hosting-udbydere. Til Amazons ære er AWS ud af de tre mest kendte udbydere af forsyningsdatabehandling – AWS, Google og Microsoft – den eneste store bidragyder til PostgreSQL-udvikling og den første til at tilbyde administreret PostgreSQL-tjeneste (dateres tilbage i november 2013).
Mens administrerede PostgreSQL-tjenester også er tilgængelige fra et væld af PostgreSQL-hostingudbydere, ønskede jeg at fokusere på de nævnte tre cloud computing-udbydere, da deres miljøer er, hvor mange organisationer, der leder efter fordelene ved cloud computing, vælger at køre deres applikationer, forudsat at de har den nødvendige knowhow om at administrere PostgreSQL. Jeg er overbevist om, at organisationer, der arbejder med kritiske arbejdsbelastninger i skyen, i dagens IT-landskab ville have stor gavn af tjenesterne fra en specialiseret PostgreSQL-tjenesteudbyder, som kan hjælpe dem med at navigere i den komplekse verden af GUCS og myriader af SlideShare-præsentationer.
Valg af det rigtige benchmarkværktøj
Benchmarking PostgreSQL kommer ret ofte op på præstationsmailinglisten, og som understreget utallige gange er testene ikke beregnet til at validere en konfiguration til en virkelig applikation. Det er dog vigtigt at vælge det rigtige benchmarkværktøj og -parametre for at opnå meningsfulde resultater. Jeg forventer, at hver cloud-udbyder leverer procedurer til benchmarking af deres tjenester, især når den første cloud-oplevelse måske ikke starter på den rigtige måde. Den gode nyhed er, at to af de tre spillere i denne test har inkluderet benchmarks i deres dokumentation. AWS Benchmark Procedure for Aurora-guiden er let at finde, tilgængelig lige på Amazon Aurora Resources-siden. Google leverer ikke en vejledning, der er specifik for PostgreSQL, men Compute Engine-dokumentationen indeholder en belastningstestvejledning til SQL Server baseret på HammerDB.
Følgende er en oversigt over benchmarkværktøjer baseret på deres referencer, der er værd at se på:
- AWS Benchmark nævnt ovenfor er baseret på pgbench og sysbench.
- HammerDB, også nævnt tidligere, er diskuteret i et nyligt indlæg på pgsql-hackerlisten.
- TPC-C-test baseret på oltpbench som nævnt i denne andre pgsql-hacker-diskussion.
- benchmarksql er endnu en TPC-C-test, der blev brugt til at validere ændringerne af B-Tree-sideopdelinger.
- pg_ycsb er det nye barn i byen, der forbedrer sig på pgbench og bliver allerede brugt af nogle af PostgreSQL-hackerne.
- pgbench-tools er, som navnet antyder, baseret på pgbench, og selvom det ikke har modtaget nogen opdateringer siden 2016, er det et produkt af Greg Smith, forfatteren til PostgreSQL High Performance-bøger.
- join order benchmark er et benchmark, der tester forespørgselsoptimeringsværktøjet.
- pgreplay, som jeg stødte på, mens jeg læste kommandopromptbloggen, er så tæt som det kan komme på benchmarking af et virkeligt scenarie.
Et andet punkt at bemærke er, at PostgreSQL endnu ikke er velegnet til TPC-H benchmark-standarden, og som nævnt ovenfor skal alle værktøjerne (undtagen pgreplay) køres i TPC-C-tilstand (pgbench er standard til det).
Til formålet med denne blog tænkte jeg, at AWS Benchmark-proceduren for Aurora er en god start, simpelthen fordi den sætter en standard for cloud-udbydere og er baseret på udbredte værktøjer.
Jeg brugte også den seneste tilgængelige PostgreSQL-version på det tidspunkt. Når du vælger en cloud-udbyder, er det vigtigt at overveje hyppigheden af opgraderinger, især når vigtige funktioner introduceret af nye versioner kan påvirke ydeevnen (hvilket er tilfældet for version 10 og 11 versus 9). Når dette skrives, har vi:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS til PostgreSQL 10.6
- Google Cloud SQL til PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...og vinderen her er AWS ved at tilbyde den seneste version (selvom det ikke er den seneste, som i skrivende stund er 11.2).
Opsætning af benchmarkingmiljøet
Jeg besluttede at begrænse mine tests til gennemsnitlige arbejdsbelastninger af et par grunde:For det første er de tilgængelige cloud-ressourcer ikke identiske på tværs af udbydere. I vejledningen er AWS-specifikationerne for databaseinstansen 64 vCPU / 488 GiB RAM / 25 Gigabit Network, mens Googles maksimale RAM for enhver instansstørrelse (valget skal indstilles til "custom" i Google Calculator) er 208 GiB, og Microsofts Business Critical Gen5 på 32 vCPU kommer med kun 163 GiB). For det andet bringer pgbench-initialiseringen databasestørrelsen til 160 GiB, som i tilfælde af en instans med 488 GiB RAM sandsynligvis vil blive lagret i hukommelsen.
Jeg lod også PostgreSQL-konfigurationen være urørt. Årsagen til at holde fast i cloud-udbyderens standarder er, at en administreret tjeneste ud af boksen, når den bliver understreget af et standard benchmark, forventes at yde nogenlunde godt. Husk, at PostgreSQL-fællesskabet kører pgbench-tests som en del af udgivelseshåndteringsprocessen. Derudover nævner AWS-vejledningen ikke nogen ændringer til standard PostgreSQL-konfigurationen.
Som forklaret i vejledningen anvendte AWS to patches på pgbench. Da patchen til antallet af klienter ikke fandtes rent på 10.6-versionen af PostgreSQL, og jeg ikke ønskede at investere tid i at rette den, var antallet af klienter begrænset til det maksimale på 1.000.
Vejledningen specificerer et krav om, at klientforekomsten skal have forbedret netværk aktiveret - for denne forekomsttype er det standarden:
[example@sqldat.com ~]$ ip a1:lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever prefered_lft forever inet6 ::1/128 scope host valid_lft forever prefered_lft forever2:eth0:,MULTICAST mtu 9001 qdisc mq tilstand UP gruppe standard qlen 1000 link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff inet 172.31.19.190/20 brd 172.31.31.25t global scope scope_25t forever prefered_lft forever inet6 fe80::8cd:eeff:fe40:2be6/64 scope link valid_lft forever prefered_lft forever[example@sqldat.com ~]$ ethtool -i eth0driver:enaversion:2.0.2gfirmware-version:bus00-info:0 00:03.0supports-statistics:yessupports-test:nosupports-eeprom-access:nosupports-register-dump:nosupports-priv-flags:no>>> aws (master *%) ~ $ aws ec2 describe-instances --instance- ids i-0ee51642334c1ec57 --que ry "Reservations[].Instances[].EnaSupport"[ true] Kørsel af benchmark på Amazon Aurora PostgreSQL
Under selve løbeturen besluttede jeg mig for at gøre endnu en afvigelse fra guiden:i stedet for at køre testen i 1 time, sæt tidsgrænsen til 10 minutter, hvilket generelt accepteres som en god værdi.
Kør #1
Specifikationer
- Denne test bruger AWS-specifikationerne for både klient- og databaseforekomststørrelser.
- Klientmaskine:On Demand Memory Optimized EC2-instans:
- vCPU:32 (16 kerner x 2 tråde/kerne)
- RAM:244 GiB
- Lagring:EBS-optimeret
- Netværk:10 Gigabit
- DB-klynge:db.r4.16xlarge
- vCPU:64
- ECU (CPU-kapacitet):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Lagring:EBS-optimeret (dedikeret kapacitet til I/O)
- Netværk:14.000 Mbps Max båndbredde på et 25 Gps netværk
- Klientmaskine:On Demand Memory Optimized EC2-instans:
- Databaseopsætningen inkluderede én replika.
- Databaselageret blev ikke krypteret.
Udførelse af testene og resultaterne
- Følg instruktionerne i vejledningen for at installere pgbench og sysbench.
- Rediger ~/.bashrc for at indstille miljøvariablerne for databaseforbindelsen og påkrævede stier til PostgreSQL-biblioteker:
eksport PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.comexport PGUSER=postgresexport PGPASSWORD=postgresexport PGDATABASE=postgresexport PATH=$PATH:/usr/local/pgsql/binexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Initialiser databasen:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000BEMÆRK:tabellen "pgbench_history" eksisterer ikke, skippingNOTICE:tabel "pgbench_tellers" eksisterer ikke, skippingNOTICE:tabellen "pgbench_accounts" eksisterer ikke, skippingNOTICE:tabellen "pgbench_branches" eksisterer ikke, skippingopretter tabeller...100000 af 1000000000 tuples (0%) udført (forløbet 0,05 s, 023s001001 af 05002)01 tuples (0%) udførte (forløbet 0,13 s, resterende 631,70 s)300000 af 1000000000 tuples (0%) udførte (forløbet 0,21 s, resterende 688,29 s)...999500000 af 01s 0000 af 01s 0000 af 01s 0. Resterende 0,41 s) 999600000 af 10000000 tuples (99%) udført (forløbet 811,50 s, resterende 0,32 s) 999700000 af 10000000 tuples (99%) udført (forløbet 811,58 s, resterende 0,24 s) 999800000 af 10000000 tuples (99%) udført (udført (udført (udført (udført (udført (udført (udført (udført (udført (udført (gjort forløbet 811,65 s, resterende 0,16 s)999900000 af 1000000000 tupler (99%) udførte (forløbet 811,73 s, resterende 0,08 s)1000000000 af 00000 s. 100 %) udført (forløbet 811,80 s, resterende 0,00 s) vakuum...indstil primærnøgler...færdig. - Bekræft databasestørrelsen:
postgres=> \l+ postgres Liste over databaser Navn | Ejer | Kodning | Sæt sammen | Ctype | Adgangsrettigheder | Størrelse | Bordplads | Beskrivelse ------------------------------------ ----------+--------------------+--------+--------- ---+---------------------------------------------------- postgres | postgres | UTF8 | da_US.UTF-8 | da_US.UTF-8 | | 160 GB | pg_default | standard administrativ forbindelsesdatabase (1 række) - Brug følgende forespørgsel til at bekræfte, at tidsintervallet mellem checkpoints er indstillet, så checkpoints vil blive tvunget i løbet af 10 minutter:
Resultat:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpointsFROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutter_mellem_kontrolpunkter --------------------+---------------------------------------- 50 | 0,977392292333333(1 række) - Kør læse/skrive-arbejdsbelastningen:
Output[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048startvakuum...end.progress:60,0 s, 35670,3 tps, lat 27,243 ms stddev 10,915progress:120,0 s, 36569,5 tps, lat 27,352 ms stddev . STDDDEV 12.785Progress:240.0 S, 36613.7 TPS, LAT 27.310 MS STDDEV 11.804PROGRESS:300.0 S, 37323.4 TPS, LAT 26.793 MS STDDEV 11.376PROGRESS:360.0 S, 36828.8 TPS, LAT 27.155 MS.30.3232323232320180.320.320.320. lat 27.268 ms stddev 12.083progress:480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981progress:540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341progress:600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521transaction type: - Forbered sysbench-testen:
Output:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1. rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ -- oltp-table-size=450000 \forberedsysbench 0.5:benchmark for multi-threaded systemevaluering Opretter tabel 'sbtest1'...Indsætter 450000 poster i 'sbtest1'Opretter sekundære indekser på 'sbtest1'...Opretter tabel 'sbtest2'.... ..Opretter tabel 'sbtest250'...Indsætter 450000 poster i 'sbtest250'Opretter sekundære indekser på 'sbtest250'... - Kør sysbench-testen:
Output:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1. rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ -- oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp- sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-tid=600 \ --antal-tråde=1000 \ køresysbench 0.5:multi-threaded system evaluering benchmarkKørsel af testen med følgende muligheder:Antal tråde:1000Rapporter mellemresultater hvert 60. sekund(er) Tilfældig tal generator seed er 0 og vil blive ignoreretTvinger nedlukning om 630 sekunder arbejdertråde...Tråde startede![ 60s] tråde:1000, tps:20443.09, læser:0.00, skriver:81834.16, responstid:68.24ms (95%), fejl:0.62, genopretter:0.00 tråde:012.00][ 012.00] , tps:20580.68, læser:0.00, skriver:82324.33, responstid:70.75ms (95%), fejl:0.73, genopretter forbindelse:0.00[ 180s] tråde:1000, tps.:8.050s:0.201s tid:70,63ms (95%), fejl:0,73, genopretter:0,00[ 240s] tråde:1000, tps:20212,67, læser:0,00, skriver:80861,67, responstid:71,99ms, 3,4 ms, 3,5% :0,00[ 300s] tråde:1000, tps:19383,90, læser:0,00, skriver:77537,87, svartid:75,64ms (95%), fejl:0,75, genopretter:0,00][ 0,1ts:0,9ts:0,9ts:0,9 ts 0, læser:0.00, skriver:79190.78, svartid:75.27ms (95%), fejl:0.68, genopretter:0.00[ 420s] tråde:1000, tps:20304.43, læser:0.304.43, skriv:0.00:8.72, 8.00:8. ms (95%), fejl:0,70, genopretter:0,00[ 480s] tråde:1000, tps:20933,80, læser:0,00, skriver:83737,16, responstid:74,71ms (95%), 8 fejl:.00s:8,.00s. 540s] tråde:1000, tps:20663.05, læser:0.00, skriver:82626.42, responstid:73.56ms (95%), fejl:0.75, genopretter:0.00[ 600s] 0.00s:0.0ps:0.0ps:0.0ps skriver:83015.81, svartid:73.58ms (95%), fejl:0.78, genopretter forbindelse:0.00OLTP-teststatistik:udførte forespørgsler:læst:0 skriv:48868458 andet:24434022 i alt:733020184 læst:5.9205c /write anmodninger:48868458 (81440,43 pr. sek.) andre operationer:24434022 (40719,87 pr. sek.) ignorerede fejl:414 (0,69 pr. sek.) genopretter forbindelse:0 (0,00 pr. sek.)Generel statistik:samlet tid:600,0516s samlet antal hændelser:12216804 total tid taget af 4 hændelser 3959 4 reaktioner 3959. tid:min:6,27 ms gns.:49,11 ms max:350,24 ms ca. 95 percentil:72,90 ms. Tråde fairness:hændelser (avg/stddev):12216.8040/31.27 eksekveringstid (avg/stddev):599.9645/0.01
Metrics indsamlet
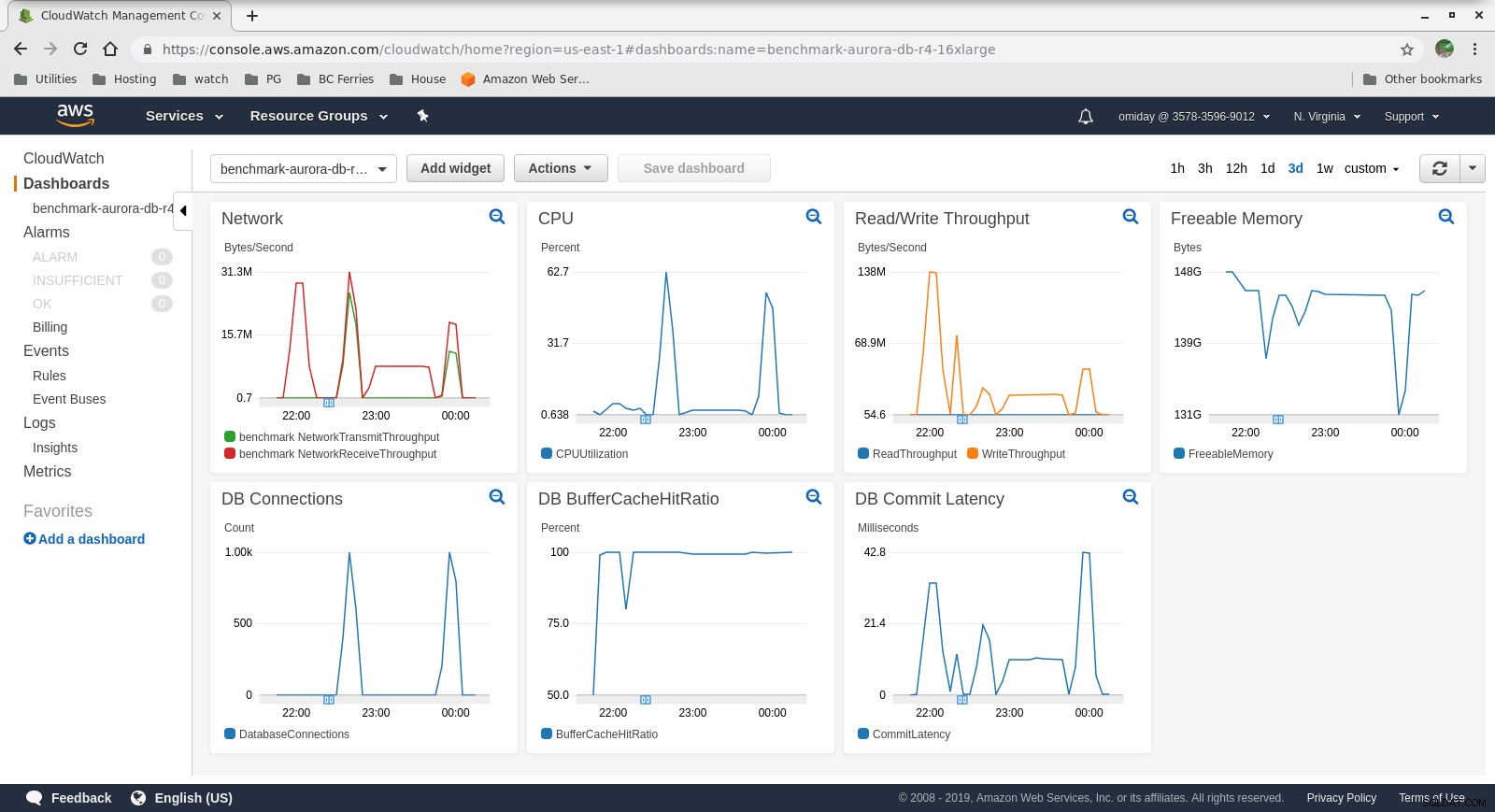 Cloudwatch-metrics
Cloudwatch-metrics 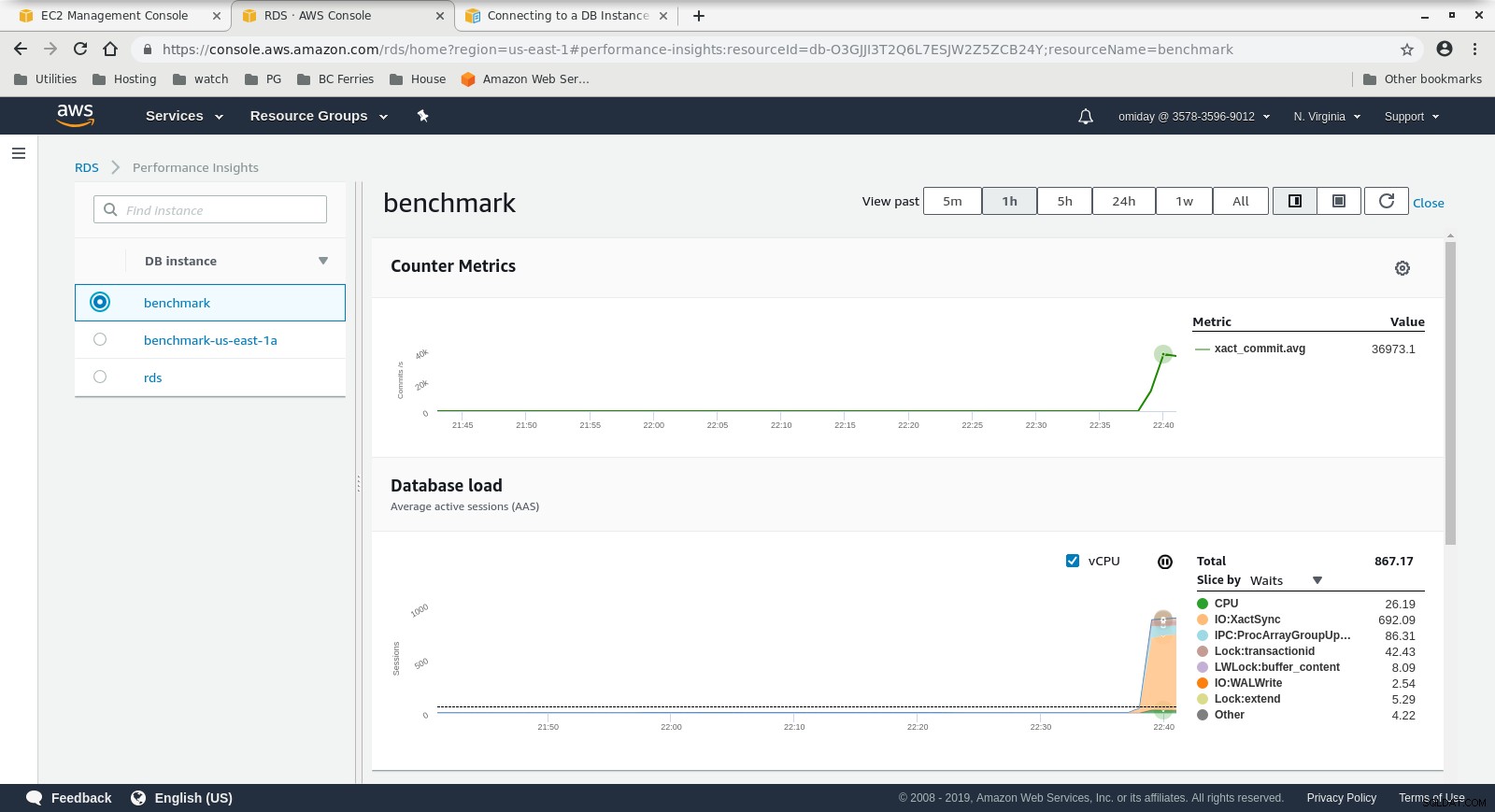 Performance Insights MetricsDownload Whitepaper Today PostgreSQL Management &Automation med ClusterControl med ClusterControl for at vide, hvad du har brug for at vide om, hvad du skal overvåge. administrer og skaler PostgreSQLDownload hvidbogen
Performance Insights MetricsDownload Whitepaper Today PostgreSQL Management &Automation med ClusterControl med ClusterControl for at vide, hvad du har brug for at vide om, hvad du skal overvåge. administrer og skaler PostgreSQLDownload hvidbogen Kør #2
Specifikationer
- Denne test bruger AWS-specifikationerne for klienten og en mindre instansstørrelse for databasen:
- Klientmaskine:On Demand Memory Optimized EC2-instans:
- vCPU:32 (16 kerner x 2 tråde/kerne)
- RAM:244 GiB
- Lagring:EBS-optimeret
- Netværk:10 Gigabit
- DB-klynge:db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Lagring:EBS-optimeret
- Netværk:1.750 Mbps Max båndbredde på en op til 10 Gbps forbindelse
- Klientmaskine:On Demand Memory Optimized EC2-instans:
- Databasen indeholdt ikke en replika.
- Databaselageret blev ikke krypteret.
Udførelse af testene og resultaterne
Trinnene er identiske med kørsel #1, så jeg viser kun outputtet:
-
pgbench Læse/skrive arbejdsbelastning:
...745700000 af 1000000000 tupler (74%) udført (forløbet 794,93 s, resterende 271,09 s)745800000 af 1000000000 tuples (74 %) udførte (74,93 s. 02 s. 01 02 02 tilbage) 74%) udført (forløbet 795,09 s, resterende 270,86 s) 746000000 af 10000000 tuples (74%) udført (forløbet 795,17 s, resterende 270,74 s) 746100000 af 10000000 tuples (74%) udført (Elapsed 795,24 s, resterende 270,62 S) 746200 af 1000000000 tupler (74%) færdige (forløbet 795,33 s, resterende 270,51 s)...999800000 af 1000000000 tuples (99%) udførte (forløbet 1067,11 s, 01s 0,01 s 01s 0,01 s 0,01 s 0s, 0s 0s 0s, 0s 0s 0s, 0s 0s 0s, 01s 0s, 0s 0s . s, resterende 0,11 s)1000000000 af 1000000000 tuples (100%) udført (forløbet 1067,28 s, resterende 0,00 s) vakuum...sæt primære nøgler...samlet tid:4386,44 s (7,2 s 0,2 s (7,2 s, 0,2 s, 0,3 sek. s, indeks 1230,41 s)udført.startvakuum...end.fremskridt:60,0 s, 3361,3 tps, lat 286,143 ms stddev 80,417fremskridt:120,0 s, 3466,8 tps, lat 288,386 ms stddev 306,8 ts . STDDDEV 75.712Progress:240.0 S, 3444.3 TPS, LAT 289.909 MS STDDEV 69.564PROGRESS:300.0 S, 3475.8 TPS, LAT 287.736 MS STDDEV 73.712Progress:360.0 S, 3449.5 TPS, LAT 289.832 MSDEV 71.18.10.10.10.10.10.1.10.1.10.1.10.1.10.1.10.1.10.1.10.1.10.1, 34.5 S Lat81.5 S.81.8. 284.432 ms stddev 74.276 Progress:480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264Progress:540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206Press:600.0 s, 3482.9 tps, lat 287 -B (sort of)>skaleringsfaktor:10000forespørgselstilstand:forberedtantal klienter:1000antal tråde:1000varighed:600 snumber af transaktioner, der faktisk er behandlet:2090702latency gennemsnit =286.030 mslatens stddev =74.745 mstps =74.745 mstps 74.74) ekskl. oprettelse af forbindelser) -
sysbench test:
sysbench 0.5:multi-threaded system evaluering benchmarkKørsel af testen med følgende muligheder:Antal tråde:1000Rapporter mellemresultater hvert 60. sekund(er) Tilfældig tal generator seed er 0 og vil blive ignoreret. ...Tråde startet![ 60s] tråde:1000, tps:4809.05, læser:0.00, skriver:19301.02, svartid:288.03ms (95%), fejl:0.05, genopretter:0.00[ 120sps] tråde:120sps :5264.15, læser:0.00, skriver:21005.40, responstid:255.23ms (95%), fejl:0.08, genopretter:0.00[ 180s] tråde:1000, tps:5178.27, 0s:7.0s:7.0s:7,0s:7,0s 260,40ms (95%), fejl:0,03, gentilslut:0,00[ 240s] tråde:1000, tps:5145,95, læser:0,00, skriver:20610,08, responstid:255,76ms:0,00 ms, 5,00 ms, 50% [ 300s] tråde:1000, tps:5127.92, læser:0.00, skriver:20507.98, svartid:264.24ms (95%), fejl:0.05, genopretter forbindelse:0.00[ 360s] 0.00s:3ts:0, 3ts 0.00, skriver:20278.10, responstid:268.55ms (95%), fejl:0.05, genopretter:0.00[ 420s] tråde:1000, tps:5057.51, læser:0.000, skriver:37.2802 ms:97.2802:97.2802 ), fejl:0,10, genopretter:0,00[ 480s] tråde:1000, tps:5036,32, læser:0,00, skriver:20139,29, svartid:279,62 ms (95%), fejl:0,10, tråde:0,10, 0,10. 1000, tps:5115.25, læser:0.00, skriver:20459.05, svartid:264.64ms (95%), fejl:0.08, genopretter:0.00[ 600s] tråde:1000, 2 tps:0.9, 2 tps:0.9 responstid:265,43 ms (95%), fejl:0,10, genforbindelser:0,00OLTP-teststatistik:udførte forespørgsler:læst:0 skrivning:12225686 andet:6112822 i alt:18338508 transaktioner:3056390 (5 pr. sewrite.) læst anmodning:5093c. 12225686 (20375,20 pr. sek.) andre operationer:6112822 (10187,57 pr. sek.) ignorerede fejl:42 (0,07 pr. sek.) genforbindelser:0 (0,00 pr. sek.)Generel statistik:samlet tid:600,0277s samlet antal hændelser:3056390 samlet tid taget af 60 hændelsesekrering:1005 svar. tid:min:9,57 ms gns.:196,31 ms max:608,70 ms ca. 95 percentil:268,71ms Tråde fairness:hændelser (avg/stddev):3056.3900/67.44 eksekveringstid (avg/stddev):600.0052/0.01
Metrics indsamlet
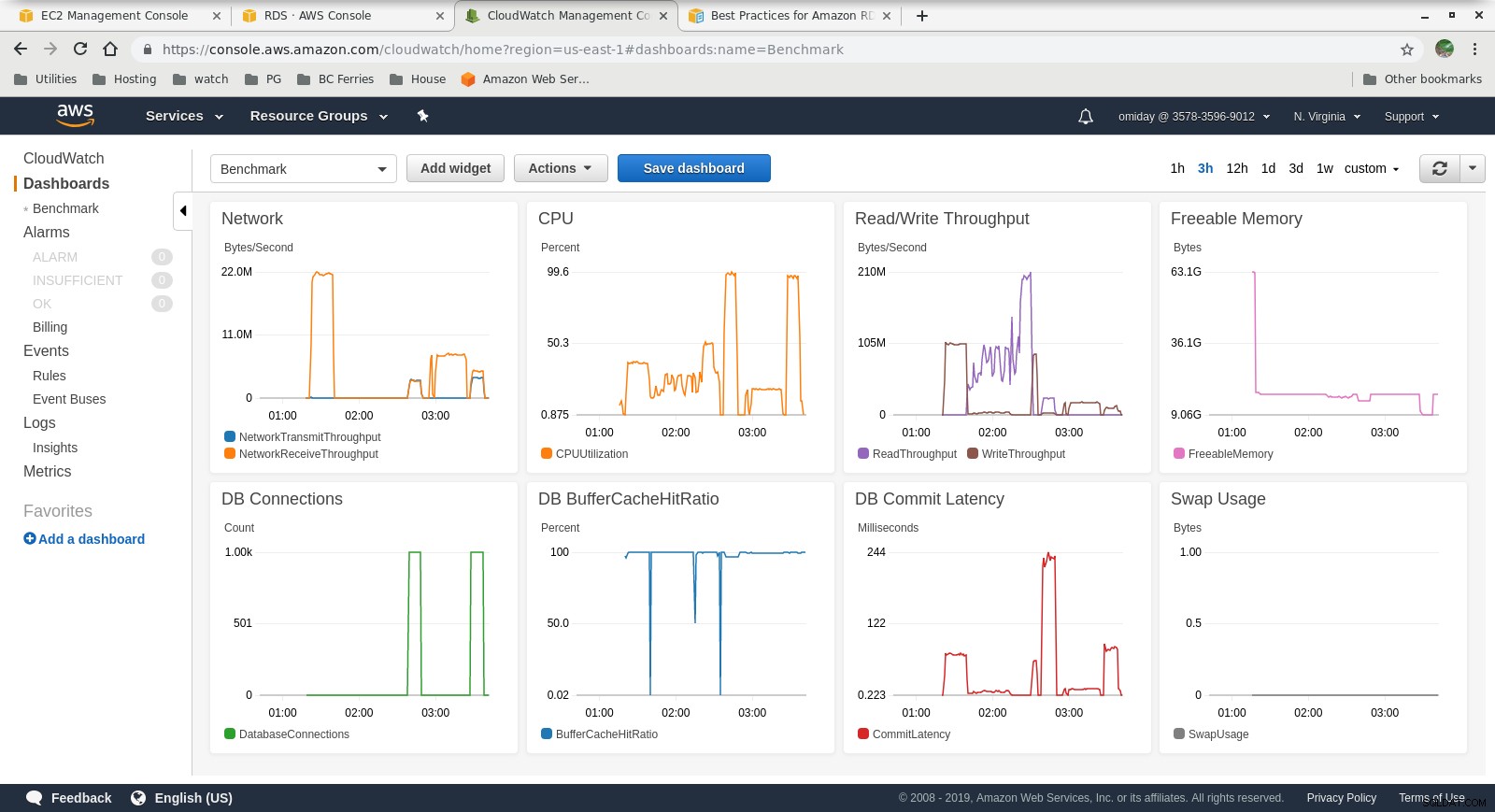 Cloudwatch-metrics
Cloudwatch-metrics 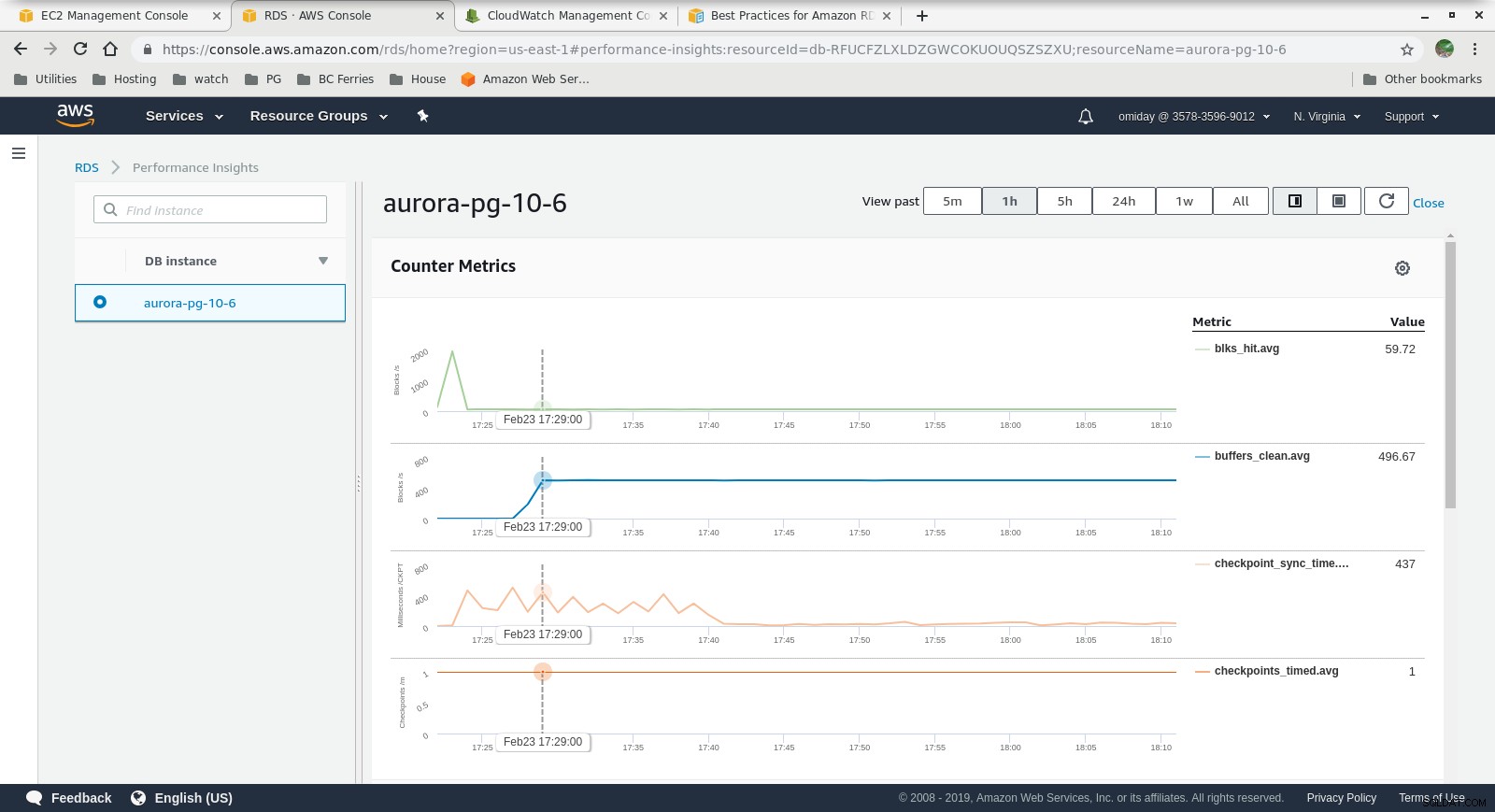 Performance Insights - Counter Metrics
Performance Insights - Counter Metrics 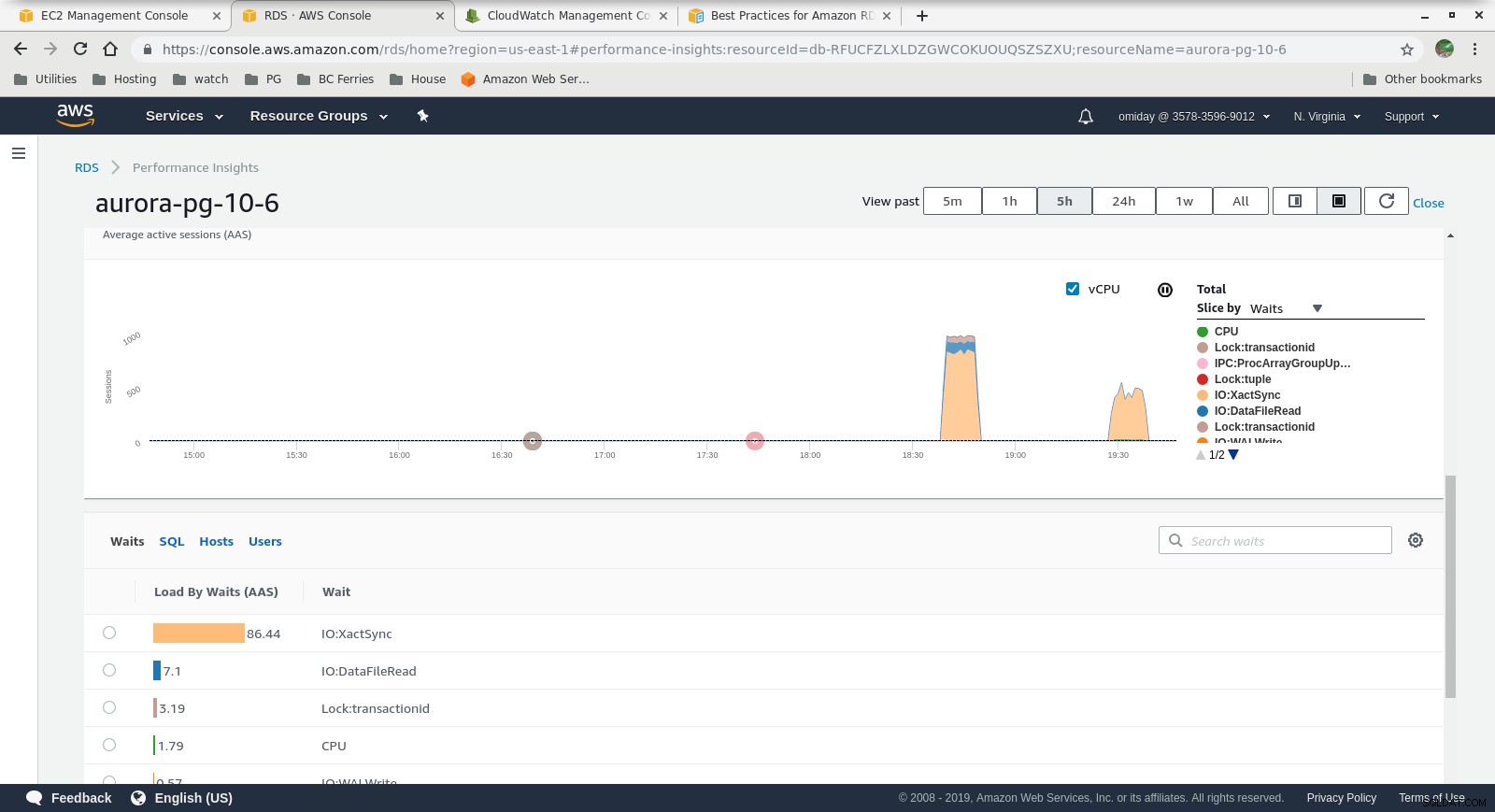 Performance Insights - Database Load by Waits
Performance Insights - Database Load by Waits Sidste tanker
- Brugere er begrænset til at bruge foruddefinerede instansstørrelser. Som en ulempe, hvis benchmark viser, at instansen kan drage fordel af yderligere hukommelse, er det ikke muligt at "bare tilføje mere RAM". Tilføjelse af mere hukommelse betyder at øge instansstørrelsen, hvilket kommer med en højere pris (omkostningerne fordobles for hver instansstørrelse).
- Amazon Aurora-lagringsmotor er meget forskellig fra RDS og er bygget oven på SAN-hardware. I/O-gennemløbsmålingerne pr. instans viser, at testen ikke kom endnu tættere på maksimum for de leverede IOPS SSD EBS-volumener på 1.750 MiB/s.
- Yderligere justering kan udføres ved at gennemgå AWS PostgreSQL-begivenheder, der er inkluderet i Performance Insights-graferne.
Næste i serien
Følg med i næste del:Amazon RDS til PostgreSQL 10.6.