Hvorfor tager det så lang tid at udføre en forespørgsel? Hvorfor er der ingen indekser? Du har sandsynligvis hørt om EXPLAIN i PostgreSQL. Der er dog stadig mange mennesker, der ikke aner, hvordan man bruger det. Jeg håber, at denne artikel vil hjælpe brugerne med at tackle med dette fantastiske værktøj.
Denne artikel er forfatterrevisionen af Understanding EXPLAIN af Guillaume Lelarge. Da jeg er gået glip af nogle oplysninger, anbefaler jeg stærkt, at du sætter dig ind i originalen.
Djævelen er ikke så sort, som han er malet
Det er vigtigt at forstå logikken i PostgreSQL-kernen for at optimere forespørgsler. Jeg vil prøve at forklare. Det er virkelig ikke så kompliceret.
EXPLAIN viser den nødvendige information, der forklarer, hvad kernen gør for hver specifik forespørgsel.
Lad os tage et kig på, hvad EXPLAIN-kommandoen viser og forstå, hvad der præcist sker inde i PostgreSQL. Du kan anvende disse oplysninger til PostgreSQL 9.2 og nyere versioner.
Vores opgaver:
- Lær, hvordan du læser og forstår outputtet af EXPLAIN-kommandoen
- Forstå, hvad der sker i PostgreSQL, når en forespørgsel udføres
Første trin
Vi vil øve os på et testbord med en million rækker.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Prøv at læse dataene
EXPLAIN SELECT * FROM foo;
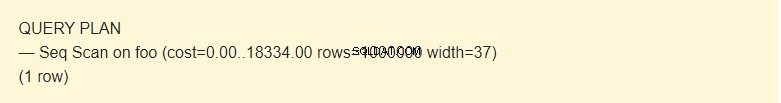
Det er muligt at læse data fra en tabel på flere måder. I vores tilfælde meddeler EXPLAIN, at der bruges en Seq Scan - en sekventiel, blok-for-blok, læst Foo-tabeldata.
Hvad er omkostninger ?
Nå, det er ikke en tid, men et koncept designet til at estimere omkostningerne ved en operation. Den første værdi 0,00 er omkostningerne for at få den første række. Den anden værdi 18334,00 er omkostningerne for at få alle rækkerne.
Rækker er det omtrentlige antal rækker, der returneres, når en Seq Scan-operation udføres. Planlæggeren returnerer denne værdi. I mit tilfælde matcher det det faktiske antal rækker i tabellen.
Bredde er en gennemsnitlig størrelse på en række i bytes.
Lad os prøve at tilføje 10 rækker.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Værdien af rækker er ikke blevet ændret. Tabellens statistik er gammel. For at opdatere statistikkerne skal du kalde kommandoen ANALYSE.
Nu, rækker vis det korrekte antal rækker.
Hvad sker der, når du udfører ANALYSE?
- Tilfældigt vælges et antal rækker og læses fra tabellen.
- Statistikken over værdier for hver kolonne indsamles.
Antallet af rækker ANALYZE læser afhænger af parameteren default_statistics_target.
Faktiske data
Alt, hvad vi så ovenfor i outputtet af EXPLAIN-kommandoen, er, hvad planlæggeren forventer at få. Lad os prøve at sammenligne dem med resultaterne på faktiske data. For at gøre dette, brug EXPLAIN (ANALYSER).
EXPLAIN (ANALYZE) SELECT * FROM foo;

En sådan forespørgsel vil faktisk blive udført. Så hvis du udfører EXPLAIN (ANALYSER) for INSERT-, DELETE- eller UPDATE-sætningerne, vil dine data blive ændret. Vær forsigtig! I disse tilfælde skal du bruge kommandoen ROLLBACK.
Kommandoen viser følgende yderligere parametre:
- faktisk tid er den faktiske tid i millisekunder brugt på at hente henholdsvis den første række og alle rækker.
- rækker er det faktiske antal rækker modtaget med Seq Scan.
- loops er det antal gange, Seq Scan-operationen skulle udføres.
- Samlet kørselstid er den samlede tid for udførelse af forespørgsler.
Yderligere læsning:
Forespørgselsoptimering i PostgreSQL. FORKLAR Grundlæggende – Del 2
Forespørgselsoptimering i PostgreSQL. FORKLARING Grundlæggende – Del 3