I min tidligere artikel begyndte vi at beskrive det grundlæggende i EXPLAIN-kommandoen og analyserede, hvad der sker i PostgreSQL, når en forespørgsel udføres.
Jeg vil fortsætte med at skrive om det grundlæggende i EXPLAIN i PostgreSQL. Oplysningerne er en kort gennemgang af Understanding EXPLAIN af Guillaume Lelarge. Jeg anbefaler stærkt at læse originalen, da nogle oplysninger er gået glip af.
Cache
Hvad sker der på det fysiske niveau, når vi udfører vores forespørgsel? Lad os finde ud af det. Jeg installerede min server på Ubuntu 13.10 og brugte diskcaches på OS-niveau.
Jeg stopper PostgreSQL, forpligter ændringer til filsystemet, rydder cache og kører PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Når cachen er ryddet, skal du køre forespørgslen med BUFFERE-indstillingen
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Vi læser tabellen for blokke. Cachen er tom. Vi skulle have adgang til 8334 blokke for at læse hele tabellen fra disken.
Buffere:delt læsning er antallet af blokke, PostgreSQL læser fra disken.
Kør den forrige forespørgsel
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffere:delt hit er antallet af blokke hentet fra PostgreSQL-cachen.
Med hver forespørgsel tager PostgreSQL flere og flere data fra cachen og fylder således sin egen cache.
Cachelæseoperationer er hurtigere end disklæseoperationer. Du kan se denne tendens ved at spore den samlede runtime-værdi.
Cachelagerstørrelsen er defineret af shared_buffers-konstanten i postgresql.conf-filen.
HVOR
Tilføj betingelsen til forespørgslen
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Der er ingen indekser på bordet. Når forespørgslen udføres, scannes hver post i tabellen sekventielt (Seq Scan) og sammenlignes med c1> 500-betingelsen. Hvis betingelsen er opfyldt, tilføjes posten til resultatet. Ellers kasseres den. Filter angiver denne adfærd, såvel som omkostningsværdien stiger.
Det estimerede antal rækker falder.
Den originale artikel forklarer, hvorfor omkostningerne tager denne værdi, og hvordan det estimerede antal rækker beregnes.
Det er tid til at oprette indekser.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Det estimerede antal rækker er ændret. Hvad med indekset?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Kun 510 rækker på mere end 1 million er filtreret. PostgreSQL skulle læse mere end 99,9 % af tabellen.
Vi tvinger til at bruge indekset ved at deaktivere Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

I Index Scan og Index Cond bruges foo_c1_idx-indekset i stedet for Filter.
Når du vælger hele tabellen, vil brugen af indekset øge omkostningerne og tiden til at udføre forespørgslen.
Aktiver Seq Scan:
SET enable_seqscan TO on;
Rediger forespørgslen:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
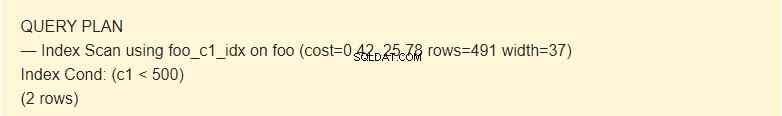
Her bruger planlæggeren indekset.
Lad os nu komplicere værdien ved at tilføje tekstfeltet.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Som du kan se, bruges foo_c1_idx-indekset til c1 <500. For at udføre c2 ~~ 'abcd%'::text, skal du bruge filteret.
Det skal bemærkes, at POSIX-formatet for LIKE-operatoren bruges i outputtet af resultaterne. Hvis der kun er tekstfeltet i tilstanden:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan anvendes.
Byg indekset ved c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Indekset anvendes ikke, fordi min database for testfelter bruger UTF-8-kodning.
Når du bygger indekset, er det nødvendigt at angive klassen for text_pattern_ops-operatoren:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Store! Det virkede!
Bitmap Index Scan bruger foo_c2_idx1-indekset til at bestemme de poster, vi har brug for. Derefter går PostgreSQL til tabellen (Bitmap Heap Scan) for at sikre, at disse poster faktisk eksisterer. Denne adfærd refererer til versionering af PostgreSQL.
Hvis du kun vælger det felt, som indekset er bygget på, i stedet for hele rækken:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan vil blive udført hurtigere end Index Scan på grund af det faktum, at det ikke er nødvendigt at læse tabellens række:width=4.
Konklusion
- Seq Scan læser hele tabellen
- Index Scan bruger indekset til WHERE-sætningerne og læser tabellen, når rækker vælges
- Bitmap Index Scan bruger Index Scan og valgkontrol gennem tabellen. Effektiv til et stort antal rækker.
- Kun indeksscanning er den hurtigste blok, som kun læser indekset.
Yderligere læsning:
Forespørgselsoptimering i PostgreSQL. FORKLARING Grundlæggende – Del 3