Nogle gange sker det, at du har en meget stor tekst- eller CSV-fil, der skal behandles, men først vil du lave mindre filer af den store fil. Fordi den store fil kan tage for lang tid at behandle eller åbne. Så jeg giver et eksempel nedenfor for at opdele store tekst-/CSV-filer i flere filer i PL SQL ved hjælp af lagret procedure.
Du skal blot overføre to parametre til denne PL SQL-procedure, den første er databasebibliotekets objektnavn, hvor tekstfilerne findes, og den anden er kildefilnavnet (den fil, du vil opdele).
Hvis Oracle biblioteksobjekt ikke findes for placeringen af tekstfiler, kan du oprette det som vist nedenfor:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Skift stien ovenfor i henhold til dine filers placering. Opret derefter nedenstående procedure ved at udføre dets script:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Denne procedure opdeler 100 rækker for hver fil, som du kan ændre efter dit behov. Udfør nu denne procedure som vist nedenfor ved at sende databasekatalogobjektnavnet og filnavnet:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
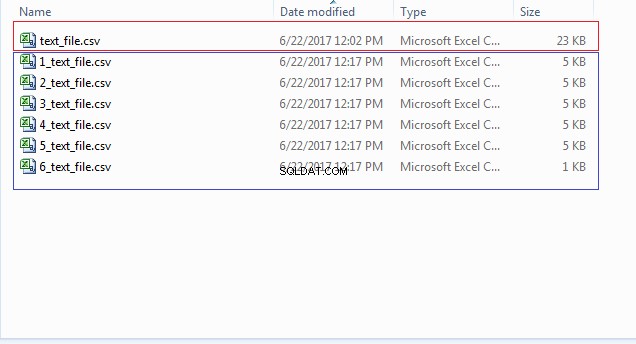
END; Du kan kontrollere din filplacering (CSV_FILE_DIR) for flere filer, der starter med tal som 1_text_file.csv, 2_text_file.csv og så videre, som vist på billedet nedenfor: