Transaktionslogfiler er en vital og vigtig komponent i databasearkitekturen. I denne artikel vil vi diskutere SQL Server-transaktionslogfiler, vigtighed og deres rolle i databasemigreringen.
Introduktion
Lad os tale om forskellige muligheder for at tage SQL Server-sikkerhedskopier. SQL Server understøtter tre forskellige typer sikkerhedskopier.
1. Fuld
2. Differentiale
3. Transaktionslog
Inden vi springer ind i transaktionslogkoncepter, lad os diskutere andre grundlæggende sikkerhedskopieringstyper i SQL Server.
En fuld backup er en kopi af alt. Som navnet antyder, vil den sikkerhedskopiere alt. Det vil sikkerhedskopiere alle data, hvert objekt i databasen, såsom en fil, filgruppe, tabel osv.:– En fuld sikkerhedskopiering er en base for enhver anden type sikkerhedskopiering.
En differentiel sikkerhedskopiering vil sikkerhedskopiere data, der er ændret siden sidste fulde sikkerhedskopiering.
Den tredje mulighed er en Transaction-Log Backup, som vil logge alle de erklæringer, som vi udsteder til databasen i transaktionsloggen. Transaktionsloggen er en mekanisme kendt som "WAL" (Write-Ahead-Logging). Den skriver hver enkelt information ud til transaktionsloggen først og derefter til databasen. Processen opdaterer med andre ord typisk ikke databasen direkte. Dette er den eneste tilgængelige mulighed med fuld gendannelsesmodel af databasen. I andre gendannelsesmodeller er data enten delvise, eller der er ikke nok data i loggen. For eksempel vil logposten ved registrering af starten af en ny transaktion (LOP_BEGIN_XACT-logposten) indeholde det tidspunkt, hvor transaktionen startede, og LOP_COMMIT_XACT-logposterne (eller LOP_ABORT_XACT) vil registrere det tidspunkt, hvor transaktionen blev begået (eller afbrudt).
For at finde interne elementer i online transaktionslog kan du søge efter sys.fn_dblog-funktionen.
Systemfunktionen sys.fn_dblog accepterer to parametre, først begynder LSN og slut LSN for transaktionen. Som standard er den sat til NULL. Hvis den er sat til NULL, returnerer den alle logposter fra transaktionslogfilen.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

Som vi alle ved, er transaktionerne gemt i binært format, og det er ikke i et læsbart format. For at læse offline transaktionslogfilen kan du bruge fn_dump_dblog.
Lad os forespørge transaktionslogfilen for at se, hvem der har droppet objektet ved hjælp af fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%'
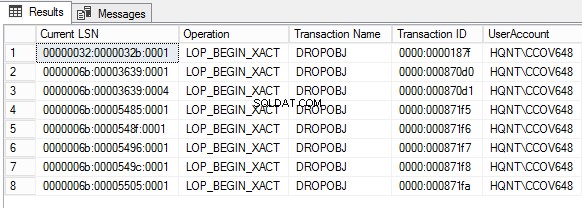
Vi vil bruge funktionen fn_dblog() til at læse den aktive del af transaktionsloggen for at finde aktivitet, der udføres på dataene. Når transaktionsloggen er ryddet, skal du forespørge dataene fra en logfil ved hjælp af fn_dump_dblog().
Denne funktion giver det samme rækkesæt som fn_dblog(), men har nogle interessante funktioner, der gør det nyttigt, er nogle fejlfindings- og gendannelsesscenarier. Specifikt kan den læse ikke kun transaktionslog for den aktuelle database, men også backup af transaktionslog på enten disk eller bånd.
Kør følgende forespørgsel for at få listen over de objekter, der slettes ved hjælp af transaktionsfil. Indledningsvis dumpes dataene til temp-tabellen. I nogle tilfælde tager udførelsen af fun_dump_dblog() lidt længere tid at udføre. Så det er bedre at fange dataene i temp-tabellen.
For at få et objekt-id fra kolonnen Låseoplysninger skal du køre følgende forespørgsel.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
For at få et objekt-id fra kolonnen Låseoplysninger skal du køre følgende forespørgsel.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp
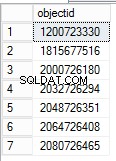
Objekt-id'et kan findes ved at manipulere kolonneværdien for låseoplysninger. For at finde objektnavnet for det tilsvarende objekt-id skal du gendanne databasen fra sikkerhedskopien lige før tabellen blev droppet. Efter gendannelsen kan du forespørge systemvisningen for at få objektnavnet.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Lad os nu se de forskellige former for de samme transaktionsdetaljer ved hjælp af sys.dn_dblog, sys.fn_full_dblog. Systemfunktionen fn_full_dblog virker kun med SQL Server 2017.
Forespørgsel for at hente de 10 bedste transaktioner ved hjælp af fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

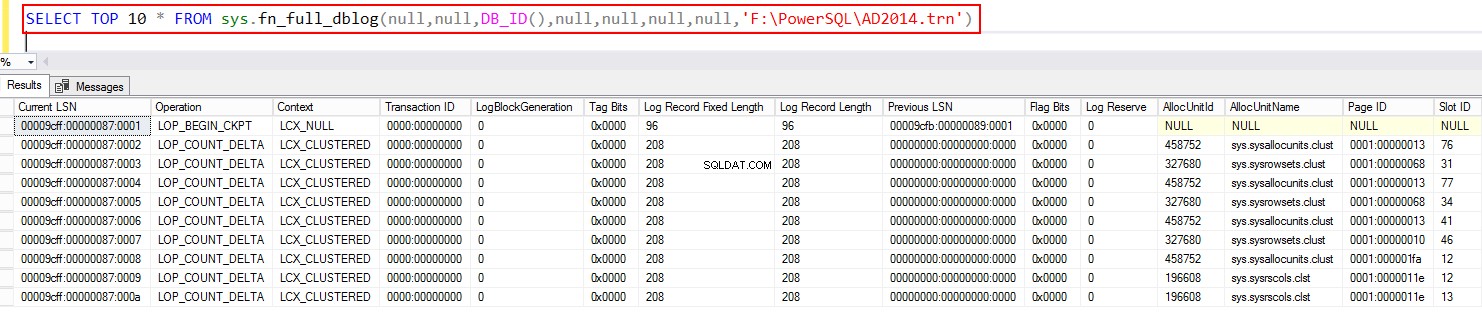
Fra SQL Server 2017 og fremefter kan du bruge fn_full dblog.
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

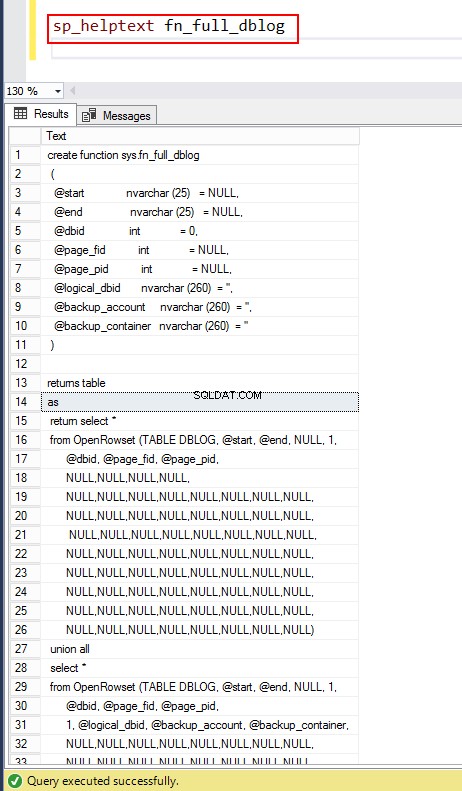
Du kan dykke yderligere ned i systemfunktionen ved at bruge sp_helptext fn_full_dblog.
Forespørg derefter backupfilen ved hjælp af systemfunktionen ved hjælp af fn_full_dblog. Igen, dette gælder kun fra SQL Server 2017 og fremefter.
Gendannelse på tidspunkter
Lad os antage, at du har listen over hele log-backupen, og når du så har til hensigt at gendanne logfilerne, har du mulighed for at udføre en punkt-i-tidsgendannelse af dataene. Så i processen med loggendannelse behøver du ikke nødvendigvis at gendanne alle data, du kan gendanne dem lige op til, før eller efter enhver individuel transaktion. Så hvis databasen går ned på et bestemt tidspunkt, og vi har både fuld backup og log backups, bør vi først kunne gendanne den fulde backup og derefter gendanne log backup, og i processen gendanne den sidste log indtil et bestemt tidspunkt , og det ville efterlade databasen i den nøjagtige tilstand, den var i, før dette problem opstod.
Log backup er ret almindelige VLDB (Very Large Database) og de fleste kritiske databaser. Det anbefales altid at teste gendannelsesprocessen. Når du laver databasesikkerhedskopier, anbefales det at tænke over gendannelsesprocessen godt, og du bør altid teste gendannelsesprocessen oftere.
Det er altid godt at lette afprøvningen af gendannelsesprocessen fra tid til anden, så sørg bare for, at processen gennemgår sikkerhedskopierne normalt.
Scenarier
Lad os tale om et scenarie, hvor du skal gendanne en meget stor database, og vi ved alle, at det normalt kan tage flere timer, og det er noget, alle bør være opmærksomme på. Hvis du planlægger databasemigrering med nul datatab og mindre udfaldsvinduer, kan det stadig være et ret stort problem. Så du sørger for at stole på backup af transaktionslog for at fremskynde processen.
Lad os overveje et andet scenarie, hvor du udfører en side-by-side databasemigrering mellem to forskellige versioner af SQL Server; du er involveret i at migrere databasen til den samme softwareversion på målet, og det inkluderer overførsel af operativsystem, database, applikation og netværk osv.:-; migrering af databasen fra et stykke hardware til et andet; ændring af både software og hardware. Processen med databasemigrering er altid udfordringen, hvor datatab altid er muligt, og det er udsat for miljøet.
Bedste praksis for databasemigrering
Lad os diskutere standardpraksis for databasemigreringsstyring.
Migrering skal ske på en transaktionsmæssig måde for at undgå uoverensstemmelser i dataene. De sædvanlige trin i migreringsprocessen er traditionelt følgende:
- Stop applikationstjenesten – det er her nedetiden starter
- Start log backup, det afhænger af dine krav
- Sæt databasen i gendannelsestilstand, så der ikke foretages yderligere ændringer i databasen
- Flyt logfilen(erne)
- Gendan databasens transaktionslogfil(er) – forudsat at du allerede har gendannet databasens fulde backup på målet og efterlader databasen i gendannelsestilstand.
- Klon login og ret de forældreløse brugere
- Opret job
- Installer applikationen
- Konfigurer netværk – Skift DNS-poster
- Genkonfigurer applikationsindstillinger
- Start applikationstjeneste
- Test applikationen
Kom godt i gang
I denne artikel vil vi diskutere, hvordan man håndterer meget stor OLTP-databasemigrering. Vi vil diskutere strategier til at bruge SQL-serverteknikker og tredjepartsværktøjer til datasikkerhed sammen med nul eller minimal forstyrrelse af produktionssystemets tilgængelighed. Under processen er der altid en chance for at miste dataene. Synes du, at en problemfri håndtering af transaktioner er en god strategi? Hvis "ja", hvad er dine yndlingsmuligheder?
Lad os dykke dybt ned i de tilgængelige muligheder:
- Sikkerhedskopiering og gendannelse
- Logforsendelse
- Databasespejling
- tredjepartsværktøjer
Sikkerhedskopiering og gendannelse
Sikkerhedskopier-og-gendan-databaseteknikken er den mest levedygtige mulighed for enhver databasemigrering. Hvis det er planlagt og testet korrekt, vil vi undgå mange uforudsete migreringsfejl. Vi ved alle, at sikkerhedskopieringen er en online-proces, det er nemt at starte backup af transaktionslog i tide for at indsnævre antallet af transaktioner, der skal leveres til den nye database. Under migreringsvinduet kan vi begrænse brugernes adgang til databasen og starte en sidste log backup og overføre den til destinationen. På den måde kan nedetiden forkortes markant.
Logforsendelse
Vi forstår alle vigtigheden af logfilerne i databaseverdenen. Logforsendelsesteknik tilbyder en god disaster recovery-løsning og understøtter begrænset skrivebeskyttet adgang til sekundære databaser i intervallet mellem gendannelsesjob. Det er i bund og grund et koncept om at sikkerhedskopiere transaktionsloggen og afspilles på en fuld backup på en mere sekundær database. Disse sekundære databaser er duplikerede kopier af den primære database og gendanner løbende sikkerhedskopiering af transaktionsloggen til deres egen kopi for at holde den synkroniseret med den primære database. Da den sekundære database er på separat hardware, i tilfælde af fejl i den primære af en eller anden grund, er den fuldt sikkerhedskopierede kopi af systemet umiddelbart tilgængelig til brug, og netværkstrafikken kan simpelthen omdirigeres til den sekundære server, uden at nogen brugere ved, at en fejl er opstået. Logforsendelse giver i de fleste tilfælde en nem og effektiv måde at styre migrationen i højere grad på.
Spejling
Database Mirroring er også en mulighed for databasemigrering, forudsat at både kilde og mål er af samme versioner og udgaver. Grundlæggende skaber spejling to duplikerede kopier af en database på to hardwareinstanser. Transaktioner vil forekomme på begge databaser samtidigt. Du har mulighed for at tage en produktionsdatabase offline, skifte over til den spejlede version af databasen og tillade brugere at fortsætte med at få adgang til dataene, som om intet var hændt. Med hensyn til implementeringen har vi at gøre med en hovedserver, en spejlserver og et vidne. Men det vil være en forældet funktion, og den vil blive fjernet fra fremtidige versioner af SQL Server.
Oversigt
I denne artikel diskuterede vi typerne af backups, Sikkerhedskopiering af transaktionslog i detaljer, datamigreringsstandarder, proces og strategi, lært at bruge SQL-teknikker til effektiv håndtering af datamigreringstrin.
Transaktionslogskrivningsmekanismen WAL sikrer, at transaktioner altid skrives til logfilen først. På denne måde garanterer SQL Server, at virkningerne af alle forpligtede transaktioner i sidste ende vil blive skrevet i datafilerne (til disk), og at eventuelle dataændringer på disken, der stammer fra ufuldstændige transaktioner, vil blive TILBAGE og ikke afspejles i datafilerne.
I de fleste tilfælde er forsinkelsen i datasynkronisering uforudset, og datatab er permanent. Oftere end ikke afhænger det hele af størrelsen af databasen og tilgængelig infrastruktur. Som en anbefalet praksis er det bedre at køre migreringer manuelt end som en del af implementeringen for at holde tingene adskilt, så output kan være mere forudsigeligt.
Personligt ville jeg foretrække logforsendelse af forskellige årsager:Du kan tage en fuld backup af dataene fra den gamle server i god tid, få dem over på den nye server, gendanne den og derefter anvende de resterende transaktioner (t-log backup ) fra punktet helt op til tidspunktet for cutover. Processen er faktisk ret enkel.
Databasemigration er ikke svært, hvis det gøres på den rigtige måde. Jeg håber, at dette indlæg hjælper dig med at køre databasemigreringerne på en mere smidig måde.