Databasebelastningsbalancering distribuerer samtidige klientanmodninger til flere databaseservere for at reducere mængden af belastning på en enkelt server. Dette kan forbedre ydeevnen af din database drastisk. Heldigvis kan MongoDB som standard håndtere flere klienters anmodninger om at læse og skrive de samme data samtidigt. Den bruger nogle samtidighedskontrolmekanismer og låseprotokoller for at sikre datakonsistens til enhver tid.
På denne måde sikrer MongoDB også, at alle klienter får et ensartet overblik over data til enhver tid. På grund af denne indbyggede funktion til håndtering af anmodninger fra flere klienter, behøver du ikke at bekymre dig om at tilføje en ekstern belastningsbalancer oven på dine MongoDB-servere. Selvom du stadig ønsker at forbedre ydeevnen af din database ved hjælp af belastningsbalancering, er her nogle måder at opnå det på.
MongoDB Lodret skalering
I enkle vendinger betyder lodret skalering, at du tilføjer flere ressourcer til din server, som skal håndteres for at indlæse. Som alle databasesystemer foretrækker MongoDB mere RAM og IO-kapacitet. Dette er den enkleste måde at booste MongoDB-ydeevnen på uden at sprede belastningen på tværs af flere servere. Vertikal skalering af MongoDB-databasen inkluderer typisk øget CPU-kapacitet eller diskkapacitet og øget gennemløb (I/O-operationer). Ved at tilføje flere ressourcer bliver din mongo-server mere i stand til at håndtere flere klienters anmodninger. Således bedre belastningsbalancering for din database.
Ulempen ved at bruge denne tilgang er den tekniske begrænsning ved at tilføje ressourcer til ethvert enkelt system. Alle cloud-udbydere har også begrænsningerne for at tilføje nye hardwarekonfigurationer. Den anden ulempe ved denne tilgang er et enkelt point of failure. I denne tilgang bliver alle dine data gemt i et enkelt system, hvilket kan føre til permanent tab af dine data.
MongoDB horisontal skalering
Horisontal skalering refererer til at opdele din database i bidder og gemme dem på flere servere. Den største fordel ved denne tilgang er, at du kan tilføje yderligere servere med det samme for at øge din databaseydeevne uden nedetid. MongoDB giver horisontal skalering gennem sharding. MongoDB-sharding giver yderligere kapacitet til at fordele skrivebelastningen på tværs af flere servere(shards). Her kan hvert shard ses som én selvstændig database, og samlingen af alle shards kan ses som én stor logisk database. Deling gør det muligt for din MongoDB at distribuere data på tværs af flere servere for at håndtere samtidige klientanmodninger effektivt. Derfor øger det din databases læse- og skrivegennemstrømning.
MongoDB Sharding
Et shard kan være en enkelt mongod-instans eller et replikasæt, der indeholder undersættet af mongo sharded-databasen. Du kan konvertere shard i replikasæt for at sikre høj tilgængelighed af data og redundans.
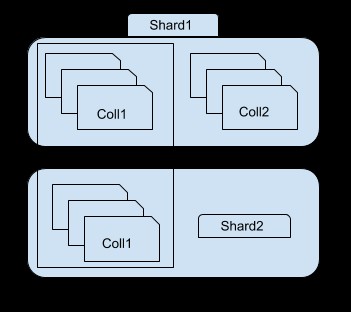
Som du kan se på ovenstående billede, indeholder shard 1 en delmængde af samling 1 og hele samling2, hvorimod shard 2 kun indeholder andre undergrupper af samling1. Du kan få adgang til hvert shard ved hjælp af mongos-instansen. Hvis du f.eks. opretter forbindelse til shard1-instans, vil du kun kunne se/få adgang til en undergruppe af collection1.
mongoerne
Mongos er forespørgselsrouteren, som giver adgang til sharded cluster til klientapplikationer. Du kan have flere mongo-forekomster for bedre belastningsbalancering. For eksempel kan du i din produktionsklynge have én mongos-instans for hver applikationsserver. Nu her kan du bruge en ekstern load balancer, som vil omdirigere din applikationsservers anmodning til passende mongos-instanser. Mens du tilføjer sådanne konfigurationer til din produktionsserver, skal du sørge for, at forbindelse fra enhver klient altid opretter forbindelse til den samme mongo-instans hver gang, da nogle mongo-ressourcer såsom markører er specifikke for mongo-instanser.
Konfigurationsservere
Konfigurationsservere gemmer konfigurationsindstillingerne og metadata om din klynge. Fra MongoDB version 3.4 skal du installere konfigurationsservere som et replikasæt. Hvis du aktiverer sharding i et produktionsmiljø, er det obligatorisk at bruge tre separate konfigurationsservere, hver på forskellige maskiner.
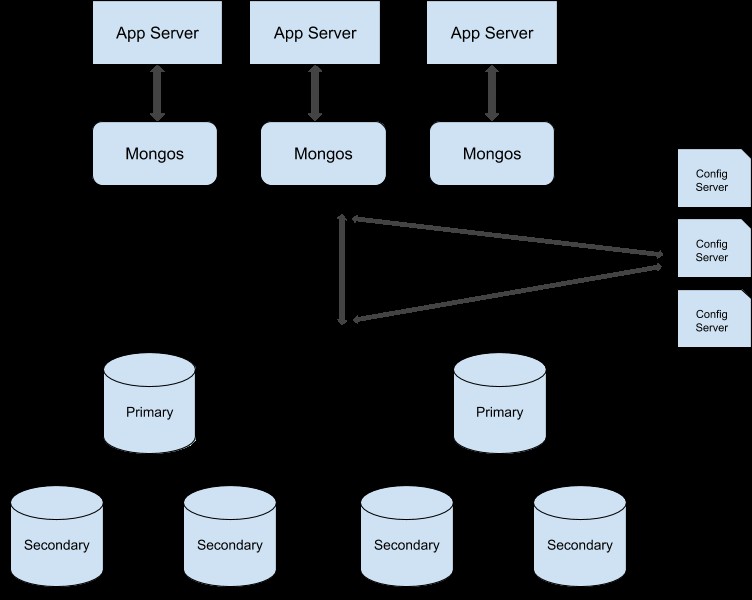
Du kan følge denne vejledning for at konvertere din replikasætklynge til en sønderdelt klynge. Her er eksempelillustrationen af sharded produktionsklynge:
MongoDB belastningsbalancering ved hjælp af replikering
Nogle gange kan MongoDB-replikering bruges til at håndtere mere trafik fra klienter og til at reducere belastningen på den primære server. For at gøre det kan du instruere klienter i at læse fra sekundære i stedet for den primære server. Dette kan reducere mængden af belastning på den primære server, da alle læseanmodninger, der kommer fra klienter, vil blive håndteret af sekundære servere, og den primære server vil kun tage sig af skriveanmodninger.
Følgende er kommandoen til at indstille læsepræferencen til sekundær:
db.getMongo().setReadPref('secondary')Du kan også angive nogle tags til at målrette mod specifikke sekundære under håndtering af læseforespørgslerne.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Her vil MongoDB forsøge at finde den sekundære node med datacenter-tagværdien som APAC. Hvis det findes, vil Mongo betjene læseanmodningerne fra alle sekundære med tagdatacenter:"APAC". Hvis den ikke findes, vil Mongo forsøge at finde sekundære med tagregion:"Øst". Hvis der stadig ikke findes nogen sekundærer, vil {} fungere som standardtilfældet, og Mongo vil betjene anmodningerne fra alle kvalificerede sekundære.
Denne tilgang til belastningsbalancering er dog ikke tilrådelig at bruge til at øge læsegennemstrømningen. Fordi enhver anden læsepræferencetilstand end primær kan returnere gamle data i tilfælde af nylige skriveopdateringer på den primære server. Normalt vil den primære server tage noget tid at håndtere skriveanmodningerne og udbrede ændringerne til sekundære servere. I løbet af denne tid, hvis nogen anmoder om læsning af de samme data, vil den sekundære server returnere forældede data, da de ikke er synkroniseret med den primære server. Du kan bruge denne tilgang, hvis din applikation er tunge læseoperationer i forhold til skriveoperationer.
Konklusion
Da MongoDB kan håndtere samtidige anmodninger af sig selv, er der ingen grund til at tilføje en belastningsbalancer i din MongoDB-klynge. Til belastningsbalancering af klientens anmodninger kan du vælge enten vertikal skalering eller horisontal skalering, da det ikke er tilrådeligt at bruge sekundære til at skalere dine læse- og skriveoperationer. Vertikal skalering kan ramme de tekniske grænser, som diskuteret ovenfor. Derfor er den velegnet til små applikationer. Til store applikationer er horisontal skalering gennem sharding den bedste tilgang til belastningsbalancering af læse- og skriveoperationer.