Organisationer gør brug af infrastruktur i skyen, fordi den tilbyder hastighed, fleksibilitet og skalerbarhed. Du kan forestille dig, at hvis vi kan oprette en ny databaseinstans med blot et klik, og det tager et par minutter, før den er klar, kan vi også implementere applikationen hurtigere end sammenlignet med on-prem-miljøer.
Medmindre du bruger MongoDBs egen cloud-tjeneste, tilbyder de store cloud-udbydere ikke en administreret MongoDB-tjeneste, så det er egentlig ikke en operation med et enkelt klik at implementere en enkelt instans eller klynge. Den almindelige måde er at opbygge VM'er og derefter installere dem på disse. Implementeringen skal tages hånd om fra A til Z - vi skal forberede instansen, installere databasesoftwaren, tune nogle konfigurationer og sikre instansen. Disse opgaver er væsentlige, selvom de ikke altid følges ordentligt - med potentielt katastrofale konsekvenser.
Automation spiller en vigtig rolle i at sikre, at alle opgaver starter fra installation, konfiguration, hærdning og indtil databasetjenesten er klar. I denne blog vil vi diskutere implementeringsautomatisering for MongoDB.
Software Orchestrator
Der er en masse nyt softwareværktøj til at hjælpe ingeniører med at implementere og administrere deres infrastruktur. Konfigurationsstyring hjælper ingeniører med at implementere hurtigere og effektivt, hvilket reducerer implementeringstiden for nye tjenester. Populære muligheder inkluderer Ansible, Saltstack, Chef og Puppet. Hvert produkt har fordele og ulemper, men de fungerer alle meget godt og er enormt populære. Implementering af en stateful service som et MongoDB ReplicaSet eller Sharded Cluster kan være lidt mere udfordrende, da disse er multi-server opsætninger, og værktøjerne har dårlig understøttelse af inkrementel og krydsknudekoordination. Implementeringsprocedurer kræver normalt orkestrering på tværs af noder, med opgaver udført i en bestemt rækkefølge.
MongoDB-implementeringsopgaver til automatisering
Deployering af en MongoDB-server involverer en række ting; tilføj MongoDB-lager til lokalt, installer MongoDB-pakken, konfigurer port, brugernavn og start tjenesten.
Opgave:Installer MongoDB
- name: install mongoDB
apt:
name: mongodb
state: present
update_cache: yes
Opgave:Kopier mongod.conf fra konfigurationsfilen.
- name: copy config file
copy:
src: mongodb.conf
dest: /etc/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbOpgave:Opret MongoDB-grænsekonfiguration:
- name: create /etc/security/limits.d/mongodb.conf
copy:
src: security-mongodb.conf
dest: /etc/security/limits.d/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbOpgave:Konfiguration af bytteforhold
- name: config vm.swappiness
sysctl:
name: vm.swappiness
value: '10'
state: presentOpgave:Konfigurer TCP Keepalive-tid
- name: config net.ipv4.tcp_keepalive_time
sysctl:
name: net.ipv4.tcp_keepalive_time
value: '120'
state: presentOpgave:Sørg for, at MongoDB automatisk starter
- name: Ensure mongodb is running and and start automatically on reboots
systemd:
name: mongodb
enabled: yes
state: startedVi kan kombinere alle disse opgaver i en enkelt afspilningsbog og køre afspilningsbogen for at automatisere implementeringen. Hvis vi kører en Ansible playbook fra konsollen:
$ ansible-playbook -b mongoInstall.ymlVi vil se udviklingen af implementeringen fra vores Ansible-script, outputtet skulle være noget som nedenfor:
PLAY [ansible-mongo] **********************************************************
GATHERING FACTS ***************************************************************
ok: [10.10.10.11]
TASK: [install mongoDB] *******************************************************
ok: [10.10.10.11]
TASK: [copy config file] ******************************************************
ok: [10.10.10.11]
TASK: [create /etc/security/limits.d/mongodb.conf]*****************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **************************************************
ok: [10.10.10.11]
TASK: [config net.ipv4.tcp_keepalive_time]*************************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **********************************************
ok: [10.10.10.11]
PLAY RECAP ********************************************************************
[10.10.10.11] : ok=6 changed=1 unreachable=0 failed=0Efter implementeringen kan vi tjekke MongoDB-tjenesten på målserveren.
Implementeringsautomatisering af MongoDB ved hjælp af ClusterControl GUI
Der er to måder at implementere MongoDB ved hjælp af ClusterControl. Vi kan bruge det fra dashboardet i ClusterControl, det er GUI-baseret og skal blot bruge 2 dialoger, indtil det udløser et nyt job til ny implementering af MongoDB.
Først skal vi udfylde SSH-brugeren og adgangskoden, udfylde klyngenavnet som vist nedenfor:
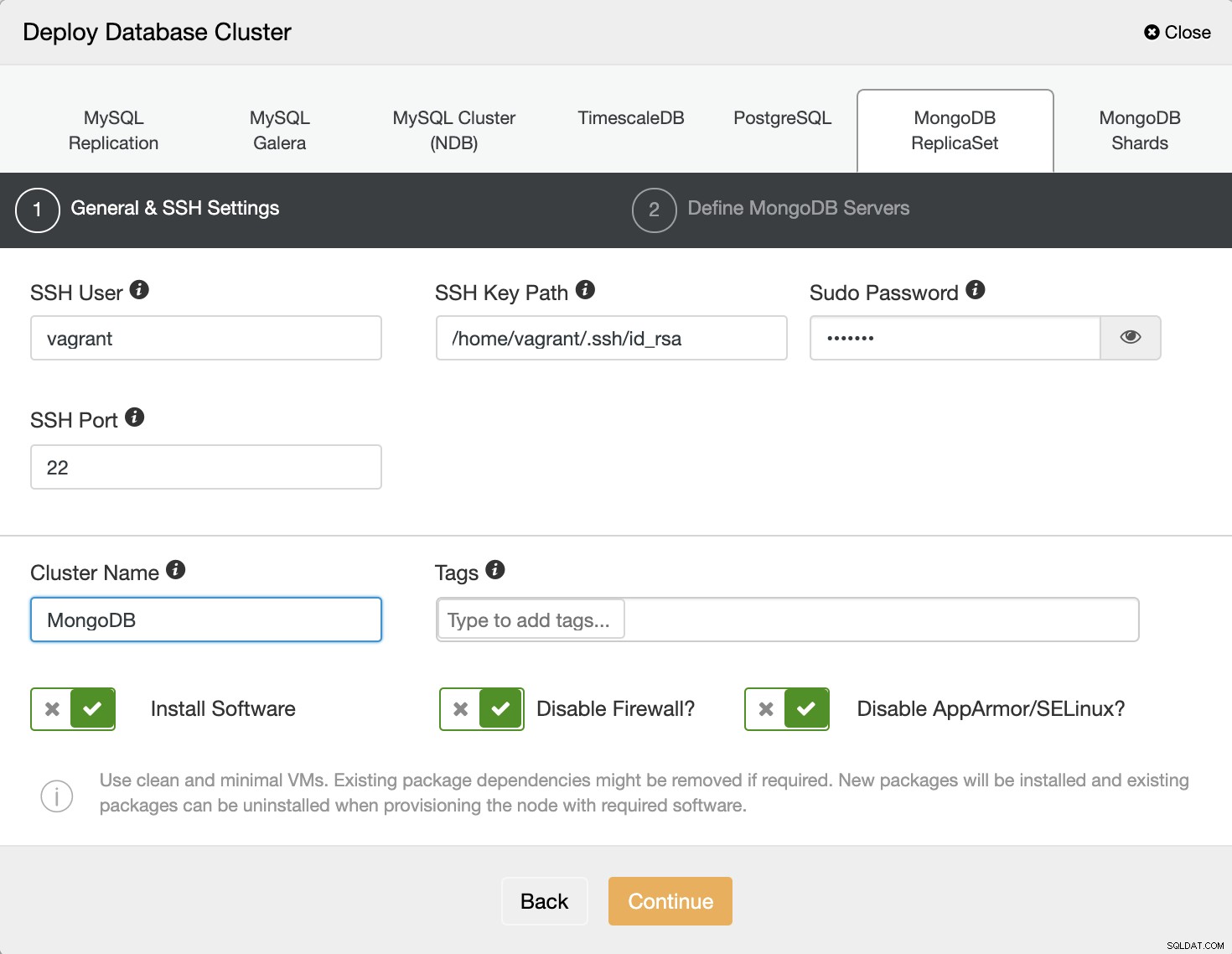
Og derefter skal du vælge leverandøren og versionen af MongoDB, definere brugeren og adgangskode, og det sidste er at udfylde mål-IP-adressen
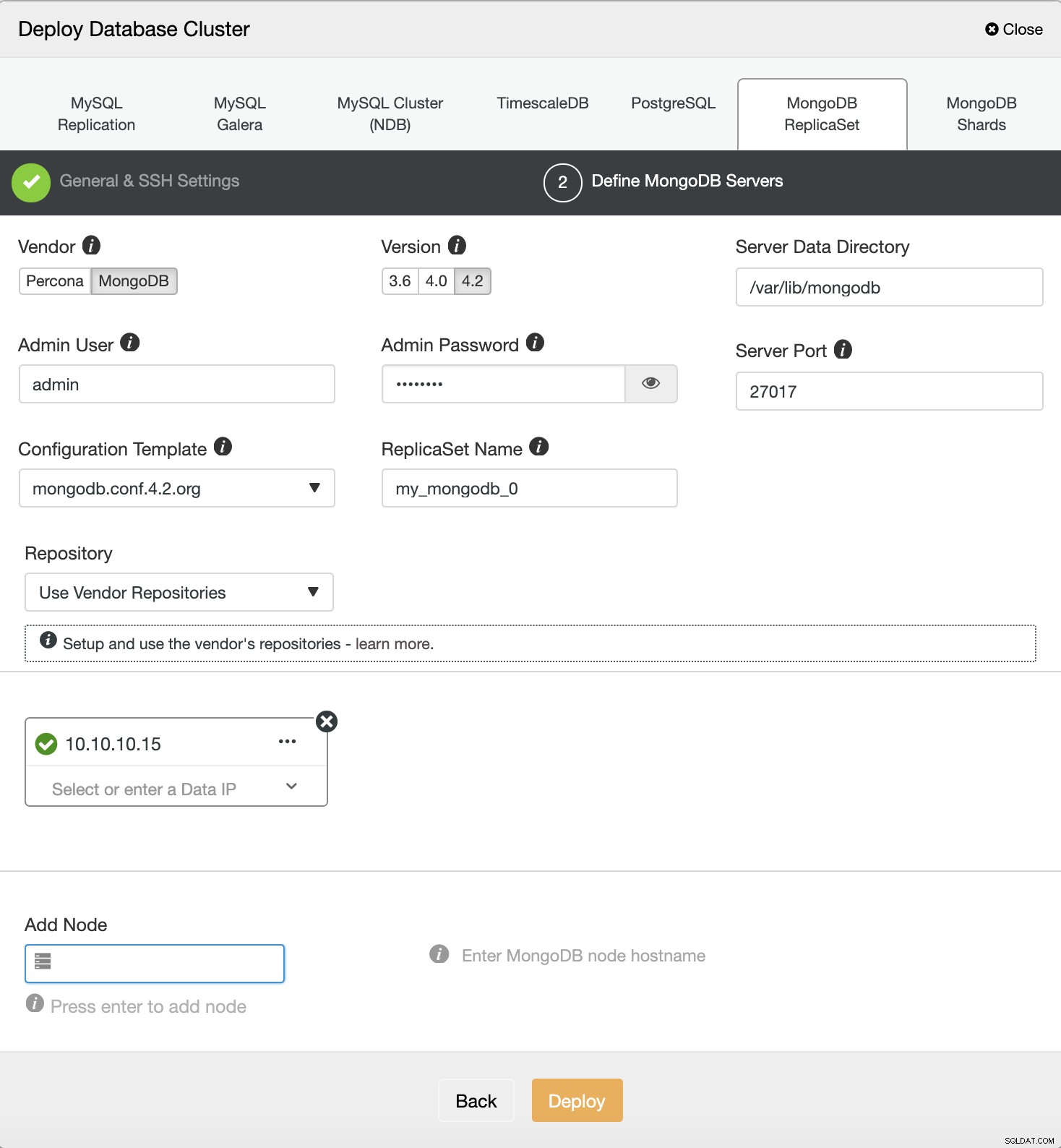
Implementeringsautomatisering af MongoDB ved hjælp af s9s CLI
Fra kommandolinjegrænsefladen kan man bruge s9s-værktøjerne. Implementeringen af MongoDB ved hjælp af s9s er kun en kommando på én linje som nedenfor:
$ s9s cluster --create --cluster-type=mongodb --nodes="10.10.10.15" --vendor=percona --provider-version=4.2 --db-admin-passwd="12qwaszx" --os-user=vagrant --cluster-name="MongoDB" --wait
Create Mongo Cluster
/ Job 183 FINISHED [██████████] 100% Job finished.
Så at implementere MongoDB, uanset om det er et ReplicaSet eller en Sharded Cluster, er meget let og er fuldstændig automatiseret af ClusterControl.