Vedligeholdelse er noget, som et driftsteam ikke kan undgå. Servere skal holde trit med den nyeste software, hardware og teknologi for at sikre, at systemerne er stabile og kører med den lavest mulige risiko, samtidig med at de gør brug af nyere funktioner til at forbedre den overordnede ydeevne.
Der er utvivlsomt en lang liste over vedligeholdelsesopgaver, der skal udføres af systemadministratorer, især når det kommer til kritiske systemer. Nogle af opgaverne skal udføres med jævne mellemrum, som dagligt, ugentligt, månedligt og årligt. Nogle skal gøres med det samme, omgående. Ikke desto mindre bør enhver vedligeholdelsesoperation ikke føre til endnu et større problem, og enhver vedligeholdelse skal håndteres med ekstra omhu for at undgå enhver afbrydelse af virksomheden.
At få tvivlsom tilstand og falske alarmer er almindeligt, mens vedligeholdelse er i gang. Dette forventes, fordi serveren i vedligeholdelsesperioden ikke vil fungere, som den skal være, før vedligeholdelsesopgaven er afsluttet. ClusterControl, den altomfattende administrations- og overvågningsplatform for dine open source-databaser, kan konfigureres til at forstå disse omstændigheder for at forenkle dine vedligeholdelsesrutiner uden at ofre de overvågnings- og automatiseringsfunktioner, den tilbyder.
Vedligeholdelsestilstand
ClusterControl introducerede vedligeholdelsestilstand i version 1.4.0, hvor du kan sætte en individuel node i vedligeholdelse, som forhindrer ClusterControl i at udløse alarmer og sende meddelelser i den angivne varighed. Vedligeholdelsestilstand kan konfigureres fra ClusterControl UI og også ved hjælp af ClusterControl CLI-værktøj kaldet "s9s". Fra brugergrænsefladen skal du bare gå til Noder -> vælg en node -> Nodehandlinger -> Planlæg vedligeholdelsestilstand :
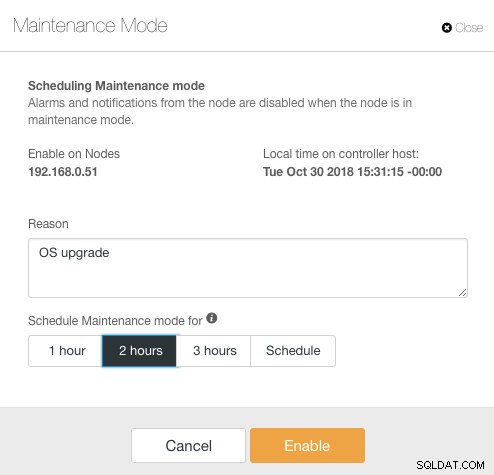
Her kan man indstille vedligeholdelsesperioden til en foruddefineret tid eller planlægge den derefter. Du kan også nedskrive årsagen til at planlægge opgraderingen, nyttig til revisionsformål. Du bør se følgende meddelelse, når vedligeholdelsestilstanden er aktiv:
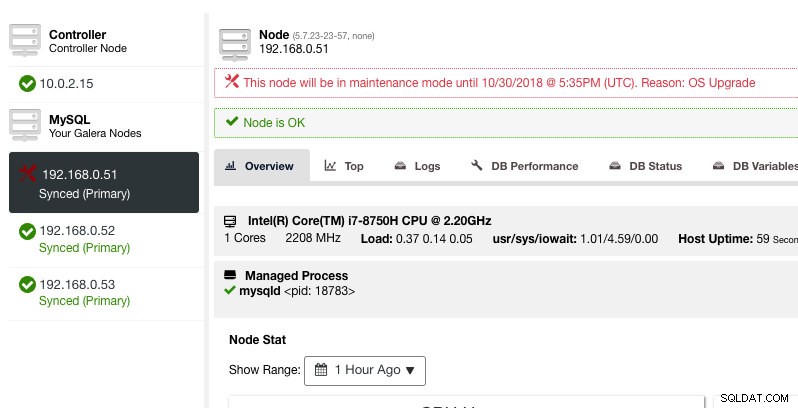
ClusterControl vil ikke forringe noden, derfor forbliver nodens tilstand, som den er, medmindre du udfører en handling, der ændrer tilstanden. Alarmer og meddelelser for denne node vil blive genaktiveret, når vedligeholdelsesperioden er overstået, eller operatøren deaktiverer den eksplicit ved at gå til Knudehandlinger -> Deaktiver vedligeholdelsestilstand .
Bemærk, at hvis automatisk nodegendannelse er aktiveret, vil ClusterControl altid gendanne en node uanset vedligeholdelsestilstandens status. Glem ikke at deaktivere gendannelse af noder for at undgå, at ClusterControl forstyrrer dine vedligeholdelsesopgaver. Dette kan gøres fra den øverste oversigtslinje.
Vedligeholdelsestilstanden kan også konfigureres via ClusterControl CLI eller "s9s". Du kan bruge kommandoen "s9s vedligeholdelse" til at liste og manipulere vedligeholdelsesperioderne. Følgende kommandolinje planlægger et vedligeholdelsesvindue på en time for node 192.168.1.121 i morgen:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."For flere detaljer og eksempler, se s9s vedligeholdelsesdokumentation.
Klyngedækkende vedligeholdelsestilstand
På tidspunktet for skrivningen skal vedligeholdelsestilstandskonfigurationen konfigureres pr. administreret node. For klyngedækkende vedligeholdelse skal man gentage planlægningsprocessen for hver administreret node i klyngen. Dette kan være upraktisk, hvis du har et højt antal noder i din klynge, eller hvis vedligeholdelsesintervallet er meget kort mellem to opgaver.
Heldigvis kan ClusterControl CLI (a.k.a s9s) bruges som en løsning for at overvinde denne begrænsning. Du kan bruge "s9s noder" til at liste ud og manipulere de administrerede noder i en klynge. Denne liste kan gentages for at planlægge en klyngedækkende vedligeholdelsestilstand på et givet tidspunkt ved hjælp af kommandoen "s9s maintenance".
Lad os se på et eksempel for at forstå dette bedre. Overvej følgende tre-node Percona XtraDB Cluster, som vi har:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Klyngen har i alt 4 noder - 3 databasenoder med en ClusterControl node. Den første kolonne, STAT, viser nodens rolle og status. Det første tegn er nodens rolle - "c" betyder controller og "g" betyder Galera database node. Antag, at vi kun ønsker at planlægge databasenoderne til vedligeholdelse, kan vi filtrere outputtet fra for at få værtsnavnet eller IP-adressen, hvor den rapporterede STAT har "g" i begyndelsen:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Med en simpel iteration kan vi derefter planlægge et klyngedækkende vedligeholdelsesvindue for hver node i klyngen. Følgende kommando gentager vedligeholdelsesoprettelse baseret på alle IP-adresser fundet i klyngen ved hjælp af en for-løkke, hvor vi planlægger at starte vedligeholdelsesoperationen samme tid i morgen og afslutte en time senere:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bDu bør se en udskrift af 3 UUID'er, den unikke streng, der identificerer hver vedligeholdelsesperiode. Vi kan derefter bekræfte med følgende kommando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Fra ovenstående output fik vi en liste over planlagte vedligeholdelsestider for hver databaseknude. I løbet af det planlagte tidspunkt vil ClusterControl hverken udløse alarmer eller udsende besked, hvis den finder uregelmæssigheder i klyngen.
Gentagelse af vedligeholdelsestilstand
Nogle vedligeholdelsesrutiner skal udføres med jævne mellemrum, f.eks. backup, husholdning og oprydningsopgaver. Under vedligeholdelsestiden forventer vi, at serveren opfører sig anderledes. Men enhver servicefejl, midlertidig utilgængelighed eller høj belastning ville helt sikkert forårsage kaos for vores overvågningssystem. For hyppige og korte vedligeholdelsesintervaller kan dette vise sig at være meget irriterende, og at springe de hævede falske alarmer over kan give dig en bedre søvn i løbet af natten.
Aktivering af vedligeholdelsestilstand kan dog også udsætte serveren for en større risiko, da streng overvågning ignoreres i tidsrummet. Derfor er det nok en god idé at forstå arten af den vedligeholdelsesoperation, som vi gerne vil udføre, før du aktiverer vedligeholdelsestilstanden. Følgende tjekliste skulle hjælpe os med at bestemme vores politik for vedligeholdelsestilstand:
- Berørte noder - Hvilke noder er involveret i vedligeholdelsen?
- Konsekvenser - Hvad sker der med noden, når vedligeholdelsesoperationen er i gang? Vil den være utilgængelig, højbelastet eller genstartet?
- Varighed – Hvor lang tid tager vedligeholdelsesoperationen at fuldføre?
- Frekvens - Hvor hyppigt skal vedligeholdelsesoperationen køre?
Lad os sætte det ind i en use case. Overvej, at vi har en Percona XtraDB-klynge med tre knudepunkter med en ClusterControl-knude. Det antages, at vores servere alle kører på virtuelle maskiner, og VM-sikkerhedskopieringspolitikken kræver, at alle VM'er sikkerhedskopieres hver dag fra kl. 1:00, én node ad gangen. Under denne sikkerhedskopiering vil noden blive fastfrosset i maks. 10 minutter, og den node, som styres og overvåges af ClusterControl, vil være utilgængelig, indtil sikkerhedskopieringen er færdig. Fra et Galera Cluster-perspektiv bringer denne operation ikke hele klyngen ned, da klyngen forbliver i kvorum, og den primære komponent er ikke påvirket.
Ud fra arten af vedligeholdelsesopgaven kan vi opsummere den som følgende:
- Berørte noder - Alle noder for klynge ID 1 (3 databasenoder og 1 ClusterControl node).
- Konsekvens – VM'en, der sikkerhedskopieres, vil være utilgængelig, indtil den er færdig.
- Varighed – Hver VM-sikkerhedskopi tager omkring 5 til 10 minutter at fuldføre.
- Frekvens – VM-sikkerhedskopien er planlagt til at køre dagligt, startende fra kl. 01:00 på den første node.
Vi kan derefter komme ud med en udførelsesplan for at planlægge vores vedligeholdelsestilstand:
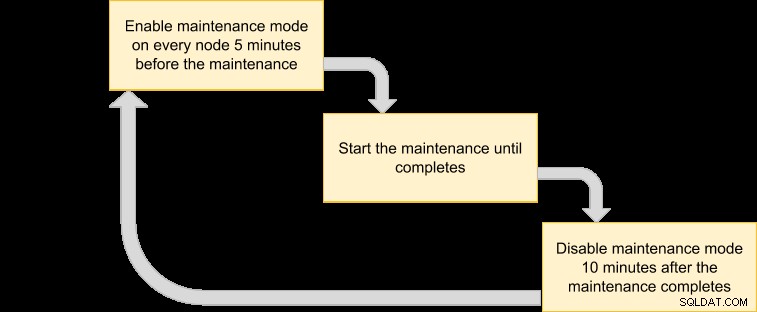
Da vi ønsker, at alle noder i klyngen skal sikkerhedskopieres af VM-manageren, skal du blot liste noderne for det tilsvarende klynge-id:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Ovenstående output kan bruges til at planlægge vedligeholdelse på tværs af hele klyngen. For eksempel, hvis du kører følgende kommando, vil ClusterControl aktivere vedligeholdelsestilstand for alle noder under klynge ID 1 fra nu og frem til de næste 50 minutter:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneVed at bruge ovenstående kommando kan vi konvertere den til en udførelsesfil ved at sætte den ind i et script. Opret en fil:
$ vim /usr/local/bin/enable_maintenance_modeOg tilføj følgende linjer:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneGem det, og sørg for, at filtilladelsen er eksekverbar:
$ chmod 755 /usr/local/bin/enable_maintenance_modeBrug derefter cron til at planlægge, at scriptet skal køre fra 5 minutter til 01:00 dagligt, lige før VM-sikkerhedskopieringen starter kl. 01:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeGenindlæs cron-dæmonen for at sikre, at vores script står i kø:
$ systemctl reload crond # or service crond reloadDet er det. Vi kan nu udføre vores daglige vedligeholdelse uden at blive ramt af falske alarmer og e-mailmeddelelser, indtil vedligeholdelsen er fuldført.
Bonusvedligeholdelsesfunktion - Spring over gendannelse af noder
Med automatisk gendannelse aktiveret, er ClusterControl smart nok til at registrere en knudefejl og vil forsøge at genoprette en mislykket knude efter en 30-sekunders henstandsperiode, uanset vedligeholdelsestilstandens status. Vidste du, at ClusterControl kan konfigureres til bevidst at springe over nodegendannelse for en bestemt node? Dette kan være meget nyttigt, når du skal udføre en akut vedligeholdelse uden at kende tidsperioden og resultatet af vedligeholdelsen.
Forestil dig f.eks. en korruption af filsystemet, og filsystemkontrol og reparation er påkrævet efter en hård genstart. Det er svært på forhånd at afgøre, hvor meget tid det vil tage at gennemføre denne operation. Således kan vi simpelthen bruge en flagfil til at signalere ClusterControl om at springe gendannelse over for noden.
Tilføj først følgende linje inde i /etc/cmon.d/cmon_X.cnf (hvor X er klynge-id'et) på ClusterControl-noden:
node_recovery_lock_file=/root/do_not_recoverGenstart derefter cmon-tjenesten for at indlæse ændringen:
$ systemctl restart cmon # service cmon restartSørg endelig for, at den angivne fil er til stede på den node, som vi vil springe over til ClusterControl-gendannelse:
$ touch /root/do_not_recoverUanset status for automatisk gendannelse og vedligeholdelsestilstand, vil ClusterControl kun gendanne noden, når denne flagfil ikke eksisterer. Administratoren er derefter ansvarlig for at oprette og fjerne filen på databasenoden.
Det var det, folkens. God vedligeholdelse!