SCUMM (Severalnines ClusterControl Unified Monitoring &Management) er en agentbaseret løsning med agenter installeret på databasenoderne. Det giver et sæt overvågningsdashboards, der har Prometheus som datalageret med dets elastiske forespørgselssprog og multidimensionelle datamodel. Prometheus skraber metriske data fra eksportører, der kører på databaseværterne.
ClusterControl SCUMM-arkitekturen blev introduceret med version 1.7.0, der udvider overvågningsfunktionaliteten til MySQL, Galera Cluster, PostgreSQL og ProxySQL.
Den nye ClusterControl 1.7.1 tilføjer højopløsningsovervågning til MongoDB-systemer.
 ClusterControl MongoDB dashboardliste
ClusterControl MongoDB dashboardliste I denne artikel vil vi beskrive de to vigtigste dashboards til MongoDB-miljøer. MongoDB Server og MongoDB Replicaset.
Dashboard og metrics List
Listen over dashboards og deres metrics:
| MongoDB Server | |
|---|---|
| Navn ReplSet Name Serveroppetid OpsCounters Forbindelser WT - Concurrent Tickets (Læs) WT - Concurrent Tickets (Write) WT - Cache Global Lock Asserts |
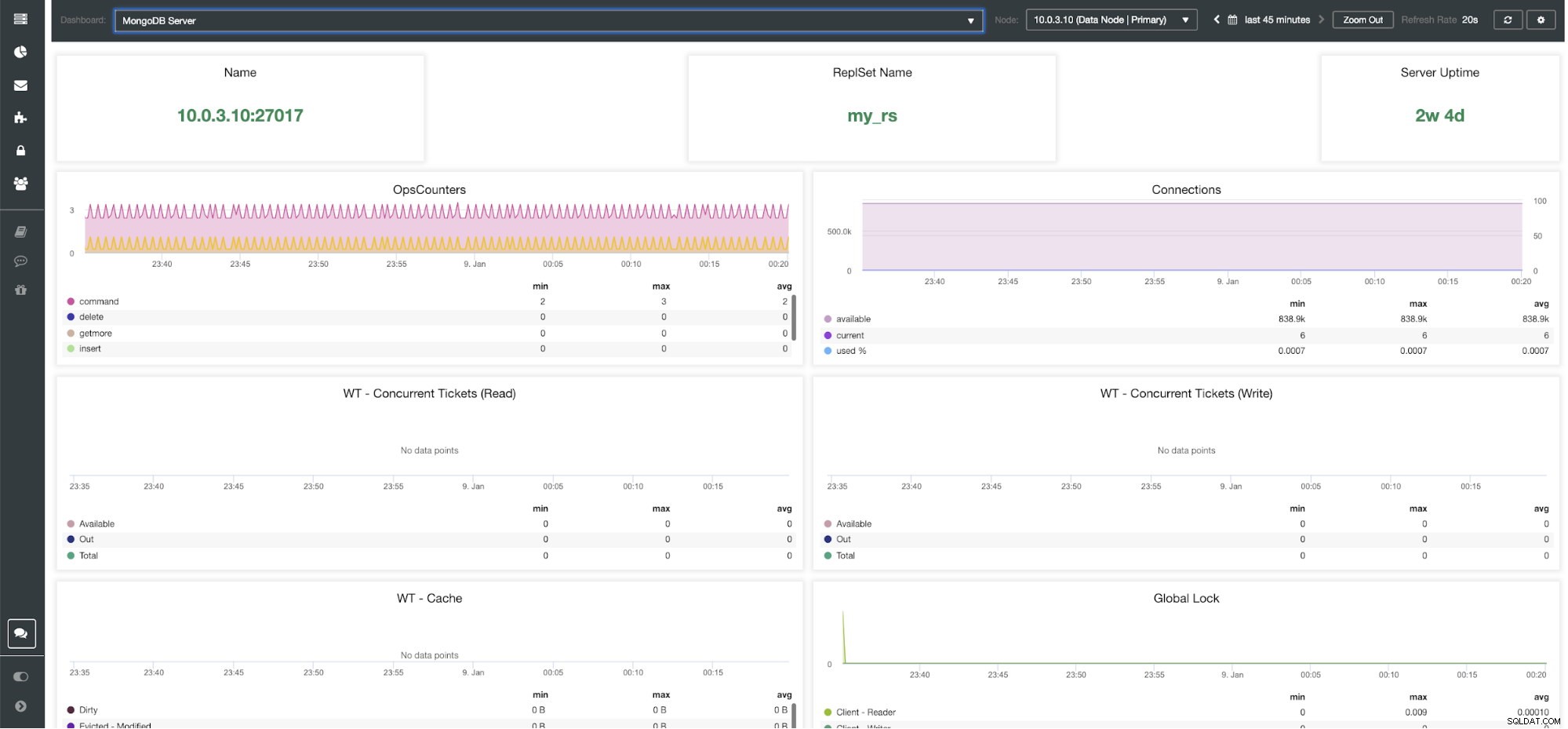 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| ReplSet Size ReplSet Name PRIMÆR Serverversion Replikasæt og medlemmer Oplog-vindue pr. replsæt Replikeringshøjde I alt PRIMÆR/SEKUNDÆR online pr. replsæt Åbn markører pr. replSet ReplSet - Timed-out markører pr. sæt Maks. replikeringsforsinkelse pr. replsæt Oplogstørrelse OpsCounters Ping tid til at replika sæt medlemmer fra PRIMÆR(er) |
 ClusterControl MongoDB ReplicaSet Dashboard
ClusterControl MongoDB ReplicaSet Dashboard Databasesystemer er stærkt afhængige af OS-ressourcer, så du kan også finde to ekstra dashboards til systemoversigt og klyngeoversigt over dit MongoDB-miljø.
| Systemoversigt | |
|---|---|
| Serveroppetid CPU-kerner Samlet RAM Gennemsnitlig belastning CPU-forbrug RAM-forbrug Brug af diskplads Netværksbrug Disk IOPS Disk IO Util % Disk Throughput |
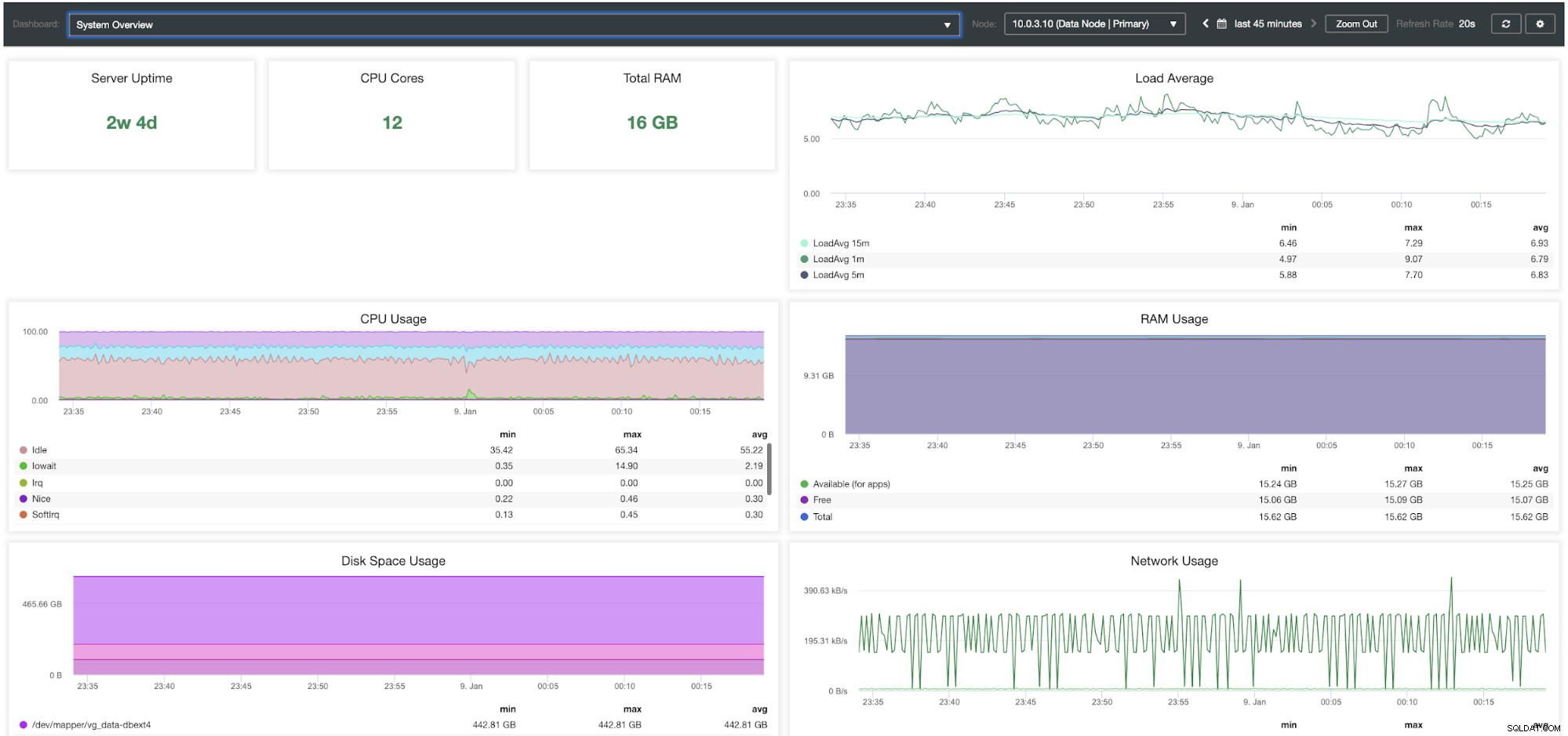 ClusterControl System Oversigt Dashboard
ClusterControl System Oversigt Dashboard| Klyngeoversigt | |
|---|---|
| Belastningsgennemsnit 1m Belastningsgennemsnit 5m Belastningsgennemsnit 15m Hukommelse tilgængelig for applikationer Network TX Network RX Disk Read IOPS Diskskrivning IOPS Diskskrivning + Læs IOPS |
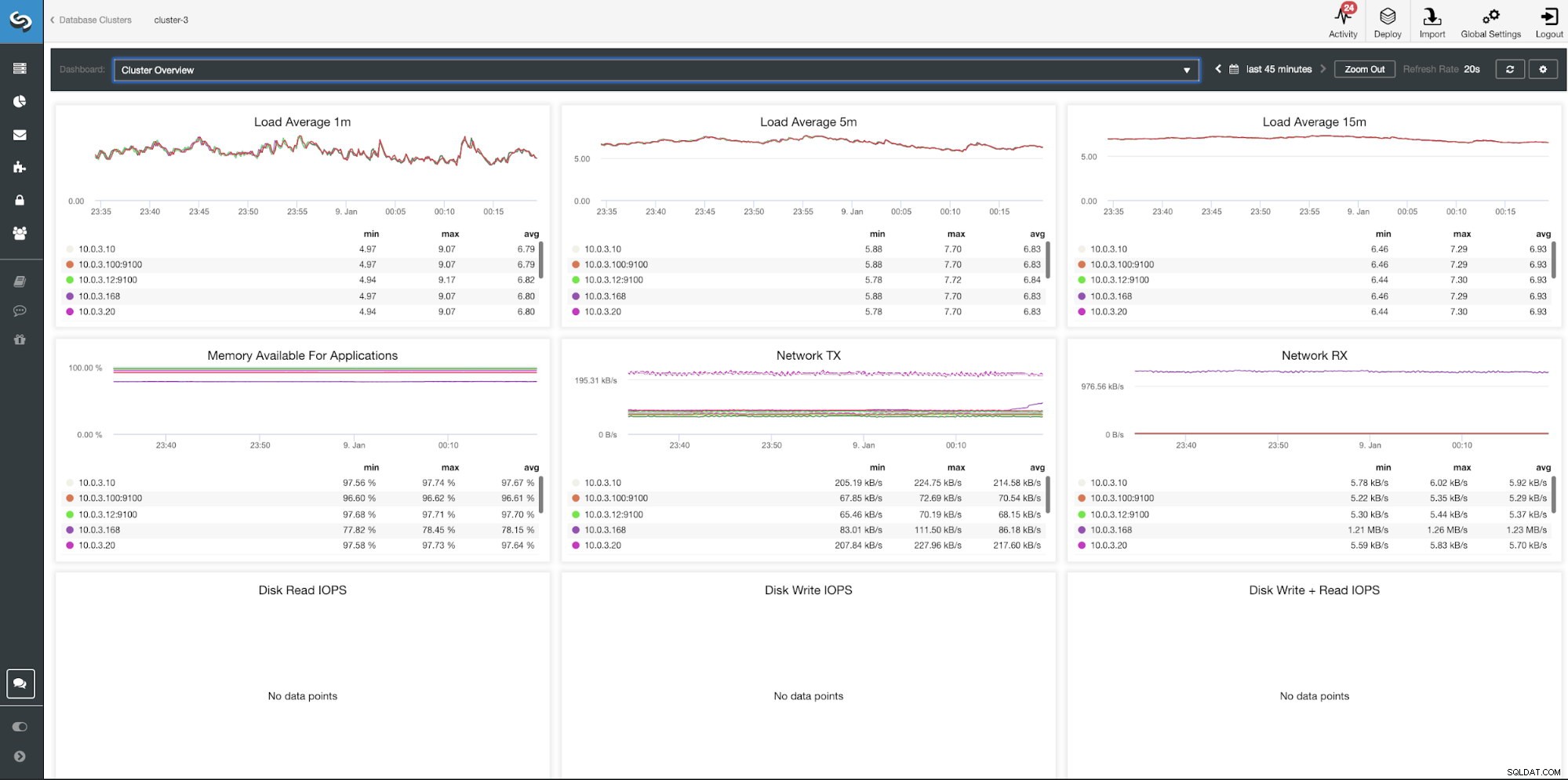 ClusterControl Cluster Oversigt Dashboard
ClusterControl Cluster Oversigt Dashboard MongoDB Server Dashboard
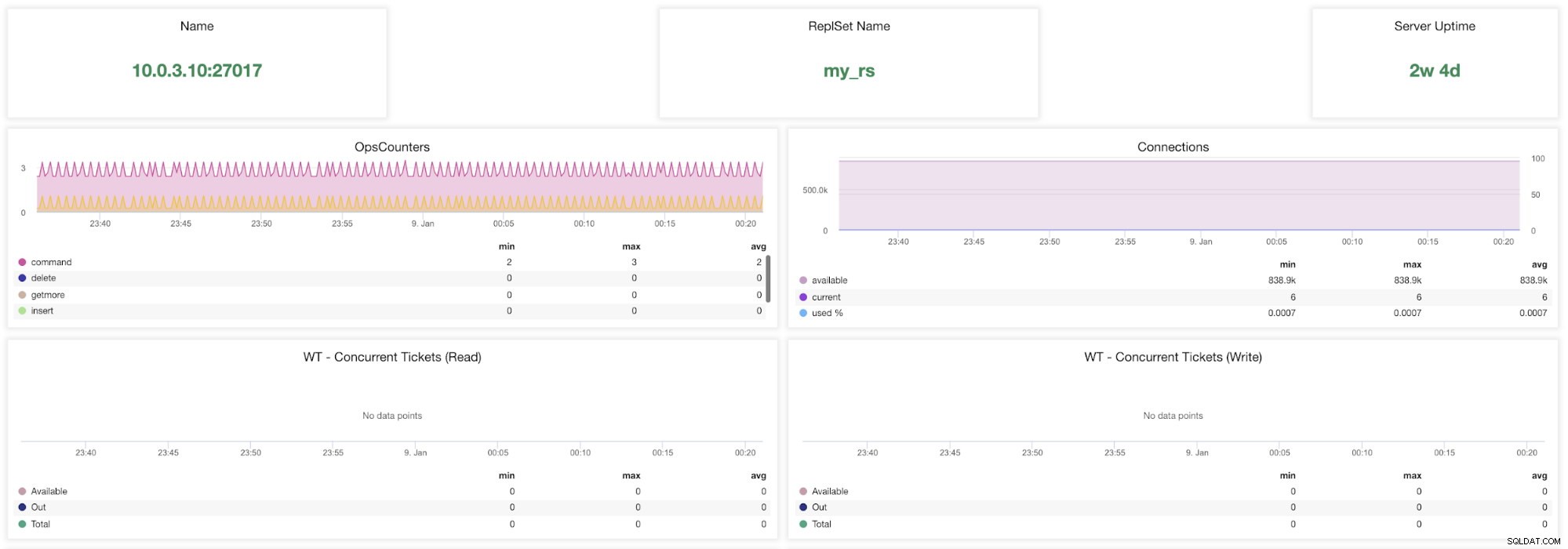 ClusterControl MongoDB-metrics
ClusterControl MongoDB-metrics Navn - Serveradresse og porten.
ReplsSet Name - Præsenterer navnet på det replikasæt, hvor serveren tilhører.
Serveroppetid - Tid siden sidste servergenstart.
Ops Couters - Antal anmodninger modtaget i løbet af den valgte tidsperiode opdelt efter typen af operation. Disse optællinger inkluderer alle modtagne operationer, inklusive dem, der ikke var succesfulde.
Forbindelser - Denne graf viser en af de vigtigste målinger at se - antallet af forbindelser modtaget i løbet af den valgte tidsperiode inklusive mislykkede anmodninger. Unormal trafikbelastning kan føre til ydeevneproblemer. Hvis MongoDB løber tør for forbindelser, er den muligvis ikke i stand til at håndtere indgående anmodninger rettidigt.
WT - samtidige billetter (læs) / WT - samtidige billetter (skriv) Disse to grafer viser læse- og skrivebilletter, som kontrollerer samtidighed i WiredTiger (WT). WT-billetter styrer, hvor mange læse- og skriveoperationer, der kan udføres på lagermotoren på samme tid. Når tilgængelige læse- og skrivebilletter falder til nul, er antallet af samtidige kørende operationer lig med de konfigurerede læse-/skriveværdier. Dette betyder, at alle andre operationer skal vente, indtil en af de kørende tråde afslutter sit arbejde på lagermotoren, før de udføres.
 ClusterControl MongoDB-metrics
ClusterControl MongoDB-metrics WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - Størrelsen på cachen er den vigtigste knap for WiredTiger. Som standard reserverer MongoDB 3.x 50 % (60 % i 3.2) af den tilgængelige hukommelse til sin datacache.
Global lås (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Dårlige skemadesignmønstre eller tunge læse- og skriveanmodninger fra mange klienter kan forårsage omfattende låsning. Når dette sker, er der behov for at opretholde konsistens og undgå skrivekonflikter.
For at opnå dette bruger MongoDB multi-granularity-locking, som gør det muligt at låse operationer på forskellige niveauer, såsom et globalt, database- eller samlingsniveau .
påstande (msg, regular, rollovers, user) - Denne graf viser antallet af asserts, der hæves hvert sekund. Høje værdier og afvigelser fra trends bør gennemgås.
MongoDB ReplicaSet Dashboard
De metrics, der vises i dette dashboard, har kun betydning, hvis du bruger et replikasæt.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Replikasætstørrelse - Antallet af medlemmer i replikasættet. Standardimplementeringen af replikasæt til produktionssystemet er et replikasæt med tre medlemmer. Generelt anbefales det, at et replikasæt har et ulige antal stemmeberettigede medlemmer. Fejltolerance for et replikasæt er antallet af medlemmer, der kan blive utilgængelige og stadig efterlade nok medlemmer i sættet til at vælge en primær. Fejltolerancen for tre medlemmer er én, for fem er det to osv.
ReplSet Name - Det er det navn, der er tildelt i MongoDB-konfigurationsfilen. Navnet refererer til /etc/mongod.conf replSet-værdi.
PRIMÆR - Den primære node modtager alle skriveoperationer og registrerer alle andre ændringer af sit datasæt i sin operationslog. Værdien er til at identificere IP-adressen og porten for din primære node i MongoDB replikasæt-klyngen.
Serverversion - Identificer serverversionen. ClusterControl version 1.7.1 understøtter MongoDB version 3.2/3.4/3.6/4.0.
Replikasæt og medlemmer (min, max, avg) - Denne graf kan hjælpe dig med at identificere aktive medlemmer over tidsperioden. Du kan spore minimum-, maksimum- og gennemsnitsantallet af primære og sekundære noder, og hvordan disse tal ændrede sig over tid. Enhver afvigelse kan påvirke fejltolerance og klyngens tilgængelighed.
Oplog-vindue pr. replsæt - Replikeringsvinduet er et vigtigt mål at se. MongoDB-oploggen er en enkelt samling, der er blevet begrænset i en (forudindstillet) størrelse. Det kan beskrives som forskellen mellem det første og det sidste tidsstempel i oplog.rs. Det er den tid, en sekundær kan være offline, før indledende synkronisering er nødvendig for at synkronisere forekomsten. Disse målinger fortæller dig, hvor meget tid du har tilbage, før vores næste transaktion slettes fra oploggen.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Replikeringshøjde - Denne graf viser forskellen mellem den primære oplog-vindue og replikeringsforsinkelsen for de sekundære noder. MongoDB-oploggen er begrænset i størrelse, og hvis noden halter for langt, vil den ikke være i stand til at indhente det. Hvis dette sker, vil der blive udstedt fuld synkronisering, og dette er en dyr operation, som til enhver tid skal undgås.
I alt PRIMÆR/SEKUNDÆR online pr. ReplSet - Samlet antal klynge noder over tidsperioden.
Åbne markører pr. replsæt (fastgjort, timeout, i alt) - En læseanmodning kommer med en markør, som er en pegepind til datasættet for resultatet. Den forbliver åben på serveren og forbruge derfor hukommelse, medmindre den afsluttes af standard MongoDB-indstillingen. Du bør identificere ikke-aktive markører og skære dem af for at spare på hukommelsen.
ReplSet - Timeout-markører pr. SetsMax Replikeringsforsinkelse pr. ReplSet - Replikeringsforsinkelse er meget vigtig at holde øje med, hvis du skalerer læsninger ud ved at tilføje flere sekundære. MongoDB vil kun bruge disse sekundære, hvis de ikke halter for langt bagud. Hvis den sekundære har replikeringsforsinkelse, risikerer du at udlevere forældede data, der allerede er blevet overskrevet på den primære.
OplogSize - Visse arbejdsbelastninger kan kræve større oplogstørrelse. Opdateringer til flere dokumenter på én gang, sletninger svarer til den samme mængde data som en indsættelse eller det betydelige antal opdateringer på stedet.
OpsConters - Denne graf viser antallet af udførelser af forespørgsler.
Ping tid til at replika sæt medlem fra primært - Dette lader dig opdage replikasætmedlemmer, der er nede eller ikke kan nås fra den primære node.
Afsluttende bemærkninger
Den nye ClusterControl 1.7.1 MongoDB dashboard-funktion er tilgængelig i Community Edition gratis. Databaseoperationsteams kan drage fordel af det ved at bruge graferne i høj opløsning, især når de udfører deres daglige rutiner som årsagsanalyser og kapacitetsplanlægning.
Det er kun et spørgsmål om et enkelt klik for at implementere nye overvågningsagenter. ClusterControl installerer Prometheus-agenter, konfigurerer metrikker og bevarer adgang til Prometheus-eksportørers konfiguration via dens GUI, så du bedre kan administrere parameterkonfiguration som samlerflag for eksportørerne (Prometheus).
Ved tilstrækkeligt at overvåge antallet af læse- og skriveanmodninger kan du forhindre ressourceoverbelastning, hurtigt finde årsagen til potentielle overbelastninger og vide, hvornår du skal skalere op.