Automatisk failover for MySQL-replikering har været genstand for debat i mange år.
Er det en god ting eller en dårlig ting?
For dem med lang hukommelse i MySQL-verdenen husker de måske GitHub-udfaldet i 2012, som hovedsageligt var forårsaget af software, der tog de forkerte beslutninger.
GitHub var så lige migreret til en kombination af MySQL Replication, Corosync, Pacemaker og Percona Replication Manager. PRM besluttede at lave en failover efter fejlende sundhedstjek på masteren, som blev overbelastet under en skemamigrering. En ny master blev valgt, men den klarede sig dårligt på grund af kolde caches. Den høje forespørgselsbelastning fra det travle sted fik PRM-hjerteslag til at fejle igen på den kolde master, og PRM udløste derefter endnu en failover til den oprindelige master. Og problemerne fortsatte bare, som opsummeret nedenfor.
 Kilde:Henrik Ingo &Massimo Brignoli’s på Percona Live 2013
Kilde:Henrik Ingo &Massimo Brignoli’s på Percona Live 2013 Spol et par år frem, og GitHub er tilbage med en ret sofistikeret ramme til styring af MySQL-replikering og automatiseret failover! Som Shlomi Noach udtrykker det:
"Til den effekt anvender vi automatiserede master failovers. Den tid, det ville tage et menneske at vågne op og rette op på en mislykket mester, er ud over vores forventning om tilgængelighed, og at betjene en sådan failover er nogle gange ikke-trivielt. Vi forventer, at masterfejl automatisk bliver opdaget og gendannet inden for 30 sekunder eller mindre, og vi forventer, at failover vil resultere i minimalt tab af tilgængelige værter."
De fleste virksomheder er ikke GitHub, men man kan argumentere for, at ingen virksomhed kan lide afbrydelser. Afbrydelser er forstyrrende for enhver virksomhed, og de koster også penge. Mit gæt er, at de fleste virksomheder derude nok ønskede, at de havde en form for automatiseret failover, og grundene til ikke at implementere det er sandsynligvis kompleksiteten af de eksisterende løsninger, manglende kompetence til at implementere sådanne løsninger eller manglende tillid til software at tage sådan en vigtig beslutning.
Der er en række automatiserede failover-løsninger derude, inklusive (og ikke begrænset til) MHA, MMM, MRM, mysqlfailover, Orchestrator og ClusterControl. Nogle af dem har været på markedet i en årrække, andre er nyere. Det er et godt tegn, flere løsninger betyder, at markedet er der, og folk forsøger at løse problemet.
Da vi designede automatisk failover i ClusterControl, brugte vi nogle få vejledende principper:
-
Sørg for, at masteren virkelig er død, før du failover
I tilfælde af en netværkspartition, hvor failover-softwaren mister kontakten med masteren, vil den stoppe med at se den. Men masteren fungerer muligvis godt og kan ses af resten af replikeringstopologien.
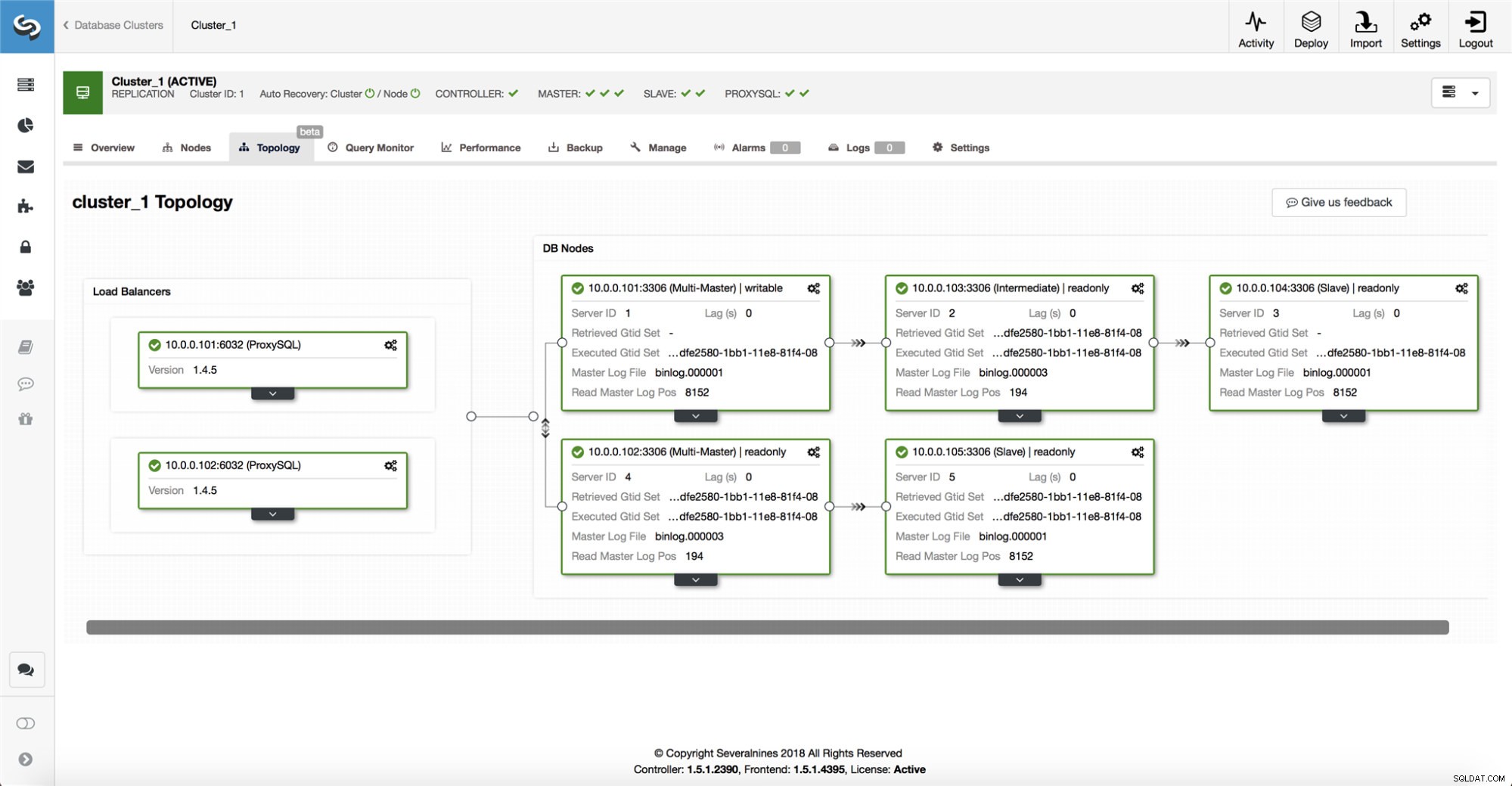
ClusterControl indsamler information fra alle databasenoder såvel som alle anvendte databaseproxyer/belastningsbalancere, og bygger derefter en repræsentation af topologien. Det vil ikke forsøge en failover, hvis slaverne kan se masteren, og heller ikke hvis ClusterControl ikke er 100 % sikker på masterens tilstand.
ClusterControl gør det også nemt at visualisere topologien af opsætningen, samt status for de forskellige noder (dette er ClusterControls forståelse af systemets tilstand baseret på den information, det indsamler).
-
Failover kun én gang
Der er skrevet meget om flapning. Det kan blive meget rodet, hvis tilgængelighedsværktøjet beslutter sig for at lave flere failovers. Det er en farlig situation. Hver mester valgt, uanset hvor kort den periode den havde mesterrollen, kan have deres egne sæt ændringer, som aldrig blev replikeret til nogen server. Så du kan ende med inkonsekvens på tværs af alle de valgte mestre.
-
Undgå failover til en inkonsekvent slave
Når vi vælger en slave, der skal promoveres som master, sikrer vi, at slaven ikke har uoverensstemmelser, f.eks. fejlagtige transaktioner, da dette meget vel kan bryde replikering.
-
Skriv kun til masteren
Replikering går fra masteren til slaven(erne). At skrive direkte til en slave ville skabe et divergerende datasæt, og det kan være en potentiel kilde til problemer. Vi indstiller slaverne til read_only og super_read_only i nyere versioner af MySQL eller MariaDB. Vi anbefaler også brugen af en belastningsbalancer, f.eks. ProxySQL eller MaxScale, for at afskærme applikationslaget fra den underliggende databasetopologi og eventuelle ændringer af den. Loadbalanceren gennemtvinger også skrivninger på den aktuelle master.
-
Gendan ikke automatisk den mislykkede master
Hvis masteren har fejlet, og en ny master er blevet valgt, vil ClusterControl ikke forsøge at genoprette den mislykkede master. Hvorfor? Denne server kan have data, der endnu ikke er blevet replikeret, og administratoren skal foretage en undersøgelse af fejlen. Ok, du kan stadig konfigurere ClusterControl til at slette dataene på den mislykkede master og få den til at blive en slave til den nye master - hvis du er ok med at miste nogle data. Men som standard vil ClusterControl lade den mislykkede master være, indtil nogen ser på den og beslutter sig for at genindføre den i topologien.
Så skal du automatisere failover? Det afhænger af, hvordan du har konfigureret replikering. Cirkulære replikeringsopsætninger med flere skrivebare mastere eller komplekse topologier er sandsynligvis ikke gode kandidater til automatisk failover. Vi vil holde os til ovenstående principper, når vi designer en replikeringsløsning.
På PostgreSQL
Når det kommer til PostgreSQL streaming replikering, bruger ClusterControl lignende principper til at automatisere failover. For PostgreSQL understøtter ClusterControl både asynkrone og synkrone replikeringsmodeller mellem masteren og slaverne. I begge tilfælde og i tilfælde af svigt vælges slaven med de mest opdaterede data som ny master. Mislykkede mastere bliver ikke automatisk gendannet/rettet for at slutte sig til replikeringsopsætningen igen.
Der er truffet et par beskyttelsesforanstaltninger for at sikre, at den fejlslagne master er nede og bliver nede, f.eks. den fjernes fra belastningsbalanceringssættet i proxyen og den dræbes, hvis f.eks. brugeren genstarter den manuelt. Det er lidt mere udfordrende der at opdage netværksopdelinger mellem ClusterControl og masteren, da slaverne ikke giver nogen information om status for masteren, de replikerer fra. Så en proxy foran databaseopsætningen er vigtig, da den kan give en anden sti til masteren.
På MongoDB
MongoDB-replikering i et replikasæt via oploggen ligner meget binlog-replikering, så hvordan kommer MongoDB automatisk til at genoprette en mislykket master? Problemet er der stadig, og MongoDB løser det ved at rulle alle ændringer tilbage, som ikke blev replikeret til slaverne på tidspunktet for fejlen. Disse data fjernes og placeres i en "rollback"-mappe, så det er op til administratoren at gendanne dem.
For at finde ud af mere, tjek ClusterControl; og du er velkommen til at kommentere eller stille spørgsmål nedenfor.