Dette er den skrevne version af min nye YouTube-video ✍️ 🙂
I denne Redis-tutorial lærer du om Redis og hvordan Redis kan bruges som en primær database til komplekse applikationer der skal gemme data i flere formater.
Oversigt 📝
- Hvad Redis er og dets anvendelser samt hvorfor den er velegnet til moderne komplekse mikroserviceapplikationer?
- Hvordan Redis understøtter lagring af flere dataformater til forskellige formål gennem sine moduler ?
- Hvordan Redis som en database i hukommelsen kan bevare data og genoprette datatab ?
- Sådan skalerer og replikeres Redis ?
- Endelig, da en af de mest populære platforme til at køre mikrotjenester er Kubernetes, og da det er lidt udfordrende at køre stateful-applikationer i Kubernetes, vil vi se, hvordan du nemt kan køre Redis i Kubernetes
Hvad er Redis?
Redis står for re mote dic ordbog s erver
Redis er en in-memory database . Så mange mennesker har brugt det som en cache oven på andre databaser for at forbedre applikationens ydeevne. 🤓
Men hvad mange mennesker ikke ved er, at Redis er en fuldt udbygget primær database der kan bruges til at gemme og bevare flere dataformater til komplekse applikationer. 😎
Så lad os se anvendelsesmulighederne for det.
Hvorfor Multi-Model Database?
Lad os se på en almindelig opsætning for en mikroserviceapplikation.
Lad os sige, at vi har en kompleks social medieapplikation med millioner af brugere. Til dette skal vi muligvis gemme forskellige dataformater i forskellige databaser:
- Relationel database , ligesom Mysql, for at gemme vores data
- ElasticSearch til hurtig søgning og filtrering
- Grafdatabase at repræsentere brugernes forbindelser
- Dokumentdatabase , ligesom MongoDB for at gemme medieindhold, der deles af vores brugere dagligt
- Cachetjeneste for en bedre ydeevne for applikationen
Det er indlysende, at dette er en ret kompleks opsætning.
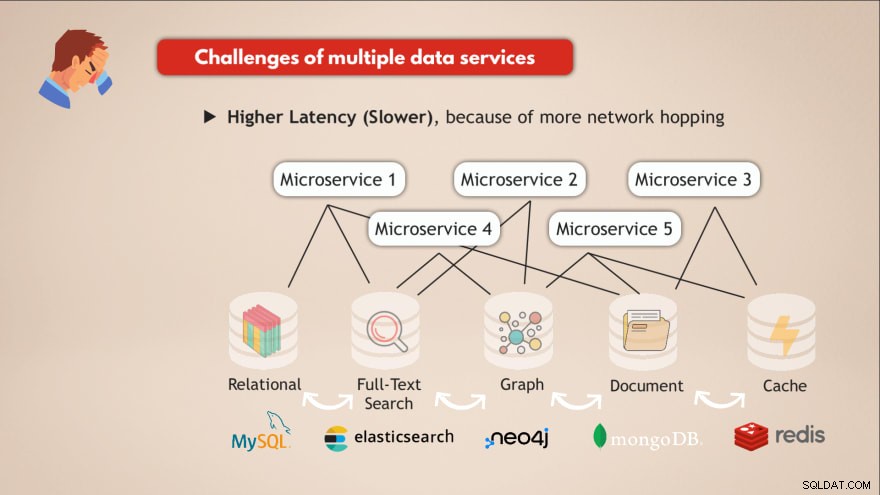
Udfordringer ved at have flere datatjenester
- ❌ Hver datatjeneste skal implementeres og vedligeholdes
- ❌ Know-How nødvendig for hver datatjeneste
- ❌ Forskellige krav til skalering og infrastruktur
- ❌ Mere kompleks applikationskode til at interagere med alle disse forskellige DB'er
- ❌ Højere forsinkelse (langsommere), på grund af mere netværkshopping
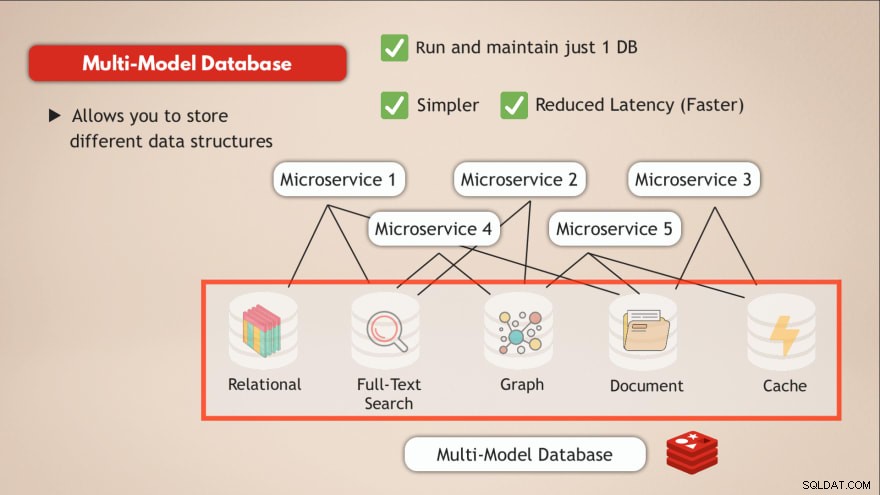
At have en multimodeldatabase
I sammenligning med en multimodeldatabase løser du de fleste af disse udfordringer. Først og fremmest kører og vedligeholder du kun 1 datatjeneste . Så din applikation skal også tale med et enkelt datalager, og det kræver kun én programmatisk grænseflade til den datatjeneste.
Derudover vil latenstiden blive reduceret ved at gå til et enkelt dataendepunkt og eliminere flere interne netværkshubs.
Så at have én database, som Redis, der giver dig mulighed for at gemme forskellige typer data eller dybest set giver dig mulighed for at have flere typer databaser i én samt fungere som en cache, løser sådanne udfordringer.
- ✅ Kør og vedligehold kun 1 database
- ✅ Enklere
- ✅ Reduceret latens (hurtigere)
Hvordan virker Redis?
Redis-moduler 📦
Måden det fungerer på er, at du har Redis Core, som er et nøgleværdilager der allerede understøtter lagring af flere typer data, og så kan du udvide den kerne med det, der kaldes moduler til forskellige datatyper , som din ansøgning har brug for til forskellige formål. Så for eksempel RediSearch for søgefunktionalitet som ElasticSearch eller Redis Graph til grafdatalagring og så videre:

Og en stor ting ved dette er, at det er modulært . Så disse forskellige typer af databasefunktionaliteter er ikke tæt integreret i én database, men du kan i stedet vælge præcis, hvilken datatjenestefunktionalitet du har brug for til din applikation og så grundlæggende tilføje det modul.
Out-of-the-box cache ⚡️
Når du bruger Redis som en primær database, behøver du selvfølgelig ikke en ekstra cache, fordi du har det automatisk ud af boksen med Redis. Det betyder igen mindre kompleksitet i din applikation, fordi du ikke behøver at implementere logikken til at administrere udfyldning og ugyldiggørelse af cache.
Redis er hurtig 🚀
Som en in-memory (data gemmes i RAM) database er Redis superhurtig og ydende, hvilket selvfølgelig gør selve applikationen hurtigere.
Men på dette tidspunkt undrer du dig måske:
Hvordan kan en database i hukommelsen bevare data? 🤔
Hvordan kan Redis bevare data og komme sig efter datatab? 🧐
Hvis Redis-processen eller serveren som Redis kører på fejler, er alle data i hukommelsen væk, ikke sandt? Så hvordan bevares dataene, og hvordan kan jeg grundlæggende være sikker på, at mine data er sikre? 👀
Replikerer Redis?
Nå, den enkleste måde at have datasikkerhedskopier på er ved at replikere Redis . Så hvis Redis master-instansen går ned, vil replikaerne stadig køre og have alle data. Så hvis du har en replikeret Redis, vil replikaerne have dataene.
Men selvfølgelig, hvis alle Redis-forekomsterne går ned, vil du miste dataene, fordi der ikke vil være nogen replika tilbage. 🤯Så vi har brug for rigtig vedholdenhed .
Snapshotting &AOF
Redis har flere mekanismer til at bevare dataene og holde dataene sikre.
Snapshots
Det første:snapshots, som du kan konfigurere baseret på tid, antal anmodninger osv. Så snapshots af dine data vil blive gemt på en disk , som du kan bruge til at gendanne dine data, hvis hele Redis-databasen er væk.
Men bemærk, at du vil miste de sidste minutters data , fordi du normalt laver snapshots hvert femte minut eller hver time afhængigt af dine behov. 😐
AOF
Så som et alternativ bruger Redis noget, der hedder AOF , som står for A ppend O kun F ile.
I dette tilfælde gemmes hver ændring på disken for vedvarende vedholdenhed . Og når du genstarter Redis eller efter en strømafbrydelse, vil Redis genafspille logfilerne ved at tilføje kun fil for at genopbygge tilstanden.
Så AOF er mere holdbart , men kan være langsommere end snapshots.
Bedste mulighed 💡 :Brug en kombination af både AOF og snapshots, hvor AOF'en fortsætter data fra hukommelsen til disken, plus at du har almindelige snapshots imellem for at gemme datatilstanden, hvis du skal gendanne den:

Hvordan skalerer man en Redis-database?
Lad os sige, at min 1 Redis-instans løber tør for hukommelse, så data bliver for store til at holde i hukommelsen, eller Redis bliver en flaskehals og kan ikke håndtere flere anmodninger. Hvordan forøger jeg i så fald kapaciteten og hukommelsesstørrelsen til min Redis-database? 🤔
Det har vi flere muligheder for:
1. Klynger
Først og fremmest understøtter Redis clustering . Det betyder, at du kan have en primær eller master Redis-instans, som kan bruges til at læse og skrive data, og du kan have flere replikaer af den primære instans til at læse dataene :
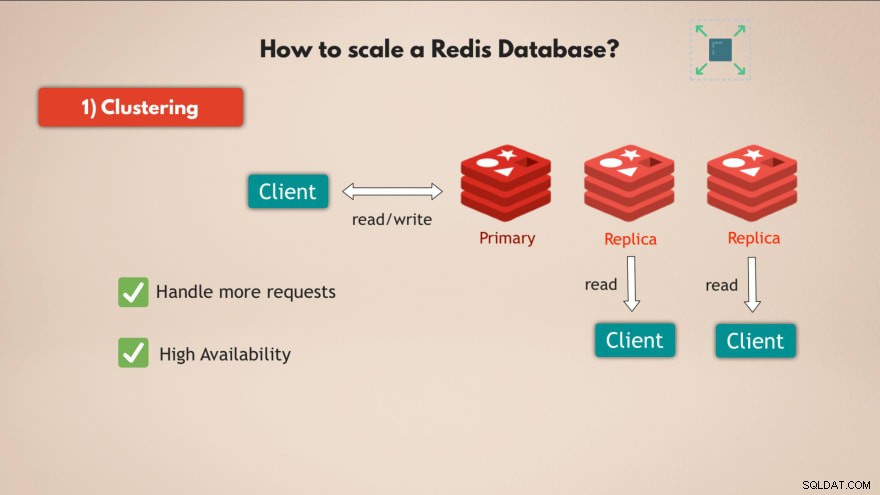
På denne måde kan du skalere Redis til at håndtere flere anmodninger og derudover øge den høje tilgængelighed af din database, for hvis master fejler, kan 1 af replikaerne tage over, og din Redis-database kan grundlæggende fortsætte med at fungere uden problemer.
2. Sharding
Det virker godt nok, men hvad nu hvis
- dit datasæt bliver for stort til at passe ind i en hukommelse på en enkelt server .
- Derudover har vi skaleret læsningerne i databasen, så alle de anmodninger, der stort set kun forespørger dataene. Men vores hovedinstans er stadig alene og skal stadig klare alle skrivningerne .
Så hvad er løsningen her? 🤔
Til det bruger vi konceptet sharding , som er et generelt begreb i databaser, og som Redis også understøtter.
Så sharding betyder dybest set, at du tager dit komplette datasæt og deler det op i mindre bidder eller delmængder af data , hvor hvert shard er ansvarlig for sit eget undersæt af data.
Så det betyder, at i stedet for at have én masterinstans, der håndterer alle skrivningerne til det komplette datasæt, kan du opdele det i f.eks. 4 shards, hver af dem er ansvarlige for at læse og skrive til en delmængde af dataene . 💡
Og hvert shard har også brug for mindre hukommelseskapacitet , fordi de bare har en fjerdedel af dataene. Dette betyder, at du kan distribuere og køre shards på mindre noder og dybest set skalere din klynge vandret:
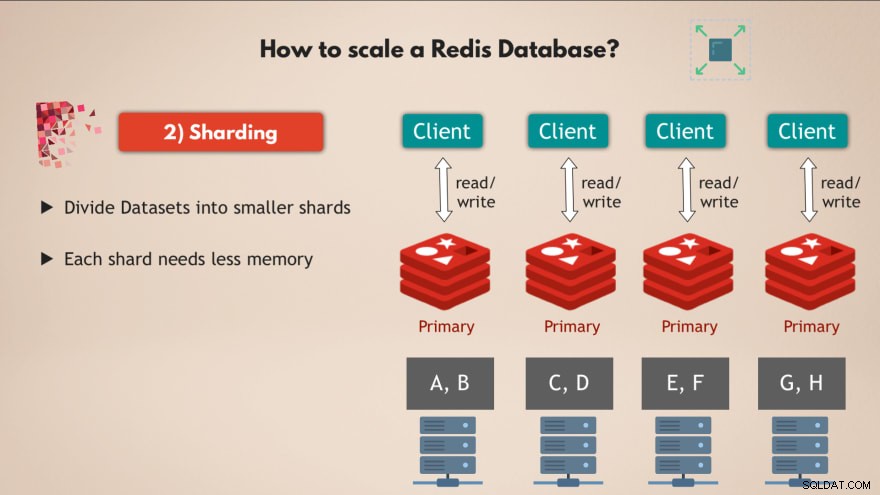
Altså at have flere noder , som kører flere replikaer af Redis, som er alle sharded giver dig en yderst effektiv Redis-database, der kan håndtere meget flere forespørgsler uden at skabe flaskehalse 👍
Flere emner...
Se min video nedenfor for de sidste 2 emner og scenarier:
- Applikationer, der har brug for endnu højere tilgængelighed og ydeevne på tværs af flere geografiske placeringer
- Den nye standard for at køre mikrotjenester er Kubernetes-platformen, så at køre Redis i Kubernetes er et meget interessant og almindeligt eksempel
Hele videoen er tilgængelig her:🤓
Håber dette var nyttigt og interessant for nogle af jer! 😊
Synes godt om, del og følg mig 😍 for mere indhold:
- Instagram – Poster mange ting bag kulissen
- Privat FB-gruppe