Ivrig efter at lære alt og alt om Hadoop-klyngen?
Hadoop er en softwareramme til analyse og lagring af enorme mængder data på tværs af klynger af råvarehardware. I denne artikel vil vi studere en Hadoop-klynge.
Lad os først starte med en introduktion til Cluster.
Hvad er en klynge?
En klynge er en samling af noder. Noder er intet andet end et forbindelsespunkt/skæringspunkt i et netværk.
En computerklynge er en samling af computere forbundet med et netværk, som er i stand til at kommunikere med hinanden og fungerer som et enkelt system.
Hvad er Hadoop Cluster?
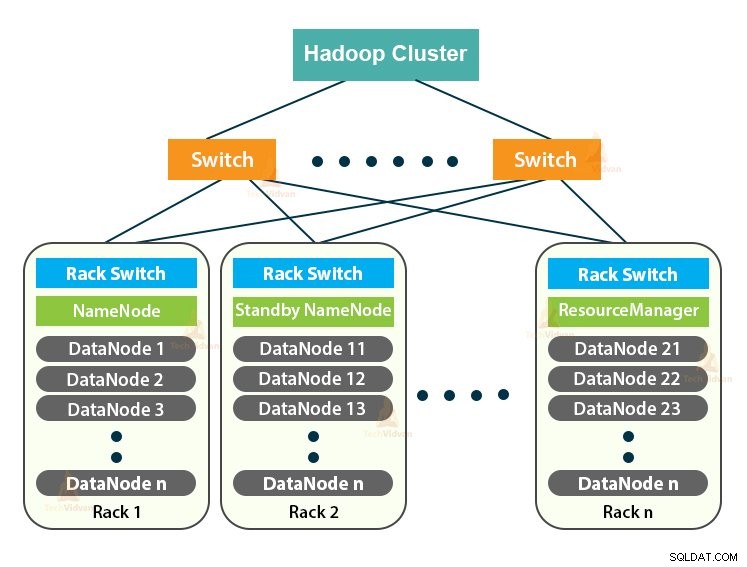
Hadoop Cluster er blot en computerklynge, der bruges til at håndtere en stor mængde data på en distribueret måde.
Det er en computerklynge designet til lagring og analyse af enorme mængder af ustrukturerede eller strukturerede data i et distribueret computermiljø.
Hadoop-klynger er også kendt som Shared-nothing-systemer fordi intet er delt mellem noderne i klyngen undtagen netværksbåndbredden. Dette reducerer behandlingsforsinkelsen.
Når der er behov for at behandle forespørgsler om den enorme mængde data, minimeres den klyngeomfattende latenstid.
Lad os nu studere arkitekturen i Hadoop Cluster.
Arkitektur af Hadoop Cluster
Hadoop-klyngen følger en mester-slave-arkitektur. Den består af masterknuden, slaveknuden og klientknuden.
1. Master i Hadoop Cluster
Master in the Hadoop Cluster er en højeffektmaskine med en høj konfiguration af hukommelse og CPU. De to dæmoner, der er NameNode og ResourceManager, kører på masternoden.
a. Funktioner af NameNode
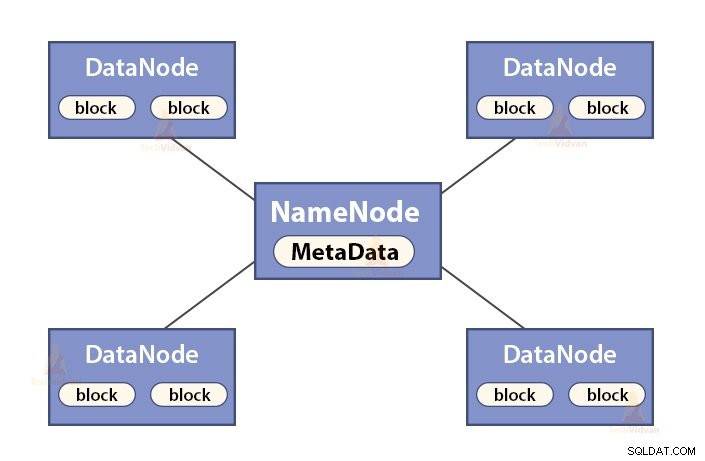
NameNode er en masternode i Hadoop HDFS . NameNode administrerer filsystemets navneområde. Det gemmer filsystemets metadata i hukommelsen for hurtig genfinding. Derfor bør den konfigureres på avancerede maskiner.
Funktionerne i NameNode er:
- Administrerer filsystemets navneområde
- Gemmer metadata om blokke af en fil, blokerer placering, tilladelser osv.
- Den udfører filsystemets navnerumshandlinger som åbning, lukning, omdøbning af filer og mapper osv.
- Det vedligeholder og administrerer DataNode.
b. Funktioner i Resource Manager
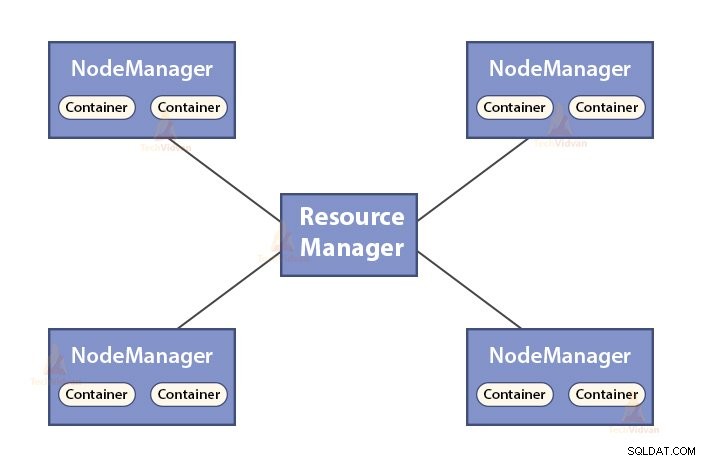
- ResourceManager er master-dæmonen for YARN.
- ResourceManageren mægler ressourcerne blandt alle applikationerne i systemet.
- Det holder styr på levende og døde noder i klyngen.
2. Slaver i Hadoop-klyngen
Slaver i Hadoop-klyngen er billig råvarehardware. De to dæmoner, der er DataNodes og YARN NodeManagers, kører på slaveknuderne.
a. DataNodes funktioner
- DataNodes gemmer de faktiske forretningsdata. Det gemmer blokkene af en fil.
- Den udfører blokoprettelse, sletning, replikering baseret på instruktionerne fra NameNode.
- DataNode er ansvarlig for at betjene klientens læse-/skriveoperationer.
b. Funktioner i NodeManager
- NodeManager er slavedæmonen for YARN.
- Det er ansvarligt for containere, overvåger deres ressourceforbrug (såsom CPU, disk, hukommelse, netværk) og rapporterer det samme til ResourceManager.
- NodeManageren kontrollerer også tilstanden af den node, den kører på.
3. Client Node i Hadoop Cluster
Klient noder i Hadoop er hverken master node eller slave noder. De har Hadoop installeret på dem med alle klyngeindstillinger.
Funktioner af klientknudepunkter
- Klientnoder indlæser data i Hadoop-klyngen.
- Den indsender MapReduce-job, der beskriver, hvordan disse data skal behandles.
- Hent resultaterne af jobbet efter færdiggørelse af behandlingen.
Vi kan skalere Hadoop-klyngen ud ved at tilføje flere noder. Dette gør Hadoop lineært skalerbar . Med hver knudetilføjelse får vi et tilsvarende boost i gennemløbet. Hvis vi har 'n' noder, giver tilføjelse af 1 node (1/n) yderligere regnekraft.
Single Node Hadoop Cluster VS Multi-Node Hadoop Cluster
1. Single Node Hadoop Cluster
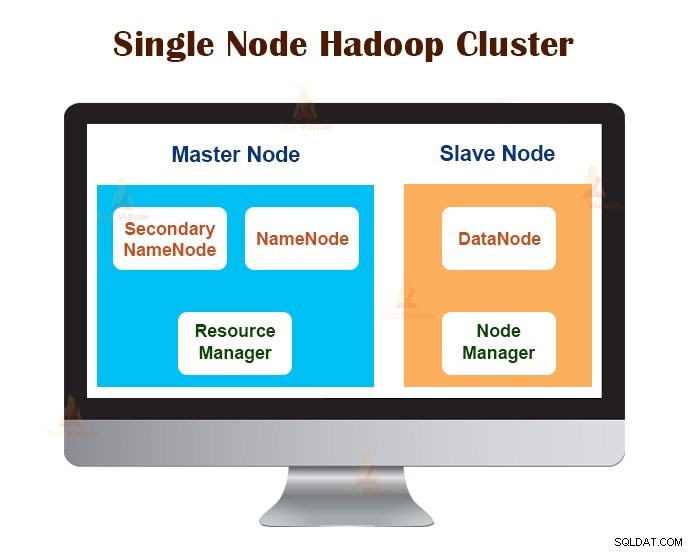
Single Node Hadoop Cluster er implementeret på en enkelt maskine. Alle dæmoner som NameNode, DataNode, ResourceManager, NodeManager kører på den samme maskine/vært.
I en enkelt-node-klyngeopsætning kører alt på en enkelt JVM-instans. Hadoop-brugeren behøvede ikke at foretage nogen konfigurationsindstillinger bortset fra at indstille JAVA_HOME-variablen.
Standardreplikeringsfaktoren for en enkelt node Hadoop-klynge er altid 1.
2. Multi-Node Hadoop Cluster
Multi-Node Hadoop Cluster er implementeret på flere maskiner. Alle dæmonerne i multi-node Hadoop-klyngen er oppe og køre på forskellige maskiner/værter.
En multi-node Hadoop-klynge følger master-slave-arkitektur. Dæmonerne Namenode og ResourceManager kører på masterknuderne, som er avancerede computermaskiner.
Dæmonerne DataNodes og NodeManagers kører på slaveknuderne (arbejderknudepunkter), som er billig råvarehardware.
I multi-node Hadoop-klyngen kan slavemaskiner være til stede på et hvilket som helst sted, uanset placeringen af den fysiske placering af masterserveren.
Kommunikationsprotokoller brugt i Hadoop Cluster
HDFS-kommunikationsprotokollerne er lagdelt på toppen af TCP/IP-protokollen. En klient etablerer en forbindelse med NameNode gennem den konfigurerbare TCP-port på NameNode-maskinen.
Hadoop-klyngen etablerer en forbindelse til klienten gennem ClientProtocol. Desuden taler DataNode med NameNode ved hjælp af DataNode Protocol.
RPC-abstraktionen (Remote Procedure Call) omslutter Client Protocol og DataNode-protokollen. Ved design starter NameNode ingen RPC'er. Den reagerer kun på RPC-anmodninger udstedt af klienter eller DataNodes.
Bedste praksis til opbygning af Hadoop-klynge
Ydeevnen for en Hadoop Cluster afhænger af forskellige faktorer baseret på de veldimensionerede hardwareressourcer, der bruger CPU, hukommelse, netværksbåndbredde, harddisk og andre velkonfigurerede softwarelag.
At bygge en Hadoop-klynge er et ikke-trivielt job. Det kræver overvejelse af forskellige faktorer som at vælge den rigtige hardware, dimensionere Hadoop-klyngerne og konfigurere Hadoop-klyngen.
Lad os nu se hver enkelt i detaljer.
1. At vælge den rigtige hardware til Hadoop Cluster
Mange organisationer, når de opsætter Hadoop-infrastruktur, er i en vanskelig situation, da de ikke er klar over, hvilken slags maskiner, de skal købe for at opsætte et optimeret Hadoop-miljø, og den ideelle konfiguration, de skal bruge.
For at vælge den rigtige hardware til Hadoop Cluster skal man overveje følgende punkter:
- Mængden af data, som klyngen vil håndtere.
- Den type arbejdsbelastninger, som klyngen skal håndtere (CPU bundet, I/O bundet).
- Datalagringsmetodologi som databeholdere, anvendte datakomprimeringsteknikker, hvis nogen.
- En dataopbevaringspolitik, det vil sige, hvor længe vi ønsker at beholde dataene, før de skylles ud.
2. Dimensionering af Hadoop-klyngen
For at bestemme størrelsen af Hadoop-klyngen bør den datamængde, som Hadoop-brugerne behandler på Hadoop-klyngen, være en vigtig overvejelse.
Ved at kende mængden af data, der skal behandles, hjælper det med at beslutte, hvor mange noder, der kræves for at behandle dataene effektivt, og hukommelseskapacitet, der kræves for hver node. Der bør være en balance mellem ydeevnen og prisen på den godkendte hardware.
3. Konfiguration af Hadoop Cluster
Det er ikke let at finde den ideelle konfiguration til Hadoop Cluster. Hadoop framework skal tilpasses til den klynge, den kører, og også til jobbet.
Den bedste måde at bestemme den ideelle konfiguration for Hadoop-klyngen på er at køre Hadoop-jobbene med standardkonfigurationen tilgængelig for at få en basislinje. Derefter kan vi analysere jobhistoriklogfilerne for at se, om der er nogen ressourcesvaghed, eller om det tager længere tid at køre jobbet end forventet.
Hvis det er tilfældet, skal du ændre konfigurationen. Gentagelse af den samme proces kan justere Hadoop Cluster-konfigurationen, der passer bedst til forretningskravene.
Hadoop-klyngens ydeevne afhænger i høj grad af de ressourcer, der er allokeret til dæmonerne. Til små til mellemstore datakontekster reserverer Hadoop én CPU-kerne på hver DataNode, mens den til de lange datasæt tildeler 2 CPU-kerner på hver DataNode til HDFS- og MapReduce-dæmoner.
Hadoop Cluster Management
Når Hadoop-klyngen implementeres i produktionen, er det tydeligt, at den skal skaleres langs alle dimensioner, der er volumen, variation og hastighed.
Forskellige funktioner, som det burde være i besiddelse af for at blive produktionsklar er - døgnåbent, robust, håndterbarhed og ydeevne. Hadoop Cluster management er hovedfacetten af big data-initiativet.
Det bedste værktøj til Hadoop Cluster management bør have følgende funktioner:-
- Den skal sikre 24×7 høj tilgængelighed, ressourceforsyning, forskelligartet sikkerhed, arbejdsbelastningsstyring, sundhedsovervågning, ydeevneoptimering. Den skal også levere jobplanlægning, politikstyring, sikkerhedskopiering og gendannelse på tværs af en eller flere noder.
- Implementer redundant HDFS NameNode høj tilgængelighed med belastningsbalancering, hot standbys, resynkronisering og auto-failover.
- Håndhævelse af politikbaserede kontroller, der forhindrer enhver applikation i at få fat i en uforholdsmæssig stor andel af ressourcer på en allerede maks. Hadoop-klynge.
- Udførelse af regressionstest til styring af implementeringen af alle softwarelag over Hadoop-klynger. Dette er for at sikre, at alle job eller data ikke går ned eller støder på flaskehalse i den daglige drift.
Fordele ved Hadoop Cluster
De forskellige fordele fra Hadoop Cluster er:
1. Skalerbar
Hadoop Clusters er skalerbare. Vi kan tilføje et hvilket som helst antal noder til Hadoop Cluster uden nedetid og uden nogen ekstra indsats. Med hver knudetilføjelse får vi et tilsvarende boost i gennemløbet.
2. Robusthed
Hadoop Cluster er bedst kendt for sin pålidelige opbevaring. Det kan gemme data pålideligt, selv i tilfælde som DataNode-fejl, NameNode-fejl og netværkspartition. DataNode sender periodisk et hjerteslagssignal til NameNode.
I netværkspartitionen bliver et sæt DataNodes løsrevet fra NameNode, på grund af hvilket NameNode ikke modtager noget hjerteslag fra disse DataNodes. NameNode betragter derefter disse DataNodes som døde og videresender ingen I/O-anmodninger til dem.
Også replikeringsfaktoren for blokkene, der er gemt i disse DataNodes, falder under deres specificerede værdi. Som et resultat starter NameNode derefter replikeringen af disse blokke og genopretter efter fejlen.
3. Cluster Rebalancering
Hadoop HDFS-arkitekturen udfører automatisk klynge-rebalancering. Hvis den ledige plads i DataNode falder under tærskelniveauet, flytter HDFS-arkitekturen automatisk nogle data til andre DataNode, hvor der er nok plads til rådighed.
4. Omkostningseffektiv
Opsætning af Hadoop Cluster er omkostningseffektiv, fordi den omfatter billig råvarehardware. Enhver organisation kan nemt opsætte en kraftfuld Hadoop Cluster uden at bruge meget på dyr serverhardware.
Også Hadoop Clusters med dens distribuerede lagringstopologi overvinder begrænsningerne i det traditionelle system. Den begrænsede lagerplads kan udvides blot ved at tilføje yderligere billige lagerenheder til systemet.
5. Fleksibel
Hadoop-klynger er meget fleksible, da de kan behandle data af enhver type, enten struktureret, semi-struktureret eller ustruktureret og i alle størrelser lige fra Gigabyte til Petabytes.
6. Hurtig behandling
I Hadoop Cluster kan data behandles parallelt i et distribueret miljø. Dette giver hurtige databehandlingsmuligheder til Hadoop. Hadoop Clusters kan behandle Terabytes eller Petabytes af data inden for en brøkdel af sekunder.
7. Dataintegritet
For at tjekke for korruption i datablokke på grund af buggy-software, fejl i en lagerenhed osv. implementerer Hadoop-klyngen kontrolsum på hver blok af filen. Hvis den finder en blok beskadiget, søger den fra en anden DataNode, der indeholder replikaen af den samme blok. Således bevarer Hadoop-klyngen dataintegriteten.
Oversigt
Efter at have læst denne artikel kan vi sige, at Hadoop Cluster er en speciel beregningsklynge designet til at analysere og gemme big data. Hadoop Cluster følger master-slave-arkitektur.
Masterknudepunktet er den avancerede computermaskine, og slaveknuderne er maskiner med normal CPU- og hukommelseskonfiguration. Vi har også set, at Hadoop Cluster kan sættes op på en enkelt maskine kaldet single-node Hadoop Cluster eller på flere maskiner kaldet multi-node Hadoop Cluster.
I denne artikel havde vi også dækket de bedste fremgangsmåder, der skal følges, mens vi bygger en Hadoop-klynge. Vi havde også set mange fordele ved Hadoop Cluster, herunder skalerbarhed, fleksibilitet, omkostningseffektivitet osv.