Udforsk arkitekturen i Hadoop, som er den mest anvendte ramme til lagring og behandling af massive data.
I denne artikel vil vi studere Hadoop-arkitektur. Artiklen forklarer Hadoop-arkitekturen og komponenterne i Hadoop-arkitekturen, som er HDFS, MapReduce og YARN. I artiklen vil vi udforske Hadoop-arkitekturen i detaljer sammen med Hadoop Architecture-diagrammet.
Lad os nu starte med Hadoop Architecture.
Hadoop-arkitektur
Målet med at designe Hadoop er at udvikle en billig, pålidelig og skalerbar ramme, der lagrer og analyserer de stigende big data.
Apache Hadoop er en softwareramme designet af Apache Software Foundation til lagring og behandling af store datasæt af varierende størrelser og formater.
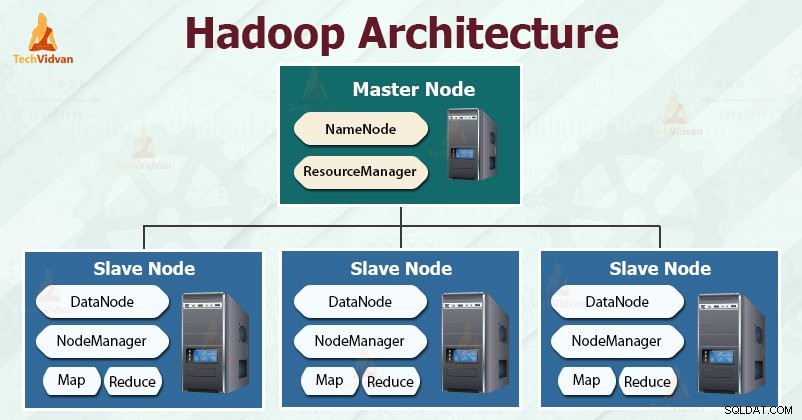
Hadoop følger mester-slaven arkitektur til effektiv lagring og behandling af enorme mængder data. Masterknuderne tildeler opgaver til slaveknuderne.
Slaveknuderne er ansvarlige for at gemme de faktiske data og udføre den faktiske beregning/behandling. Masterknuderne er ansvarlige for lagring af metadata og styring af ressourcerne på tværs af klyngen.
Slavenoder gemmer de faktiske forretningsdata, mens masteren gemmer metadataene.
Hadoop-arkitekturen består af tre lag. De er:
- Lagerlag (HDFS)
- Resource Management layer (YARN)
- Behandler lag (MapReduce)
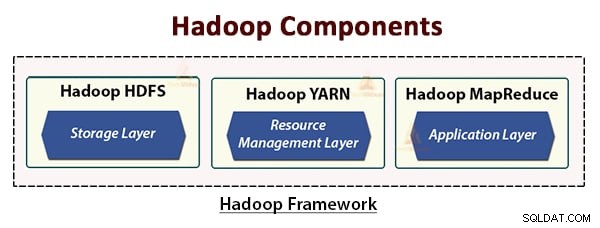
HDFS, YARN og MapReduce er kernekomponenterne i Hadoop Framework.
Lad os nu studere disse tre kernekomponenter i detaljer.
1. HDFS
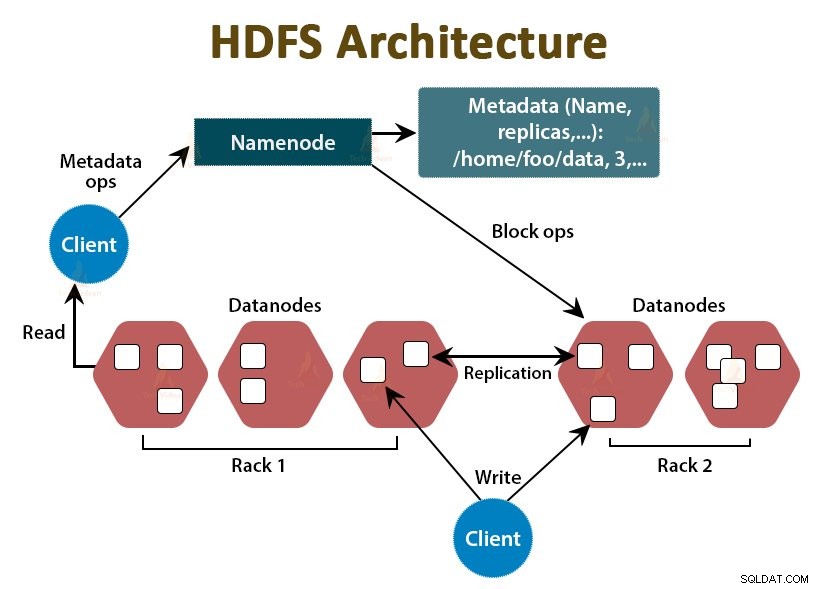
HDFS er Hadoop Distributed File System , som kører på billig råvarehardware. Det er lagerlaget til Hadoop. Filerne i HDFS er opdelt i blokstørrelser, kaldet datablokke.
Disse blokke lagres derefter på slaveknuderne i klyngen. Blokstørrelsen er som standard 128 MB, som vi kan konfigurere i henhold til vores krav.
Ligesom Hadoop følger HDFS også master-slave-arkitekturen. Den består af to dæmoner - NameNode og DataNode. NameNode er master-dæmonen, der kører på master-noden. DataNoderne er slavedæmonen, der kører på slaveknuderne.
NameNode
NameNode gemmer filsystemets metadata, det vil sige filnavne, information om blokke af en fil, blokerer placeringer, tilladelser osv. Den administrerer datanoderne.
DataNode
DataNodes er slaveknuderne, der gemmer de faktiske forretningsdata. Det tjener klientens læse-/skriveanmodninger baseret på NameNode-instruktionerne.
DataNodes gemmer blokkene af filerne, og NameNode gemmer metadataene som blokplaceringer, tilladelser osv.
2. MapReduce
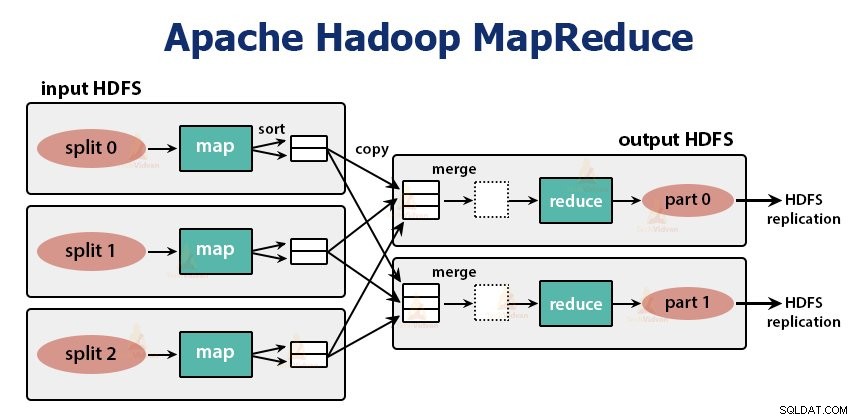
Det er databehandlingslaget i Hadoop. Det er en softwareramme til at skrive applikationer, der behandler enorme mængder data (terabyte til petabyte inden for rækkevidde) parallelt på klyngen af råvarehardware.
MapReduce-rammen fungerer på
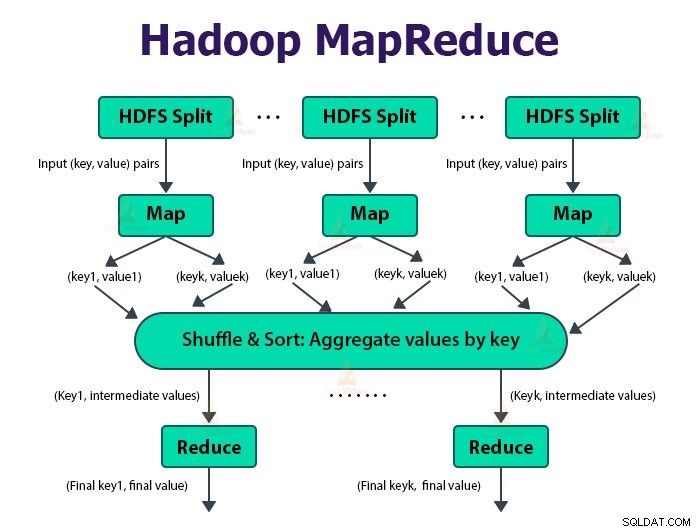
MapReduce-jobbet er den arbejdsenhed, klienten ønsker at udføre. MapReduce-opgaven består hovedsageligt af inputdata, MapReduce-programmet og konfigurationsoplysningerne. Hadoop kører MapReduce-jobbene ved at opdele dem i to typer opgaver, der er kortopgaver og reducer opgaver . Hadoop YARN planlagde disse opgaver og køres på noderne i klyngen.
På grund af nogle ugunstige forhold, hvis opgaverne mislykkes, bliver de automatisk omlagt til en anden node.
Brugeren definerer kortfunktionen og reducer funktionen for at udføre MapReduce-jobbet.
Input til kortfunktionen og output fra reduceringsfunktionen er nøglen, værdiparret.
Funktionen af kortopgaverne er at indlæse, parse, filtrere og transformere dataene. Outputtet af kortopgaven er input til reduceringsopgaven. Reducer-opgaven udfører derefter gruppering og aggregering på outputtet af kortopgaven.
MapReduce-opgaven udføres i to faser-
1. Kortfase
a. RecordReader
Hadoop opdeler input til MapReduce-jobbet i de faste størrelsesopdelinger kaldet inputopdelinger eller splitter. RecordReader omdanner disse opdelinger til poster og analyserer dataene til poster, men den analyserer ikke selve posterne. RecordReader leverer dataene til kortlægningsfunktionen i nøgleværdi-par.
b. Kort
I kortfasen opretter Hadoop én kortopgave, som kører en brugerdefineret funktion kaldet kortfunktion for hver post i inputopdelingen. Det genererer nul eller flere mellemliggende nøgleværdi-par som kortopgaveoutput.
Kortopgaven skriver sit output til den lokale disk. Dette mellemoutput behandles derefter af reduceringsopgaverne, som kører en brugerdefineret reduceringsfunktion for at producere det endelige output. Når jobbet er afsluttet, skylles kortoutputtet ud.
c. Kombiner
Input til den enkelte reduktionsopgave er output fra alle kortlæggere, der er output fra alle kortopgaver. Hadoop giver brugeren mulighed for at definere en kombinationsfunktion, der kører på kortets output.
Kombinator grupperer dataene i kortfasen, før de overføres til Reducer. Den kombinerer output fra kortfunktionen, som derefter sendes som input til reduceringsfunktionen.
d. Partitioner
Når der er flere reducerere, partitionerer kortopgaverne deres output, og hver opretter en partition for hver reduceringsopgave. I hver partition kan der være mange nøgler og deres tilknyttede værdier, men posterne for en given nøgle er alle i en enkelt partition.
Hadoop giver brugerne mulighed for at kontrollere partitioneringen ved at angive en brugerdefineret partitioneringsfunktion. Generelt er der en standard partitioner, der samler nøglerne ved hjælp af hash-funktionen.
2. Reducer fase:
De forskellige faser i reducere opgaven er som følger:
a. Sorter og bland:
Reducer-opgaven starter med et blande- og sorteringstrin. Hovedformålet med denne fase er at samle de tilsvarende nøgler sammen. Sorter og bland fase downloader de data, som er skrevet af partitioneringen til den node, hvor Reducer kører.
Den sorterer hvert datastykke i en stor dataliste. MapReduce-rammen udfører denne sortering og blander, så vi nemt kan iterere over det i reduktionsopgaven.
Sortering og blanding udføres automatisk af rammen. Udvikleren kan gennem komparatorobjektet have kontrol over, hvordan nøglerne bliver sorteret og grupperet.
b. Reducer:
Reduceren, som er den brugerdefinerede reduktionsfunktion, udføres én gang pr. nøglegruppering. Reduceren filtrerer, samler og kombinerer data på flere forskellige måder. Når reduktionsopgaven er fuldført, giver den nul eller flere nøgleværdi-par til OutputFormat. Reducer opgaveoutputtet gemmes i Hadoop HDFS.
c. OutputFormat
Det tager reduceringsoutputtet og skriver det til HDFS-filen af RecordWriter. Som standard adskiller den nøgle, værdi med en tabulator og hver post med et linjeskifttegn.
3. GARN
YARN står for Yet Another Resource Negotiator . Det er ressourcestyringslaget i Hadoop. Det blev introduceret i Hadoop 2.
YARN er designet med ideen om at opdele funktionaliteterne for jobplanlægning og ressourcestyring i separate dæmoner. Den grundlæggende idé er at have en global ResourceManager og ansøgningsmaster pr. ansøgning, hvor ansøgningen kan være et enkelt job eller DAG af job.
YARN består af ResourceManager, NodeManager og ApplicationMaster pr. applikation.
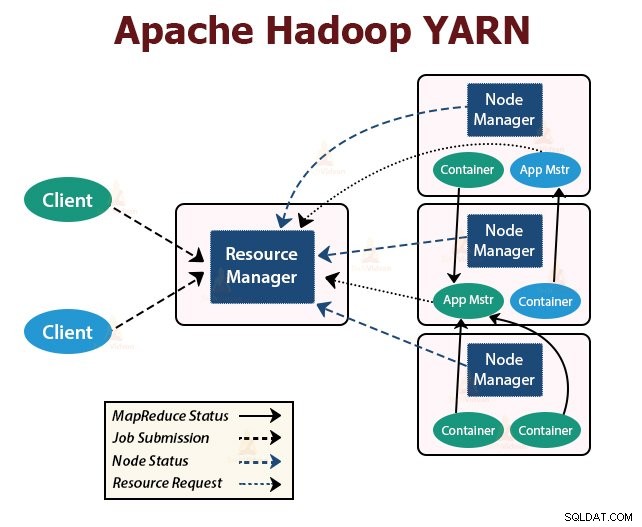
1. ResourceManager
Det arbitrerer ressourcer blandt alle applikationerne i klyngen.
Den har to hovedkomponenter, Scheduler og ApplicationManager.
a. Planlægger
- Planlægningsprogrammet allokerer ressourcer til de forskellige applikationer, der kører i klyngen, under hensyntagen til kapaciteter, køer osv.
- Det er en ren Scheduler. Den overvåger eller sporer ikke applikationens status.
- Scheduler garanterer ikke genstart af de mislykkede opgaver, der mislykkedes enten på grund af programfejl eller hardwarefejl.
- Den udfører planlægning baseret på applikationernes ressourcekrav.
b. ApplicationManager
- De er ansvarlige for at acceptere jobindsendelserne.
- ApplicationManager forhandler den første container til eksekvering af applikationsspecifik ApplicationMaster.
- De leverer service til genstart af ApplicationMaster-beholderen ved fejl.
- Per-applikation ApplicationMaster er ansvarlig for at forhandle containere fra Scheduler. Den sporer og overvåger deres status og fremskridt.
2. NodeManager:
NodeManager kører på slaveknuderne. Den er ansvarlig for containere, overvågning af maskinens ressourceforbrug, dvs. CPU, hukommelse, disk, netværksbrug og rapportering af det samme til ResourceManager eller Scheduler.
3. ApplicationMaster:
ApplicationMaster per applikation er et rammespecifikt bibliotek. Den er ansvarlig for at forhandle ressourcer fra RessourceManageren. Det fungerer sammen med NodeManager(erne) til at udføre og overvåge opgaverne.
Oversigt
I denne artikel har vi studeret Hadoop-arkitektur. Hadoop følger mester-slave topologi. Masterknudepunkterne tildeler opgaver til slaveknudepunkterne. Arkitekturen består af tre lag, som er HDFS, YARN og MapReduce.
HDFS er det distribuerede filsystem i Hadoop til lagring af big data. MapReduce er behandlingsrammen til at behandle store data i Hadoop-klyngen på en distribueret måde. YARN er ansvarlig for at administrere ressourcerne blandt applikationer i klyngen.
HDFS-dæmonen NameNode og YARN-dæmonen ResourceManager kører på masternoden i Hadoop-klyngen. HDFS-dæmonen DataNode og YARN NodeManager kører på slaveknuderne.
HDFS og MapReduce framework kører på det samme sæt noder, hvilket resulterer i meget høj aggregeret båndbredde på tværs af klyngen.
Fortsæt med at lære!