
Hvad er Couchbase
Couchbase Server er en open source, distribueret JSON-dokumentdatabase. Det afslører et udskaleret nøgleværdilager med administreret cache til dataoperationer på under millisekunder, specialbyggede indeksere til effektive forespørgsler og en kraftfuld forespørgselsmotor til at udføre SQL-lignende forespørgsler. Til mobil- og Internet of Things-miljøer kører Couchbase også indbygget på enheden og administrerer synkronisering til serveren.
Hvorfor Couchbase?
Couchbase Server er en open source, distribueret JSON-dokumentdatabase. Det afslører et udskaleret nøgleværdilager med administreret cache til dataoperationer på under millisekunder, specialbyggede indeksere til effektive forespørgsler og en kraftfuld forespørgselsmotor til at udføre SQL-lignende forespørgsler. Til mobil- og Internet of Things-miljøer kører Couchbase også indbygget på enheden og administrerer synkronisering til serveren.
Couchbase Server er specialiseret til at levere datastyring med lav latens til interaktive web-, mobil- og IoT-applikationer i stor skala. Almindelige krav, som Couchbase Server er designet til at opfylde, omfatter:
- Unified Programming Interface
- Forespørgsel
- Søg
- Mobil og IoT
- Analyse
- Kernedatabasemotor
- Udskaleringsarkitektur
- Memory-first-arkitektur
- Big data og SQL integrationer
- Sikkerhed i fuld stack
- Container- og Cloud-implementeringer
- Høj tilgængelighed
Mange databaser er i stand til at opfylde et eller flere af disse krav, men kræver afvejninger, når de kører i produktion med missionskritiske applikationer i internetskala. For eksempel kan én løsning levere datamodelfleksibilitet, men måske mangle evnen til at tilføje eller fjerne noder uden at påvirke oppetid eller ydeevne. En anden løsning kan demonstrere god skriveskalerbarhed uden at være i stand til at indeksere eller ændre datamodellen med det samme. Couchbase Server er designet til at levere en produktiv udvikler- og administrationsoplevelse, samtidig med at den giver ydeevne i skala, hvad enten det er i skyen, i en container, på stedet eller på en edge-enhed.
Nosql Performance Benchmark
Nyt benchmark, der sammenligner MongoDB, DataStax og Couchbase Server, demonstrerer Couchbase som den mest skalerbare, bedst ydende NoSQL-database.
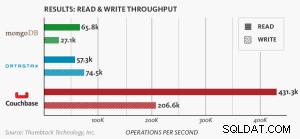
Knudebaseret benchmark .
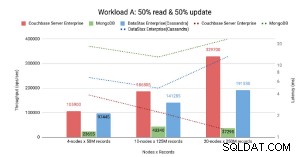
Ifølge CAP Theorem Couchbase .
Cap-sætning

Couchbase er på CP- og AP-diagram.
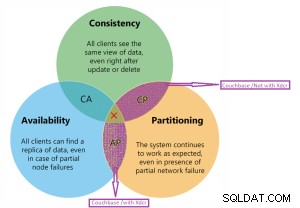
Couchbase CP- og AP-diagramdetaljer.
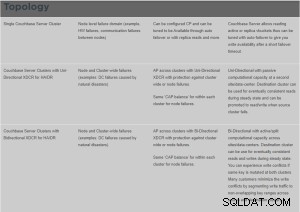
Hvad er XDCR?
Cross Data Center Replication (XDCR) replikerer data mellem klynger:dette giver beskyttelse mod datacenterfejl og giver også højtydende dataadgang til globalt distribuerede, missionskritiske applikationer.
XDCR replikerer data fra en specifik bucket på kildeklyngen til en specifik bucket på målklyngen. Data fra kildebøtten skubbes til målbøtten ved hjælp af en XDCR-agent, der kører på kildeklyngen, ved hjælp af Database Change Protocol. Enhver bucket (Couchbase eller Ephemeral) på enhver klynge kan specificeres som en kilde eller et mål for en eller flere XDCR-definitioner.
En komplet arkitektonisk beskrivelse af XDCR findes i Cross Data Center Replication (XDCR). Du ønsker måske at gøre dig bekendt med de oplysninger, der er angivet der, før du udfører de rutiner, der er angivet i dette afsnit.
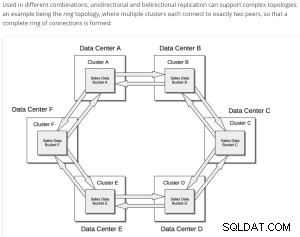
Xdcr grundlæggende struktur;
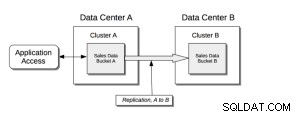
Forudgående krav;
- Bekræft, at din klynge har den rigtige størrelse og er i stand til at håndtere nye XDCR-streams. For eksempel har XDCR brug for 1-2 ekstra CPU-kerner pr. stream, og i nogle tilfælde vil det også kræve mere RAM og netværksressourcer. Hvis en klynge ikke er korrekt dimensioneret til den eksisterende arbejdsbyrde plus de nye XDCR-streams, kan XDCR konkurrere om serverressourcer og have en negativ indvirkning på den samlede ydeevne.
- Couchbase Server bruger TCP/IP-port 8091 til at udveksle klyngekonfigurationsoplysninger. Hvis du kommunikerer med en destinationsklynge via en dedikeret forbindelse eller internettet, skal du sikre dig, at alle noderne i destinationsklyngen og kildeklyngen kan kommunikere med hinanden via portene 8091 og 8092.
Porte opført efter kommunikationssti
| XDCR (klynge-til-klynge) |
|
Couchbase gemmer data både på disk og i RAM. Standardadfærden er at skrive dokumentet til disken på et eller andet vilkårligt tidspunkt (normalt hurtigt) efter lagring i RAM. Dette efterlader et kort vindue, hvor nodefejl kan resultere i tab af data.
Under alle omstændigheder, efter skrivning til RAM, vil dokumentet til sidst blive skrevet til disk. Couchbase holder en diskskrivekø, som du kan tjekke på siden for metrikrapporter i administrationskonsollen. Nu synkroniserer CB skrivninger på tværs af klyngen, og jeg tror, at en skrivning vil blive synkroniseret på tværs af en klynge, før Couchbase vil anerkende, at skrivningen skete (f.eks. før skrivemetoden vender tilbage til den, der ringer).
Hvis du har flere dokumenter end tilgængeligt RAM, vil kun de oftest tilgåede dokumenter blive gemt i RAM til hurtig genfinding, mens alle andre bliver "smidt ud" til disken.
Råd;
Da bøttestørrelsen blev reduceret fra 200 gb til 10 gb i kilden, blev replikeringen hurtigere nok. Med andre ord, hvis bøttestørrelsen er høj, og selvom alle data er i ram, har jeg set, at replikeringen havde 10 sekunders mellemrum.
Kilde og mål har samme linux-indstilling og samme ressourcer. Dette er kun et råd.
Prod bucket resident skal være %100. Fordi replikationshastighed er vigtig.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Råd;
Jeg anbefaler at kilde og mål har samme indstilling og har samme ressourcer.
Disse er bucket-indstilling, cluster-indstilling, cpu, hukommelse, diskkvalitet osv.
Xdcr-replikering er blot datareplikering. Før replikering skal du oprette bucket-metadata.
Hvis du vil, opretter du bruger, indeks, visning, begivenhed osv.
Som yderligere oplysninger;
Du kan lave xdcr-replikering på fællesskabsversion.
Du kan lave xdcr-replikering på virksomhedsversion. Dette kræver yderligere licens. Hvis du ikke bruger standby som prod, er det ikke et højt gebyr.
Couchbases andre stik til XDCR; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
Couchbase-styring kan udføres via WEB UI, REST API og CLI. Især webbrugergrænsefladen er meget enkel og ligetil at bruge. Du kan foretage mange operationelle transaktioner og forespørgsler via brugergrænsefladen.
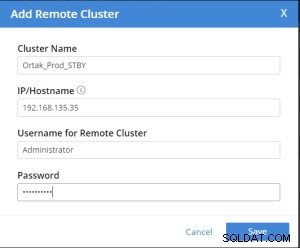
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Hukommelsesindstillinger for Xdcr-klyngeindstillinger er givet i henhold til serverhukommelsesværdien.
Bør være fri størrelse til serverhukommelse.
Xdcr har brug for yderligere hukommelse i produktklyngen.
Multiple couchbase bucket replikering er mulig.
Eksempel på XDCR-replikering, enkel betjening;
Xdcr-fanen valgt på couchbase-hjemmesiden.

Tilføj fjernklynge-fanen er valgt på den valgte xdcr-fane .

Tilføj fjernklynge handling udføres efter .
Tilføj replikeringsfane er valgt på den valgte xdcr-fane .
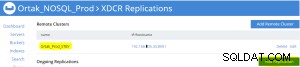
Tilføj bucket-replikering udføres efter .
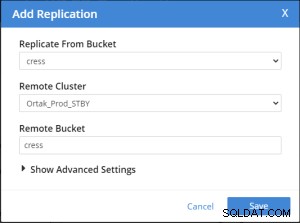
Bedste parametre for xdcr-ydeevne . Men det kan indstilles igen til dit system.

Replikeringsstatus på xdcr-fanen i kilden (prod)
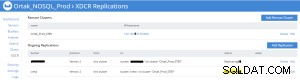
Bucket Replication Statistics
Replikeringsydelse på mål;

Replikeringsydelse på kilden;

Referencer;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
Fatih Gençali – Couchbase-certificeringer

