Dette er tredje del i en serie om løsninger på nummerseriegeneratorudfordringen. I del 1 dækkede jeg løsninger, der genererer rækkerne i farten. I del 2 dækkede jeg løsninger, der forespørger på en fysisk basistabel, som du på forhånd udfylder med rækker. I denne måned vil jeg fokusere på en fascinerende teknik, der kan bruges til at håndtere vores udfordring, men som også har interessante anvendelser langt ud over det. Jeg er ikke bekendt med et officielt navn for teknikken, men det ligner i konceptet noget til fjernelse af horisontal partition, så jeg vil uformelt referere til det som eliminering af horisontal enhed teknik. Teknikken kan have interessante positive præstationsfordele, men der er også forbehold, som du skal være opmærksom på, hvor den under visse forhold kan medføre en præstationsstraf.
Tak igen til Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea og Paul White for at dele dine ideer og kommentarer.
Jeg vil lave min test i tempdb, hvilket aktiverer tidsstatistik:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Tidligere ideer
Teknikken til eliminering af horisontale enheder kan bruges som et alternativ til kolonneelimineringslogikken eller eliminering af vertikal enhed teknik, som jeg stolede på i flere af de løsninger, som jeg tidligere har dækket. Du kan læse om det grundlæggende i kolonneelimineringslogik med tabeludtryk i Fundamentals of tabeludtryk, del 3 – Afledte tabeller, optimeringsovervejelser under "Søjleprojektion og et ord om SELECT *."
Den grundlæggende idé med teknikken til eliminering af vertikale enheder er, at hvis du har et indlejret tabeludtryk, der returnerer kolonner x og y, og din ydre forespørgsel kun refererer til kolonne x, eliminerer forespørgselskompileringsprocessen y fra det indledende forespørgselstræ, og derfor planen behøver ikke at vurdere det. Dette har flere positive optimeringsrelaterede implikationer, såsom opnåelse af indeksdækning med x alene, og hvis y er et resultat af en beregning, behøver du slet ikke at evaluere y's underliggende udtryk. Denne idé var kernen i Alan Bursteins løsning. Jeg stolede også på det i flere af de andre løsninger, som jeg dækkede, såsom med funktionen dbo.GetNumsAlanCharlieItzikBatch (fra del 1), funktionerne dbo.GetNumsJohn2DaveObbishAlanCharlieItzik og dbo.GetNumsJohn2DaveObbishAlanCharlie, og fra I Part. Som et eksempel vil jeg bruge dbo.GetNumsAlanCharlieItzikBatch som basisløsningen med den vertikale elimineringslogik.
Som en påmindelse bruger denne løsning en joinforbindelse med en dummy-tabel, der har et kolonnelagerindeks for at få batchbehandling. Her er koden til at oprette dummy-tabellen:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Og her er koden med definitionen af dbo.GetNumsAlanCharlieItzikBatch-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Jeg brugte følgende kode til at teste funktionens ydeevne med 100 millioner rækker, og returnerede den beregnede resultatkolonne n (manipulation af resultatet af funktionen ROW_NUMBER), sorteret efter n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Her er tidsstatistikken, som jeg fik til denne test:
CPU-tid =9328 ms, forløbet tid =9330 ms.Jeg brugte følgende kode til at teste funktionens ydeevne med 100 millioner rækker, og returnerede kolonnen rn (direkte, umanipuleret, resultat af ROW_NUMBER-funktionen), sorteret efter rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Her er tidsstatistikken, som jeg fik til denne test:
CPU-tid =7296 ms, forløbet tid =7291 ms.Lad os gennemgå de vigtige ideer, der er indlejret i denne løsning.
Ved at stole på kolonneelimineringslogik kom alan på ideen om ikke kun at returnere én kolonne med nummerserien, men tre:
- Kolonne rn repræsenterer et umanipuleret resultat af funktionen ROW_NUMBER, som starter med 1. Det er billigt at beregne. Det er ordensbevarende både når du angiver konstanter, og når du angiver ikke-konstanter (variabler, kolonner) som input til funktionen. Det betyder, at når din ydre forespørgsel bruger ORDER BY rn, får du ikke en Sorter-operator i planen.
- Kolonne n repræsenterer en beregning baseret på @low, en konstant og rownum (resultat af ROW_NUMBER-funktionen). Det er ordensbevarende med hensyn til rækkenummer, når du angiver konstanter som input til funktionen. Det er takket være Charlies indsigt om konstant foldning (se del 1 for detaljer). Det er dog ikke ordensbevarende, når du giver ikke-konstanter som input, da du ikke får konstant foldning. Jeg vil demonstrere dette senere i afsnittet om forbehold.
- Kolonne op repræsenterer n i modsat rækkefølge. Det er et resultat af en beregning, og det er ikke ordensbevarende.
Hvis du stoler på kolonneelimineringslogikken, forespørger du kolonne rn, hvis du skal returnere en nummerserie, der starter med 1, hvilket er billigere end at forespørge n. Hvis du har brug for en talserie, der starter med en anden værdi end 1, forespørger du n og betaler den ekstra pris. Hvis du har brug for resultatet sorteret efter talkolonnen, med konstanter som input, kan du bruge enten ORDER BY rn eller ORDER BY n. Men med ikke-konstanter som input, vil du sørge for at bruge ORDER BY rn. Det kan være en god idé bare altid at holde sig til at bruge BESTIL BY rn, når man skal have resultatet bestilt for at være på den sikre side.
Den horisontale enhedselimineringsidé ligner ideen til lodret enhedseliminering, kun den gælder for sæt rækker i stedet for sæt af kolonner. Faktisk stolede Joe Obbish på denne idé i sin funktion dbo.GetNumsObbish (fra del 2), og vi vil tage det et skridt videre. I sin løsning forenede Joe flere forespørgsler, der repræsenterer usammenhængende underområder af tal, ved at bruge et filter i WHERE-sætningen af hver forespørgsel til at definere anvendeligheden af underområdet. Når du kalder funktionen og sender konstante input, der repræsenterer afgrænsningerne for dit ønskede område, eliminerer SQL Server de uanvendelige forespørgsler på kompileringstidspunktet, så planen ikke engang afspejler dem.
Eliminering af horisontal enhed, kompileringstid versus køretid
Måske ville det være en god idé at starte med at demonstrere begrebet horisontal enhedseliminering i et mere generelt tilfælde, og også diskutere en vigtig skelnen mellem kompileringstids- og runtimeeliminering. Så kan vi diskutere, hvordan vi kan anvende ideen til vores nummerserieudfordring.
Jeg vil bruge tre tabeller kaldet dbo.T1, dbo.T2 og dbo.T3 i mit eksempel. Brug følgende DDL- og DML-kode til at oprette og udfylde disse tabeller:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Antag, at du vil implementere en inline TVF kaldet dbo.OneTable, der accepterer et af ovenstående tre tabelnavne som input og returnerer dataene fra den anmodede tabel. Baseret på konceptet for eliminering af horisontale enheder kan du implementere funktionen sådan:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Husk at en inline TVF anvender parameterindlejring. Dette betyder, at når du sender en konstant, såsom N'dbo.T2' som input, erstatter inlining-processen alle referencer til @WhichTable med konstanten før optimering . Elimineringsprocessen kan derefter fjerne referencerne til T1 og T3 fra det indledende forespørgselstræ, og dermed resulterer forespørgselsoptimering i en plan, der kun refererer til T2. Lad os teste denne idé med følgende forespørgsel:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Planen for denne forespørgsel er vist i figur 1.
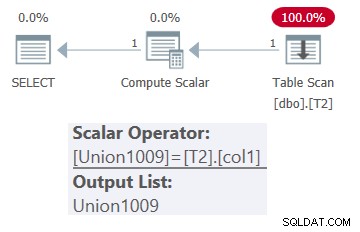 Figur 1:Plan for dbo.OneTable med konstant input
Figur 1:Plan for dbo.OneTable med konstant input
Som du kan se, vises kun tabel T2 i planen.
Tingene er lidt vanskeligere, når du sender en ikke-konstant som input. Dette kan være tilfældet, når du bruger en variabel, en procedureparameter eller sender en kolonne via APPLY. Inputværdien er enten ukendt på kompileringstidspunktet, eller der skal tages højde for parameteriseret plangenbrugspotentiale.
Optimizeren kan ikke fjerne nogen af tabellerne fra planen, men den har stadig et trick. Den kan bruge opstartsfilteroperatorer over undertræerne, der får adgang til tabellerne, og kun udføre det relevante undertræ baseret på runtime-værdien for @WhichTable. Brug følgende kode til at teste denne strategi:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Planen for denne udførelse er vist i figur 2:
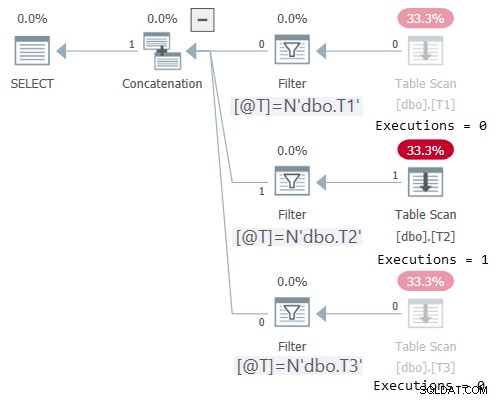 Figur 2:Plan for dbo.OneTable med ikke-konstant input
Figur 2:Plan for dbo.OneTable med ikke-konstant input
Plan Explorer gør det vidunderligt tydeligt at se, at kun det relevante undertræ blev udført (Executions =1), og nedtoner de undertræer, der ikke blev eksekveret (Executions =0). Desuden viser STATISTICS IO kun I/O-oplysninger for den tabel, der blev tilgået:
Tabel 'T2'. Scanningsantal 1, logisk læser 1, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.Anvendelse af horisontal enhedselimineringslogik på nummerserieudfordringen
Som nævnt kan du anvende det horisontale enhedselimineringskoncept ved at ændre en af de tidligere løsninger, der i øjeblikket bruger vertikal elimineringslogik. Jeg vil bruge funktionen dbo.GetNumsAlanCharlieItzikBatch som udgangspunkt for mit eksempel.
Husk at Joe Obbish brugte horisontal enhedseliminering til at udtrække de relevante usammenhængende underområder i nummerserien. Vi vil bruge konceptet til vandret at adskille den billigere beregning (rn), hvor @low =1, fra den dyrere beregning (n), hvor @low <> 1.
Mens vi er i gang, kan vi eksperimentere ved at tilføje Jeff Modens idé i hans fnTally-funktion, hvor han bruger en sentinel-række med værdien 0 til tilfælde, hvor området starter med @low =0.
Så vi har fire vandrette enheder:
- Sentinel-række med 0, hvor @low =0, med n =0
- TOP (@high) rækker hvor @low =0, med billig n =rownum, og op =@high – rownum
- TOP (@høj) rækker hvor @lav =1, med billig n =rækkenummer og op =@høj + 1 – rækkenummer
- TOP(@høj – @lav + 1) rækker hvor @lav <> 0 OG @lav <> 1, med dyrere n =@lav – 1 + rækkenummer, og op =@høj + 1 – rækkenummer
Denne løsning kombinerer ideer fra Alan, Charlie, Joe, Jeff og mig selv, så vi kalder batch-mode-versionen af funktionen dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Først skal du huske at sikre dig, at du stadig har dummy-tabellen dbo.BatchMe til stede for at få batchbehandling i vores løsning, eller brug følgende kode, hvis du ikke har:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Her er koden med definitionen af dbo.GetNumsAlanCharlieJoeJeffItzikBatch-funktion:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Vigtigt:Konceptet for eliminering af horisontale enheder er uden tvivl mere komplekst at implementere end det vertikale, så hvorfor gider det? Fordi det fjerner ansvaret for at vælge den rigtige kolonne fra brugeren. Brugeren behøver kun at bekymre sig om at forespørge på en kolonne kaldet n, i modsætning til at huske at bruge rn, når området starter med 1, og n ellers.
Lad os starte med at teste løsningen med konstante input 1 og 100.000.000 og bede om at få resultatet bestilt:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Planen for denne udførelse er vist i figur 3.
 Figur 3:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch,(M)
Figur 3:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch,(M)
Bemærk, at den eneste returnerede kolonne er baseret på det direkte, umanipulerede ROW_NUMBER-udtryk (Expr1313). Bemærk også, at der ikke er behov for sortering i planen.
Jeg fik følgende tidsstatistik for denne udførelse:
CPU-tid =7359 ms, forløbet tid =7354 ms.Kørselstiden afspejler tilstrækkeligt det faktum, at planen bruger batch-tilstand, det umanipulerede ROW_NUMBER-udtryk og ingen sortering.
Test derefter funktionen med konstantområdet 0 til 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Planen for denne udførelse er vist i figur 4.
 Figur 4:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch
Figur 4:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch
Planen bruger en Merge Join (Concatenation) operator til at flette vagtpostrækken med værdien 0 og resten. Selvom den anden del er lige så effektiv som før, tager flettelogikken en temmelig stor vejafgift på omkring 26 % af køretiden, hvilket resulterer i følgende tidsstatistik:
CPU-tid =9265 ms, forløbet tid =9298 ms.Lad os teste funktionen med konstantområdet 2 til 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Planen for denne udførelse er vist i figur 5.
Denne gang er der ingen dyr flettelogik, da vagtrækkens del er irrelevant. Bemærk dog, at den returnerede kolonne er det manipulerede udtryk @low – 1 + rownum, som efter parameterindlejring/inlining og konstant foldning blev 1 + rownum.
Her er de tidsstatistikker, jeg fik for denne udførelse:
Som forventet er dette ikke så hurtigt som med et interval, der starter med 1, men interessant nok hurtigere end med et interval, der starter med 0.
I betragtning af at teknikken med vagtpostrækken med værdien 0 ser ud til at være langsommere end at anvende manipulation på rownum, giver det mening simpelthen at undgå det. Dette bringer os til en forenklet horisontal eliminationsbaseret løsning, der blander ideerne fra Alan, Charlie, Joe og mig selv. Jeg kalder funktionen med denne løsning dbo.GetNumsAlanCharlieJoeItzikBatch. Her er funktionens definition:
Lad os teste det med området 1 til 100M:
Planen er den samme som den, der er vist tidligere i figur 3, som forventet.
Derfor fik jeg følgende tidsstatistik:
Test det med intervallet 0 til 99.999.999:
Denne gang får du den samme plan som den, der er vist tidligere i figur 5 – ikke figur 4.
Her er de tidsstatistikker, jeg fik for denne udførelse:
Test det med området 2 til 100.000.001:
Igen får du den samme plan som den, der er vist tidligere i figur 5.
Jeg fik følgende tidsstatistik for denne udførelse:
Med teknikker til eliminering af både vertikale og horisontale enheder fungerer tingene ideelt, så længe du sender konstanter som input. Du skal dog være opmærksom på advarsler, der kan resultere i præstationsstraffe, når du passerer ikke-konstante input. Teknikken til eliminering af vertikale enheder har færre problemer, og de problemer, der findes, er nemmere at håndtere, så lad os starte med det.
Husk, at vi i denne artikel brugte funktionen dbo.GetNumsAlanCharlieItzikBatch som vores eksempel, der er afhængig af konceptet for lodret enhed eliminering. Lad os køre en række tests med ikke-konstante input, såsom variabler.
Som vores første test returnerer vi rn og beder om dataene bestilt af rn:
Husk, at rn repræsenterer det umanipulerede ROW_NUMBER-udtryk, så det faktum, at vi bruger ikke-konstante input, har ingen særlig betydning i dette tilfælde. Der er ikke behov for eksplicit sortering i planen.
Jeg fik følgende tidsstatistik for denne udførelse:
Disse tal repræsenterer det ideelle tilfælde.
I den næste test skal du bestille resultatrækkerne efter n:
Planen for denne udførelse er vist i figur 6.
Kan du se problemet? Efter inlining blev @low erstattet med @mylow—ikke med værdien i @mylow, som er 1. Konstant foldning fandt derfor ikke sted, og derfor er n ikke ordensbevarende i forhold til rownum. Dette resulterede i eksplicit sortering i planen.
Her er de tidsstatistikker, jeg fik for denne udførelse:
Udførelsestiden er næsten tredoblet i forhold til, hvor eksplicit sortering ikke var nødvendig.
En simpel løsning er at bruge Alan Bursteins oprindelige idé til altid at bestille efter rn, når du skal have resultatet bestilt, både når du returnerer rn og når du returnerer n, som sådan:
Denne gang er der ingen eksplicit sortering i planen.
Jeg fik følgende tidsstatistik for denne udførelse:
Tallene afspejler tilstrækkeligt det faktum, at du returnerer det manipulerede udtryk, men ikke pådrager sig nogen eksplicit sortering.
Med løsninger, der er baseret på den horisontale enheds-elimineringsteknik, såsom vores dbo.GetNumsAlanCharlieJoeItzikBatch-funktion, er situationen mere kompliceret, når der bruges ikke-konstante input.
Lad os først teste funktionen med et meget lille interval på 10 tal:
Planen for denne udførelse er vist i figur 7.
Der er en meget alarmerende side ved denne plan. Bemærk, at filteroperatorerne vises nedenunder de bedste operatører! I ethvert givet kald til funktionen med ikke-konstante input vil en af grenene under Sammenkædningsoperatoren naturligvis altid have en falsk filtertilstand. Begge topoperatører beder dog om et antal rækker, der ikke er nul. Så topoperatoren over operatoren med den falske filterbetingelse vil bede om rækker og vil aldrig være tilfreds, da filteroperatoren vil blive ved med at kassere alle rækker, som den får fra sin underordnede node. Arbejdet i undertræet under filteroperatoren skal køre til fuldførelse. I vores tilfælde betyder det, at undertræet vil gennemgå arbejdet med at generere 4B rækker, som Filter-operatoren vil kassere. Du undrer dig over, hvorfor filteroperatøren gider at anmode om rækker fra sin underordnede node, men det ser ud til, at det er sådan, det fungerer i øjeblikket. Det er svært at se dette med en statisk plan. Det er nemmere at se dette live, for eksempel med muligheden for udførelse af live-forespørgsler i SentryOne Plan Explorer, som vist i figur 8. Prøv det.
Det tog denne test 9:15 minutter at gennemføre på min maskine, og husk, at anmodningen var at returnere et interval på 10 numre.
Lad os tænke på, om der er en måde at undgå at aktivere det irrelevante undertræ i sin helhed. For at opnå dette, vil du gerne have, at opstartsfilteroperatørerne vises ovenfor topoperatørerne i stedet for under dem. Hvis du læser Fundamentals of table expressions, Del 4 – Afledte tabeller, optimeringsovervejelser, fortsat, ved du, at et TOP-filter forhindrer unnesting af tabeludtryk. Så alt hvad du skal gøre er at placere TOP-forespørgslen i en afledt tabel og anvende filteret i en ydre forespørgsel mod den afledte tabel.
Her er vores modificerede funktion, der implementerer dette trick:
Som forventet bliver henrettelser med konstanter ved med at opføre sig og udføre det samme som uden tricket.
Hvad angår ikke-konstante input, er det nu med små områder meget hurtigt. Her er en test med et interval på 10 numre:
Planen for denne udførelse er vist i figur 9.
Bemærk, at den ønskede effekt af at placere filteroperatorerne over topoperatorerne blev opnået. Ordningskolonnen n behandles dog som et resultat af manipulation og betragtes derfor ikke som en rækkefølgebevarende kolonne med hensyn til rækkenummer. Derfor er der eksplicit sortering i planen.
Test funktionen med et stort område på 100 millioner tal:
Jeg fik følgende tidsstatistik:
Hvilken nederdel; det var næsten perfekt!
Figur 10 har en oversigt over tidsstatistikken for de forskellige løsninger.
Så hvad har vi lært af alt dette? Jeg gætter på ikke at gøre det igen! Bare for sjov. Vi lærte, at det er mere sikkert at bruge konceptet vertikale eliminering som i dbo.GetNumsAlanCharlieItzikBatch, som afslører både det ikke-manipulerede ROW_NUMBER-resultat (rn) og det manipulerede (n). Bare sørg for, at når du skal returnere det bestilte resultat, skal du altid bestille efter rn, uanset om du returnerer rn eller n.
Hvis du er helt sikker på, at din løsning altid vil blive brugt med konstanter som input, kan du bruge konceptet til eliminering af horisontale enheder. Dette vil resultere i en mere intuitiv løsning for brugeren, da de vil interagere med en kolonne for de stigende værdier. Jeg vil stadig foreslå, at du bruger tricket med de afledte tabeller for at forhindre unnesting og placere Filter-operatorerne over de øverste operatorer, hvis funktionen nogensinde bruges med ikke-konstante input, bare for at være på den sikre side.
Vi er stadig ikke færdige endnu. Næste måned fortsætter jeg med at udforske yderligere løsninger. Figur 5:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch
Figur 5:Plan for dbo.GetNumsAlanCharlieJoeJeffItzikBatch Fjerner 0-vagtpostrækken
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Forbehold ved brug af ikke-konstante input
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000;
DECLARE @n AS BIGINT;
SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000;
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
 Figur 6:Plan for dbo.GetNumsAlanCharlieItzikBatch(@)mylow, @ orderingmy n
Figur 6:Plan for dbo.GetNumsAlanCharlieItzikBatch(@)mylow, @ orderingmy n DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000;
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10;
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
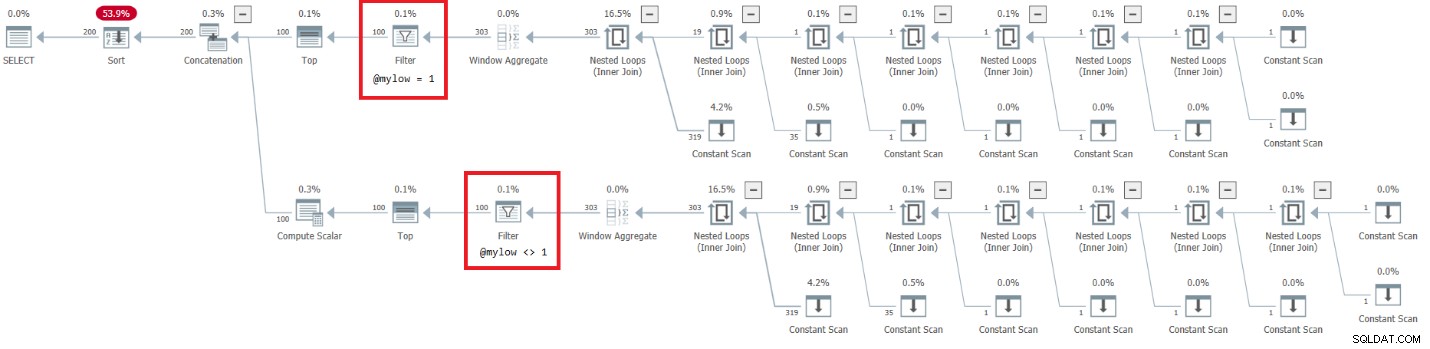 Figur 7:Plan for dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow), @myhigh)
Figur 7:Plan for dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow), @myhigh) 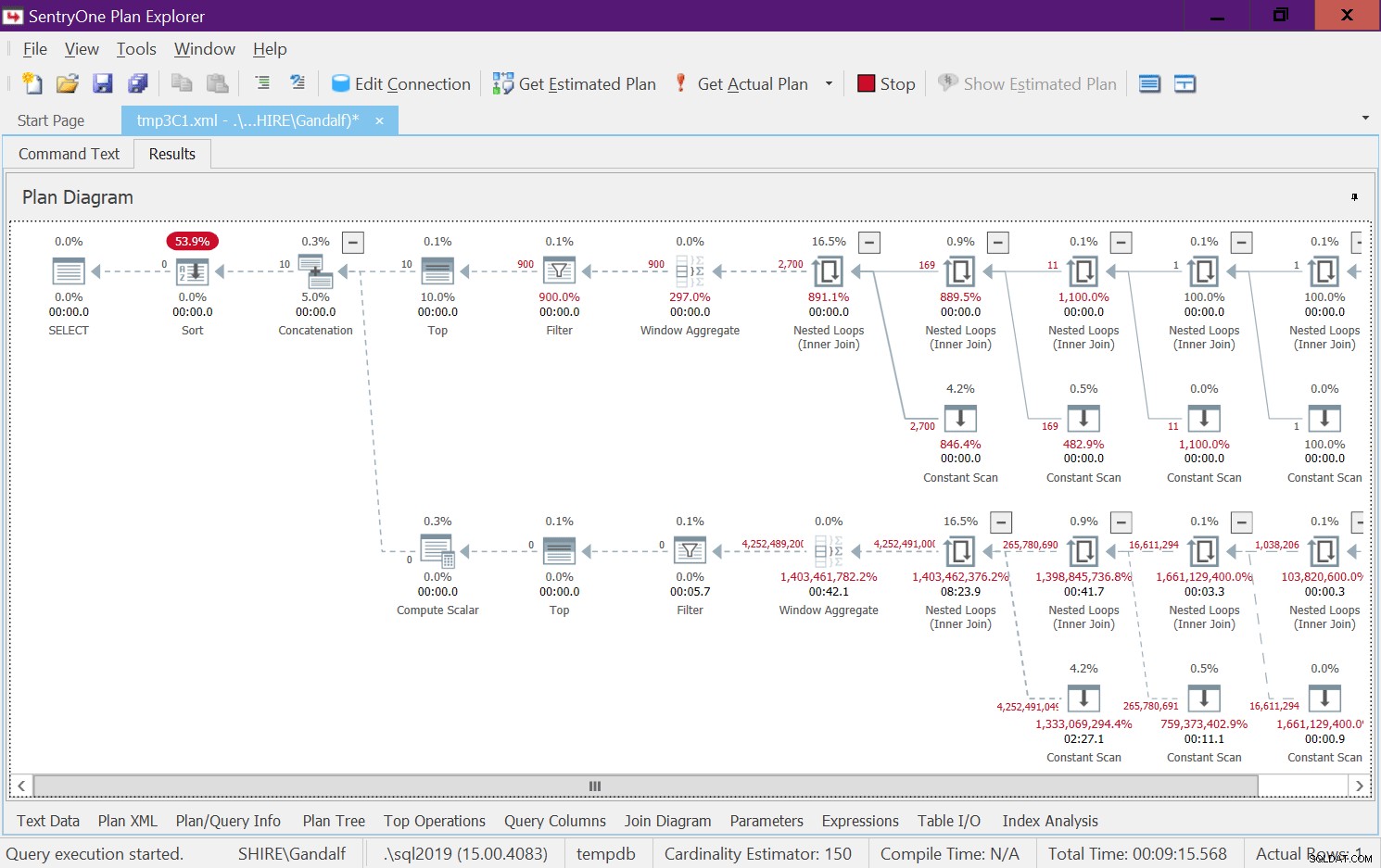 Figur 8:Direkte forespørgselsstatistik for dbo.GetNumsAlanCharlie @JoeItzikBat,chmy@highmylow,chmy
Figur 8:Direkte forespørgselsstatistik for dbo.GetNumsAlanCharlie @JoeItzikBat,chmy@highmylow,chmy CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10;
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
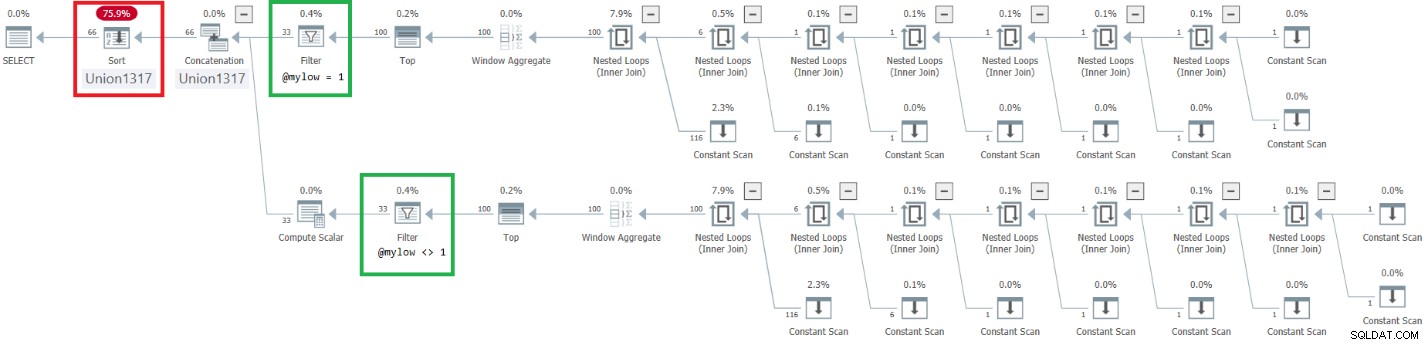 Figur 9:Plan for forbedret dbo.GetNumsAlanCharlieJoeItzikBatch @my@high)
Figur 9:Plan for forbedret dbo.GetNumsAlanCharlieJoeItzikBatch @my@high)DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000;
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Ydeevneoversigt og indsigt
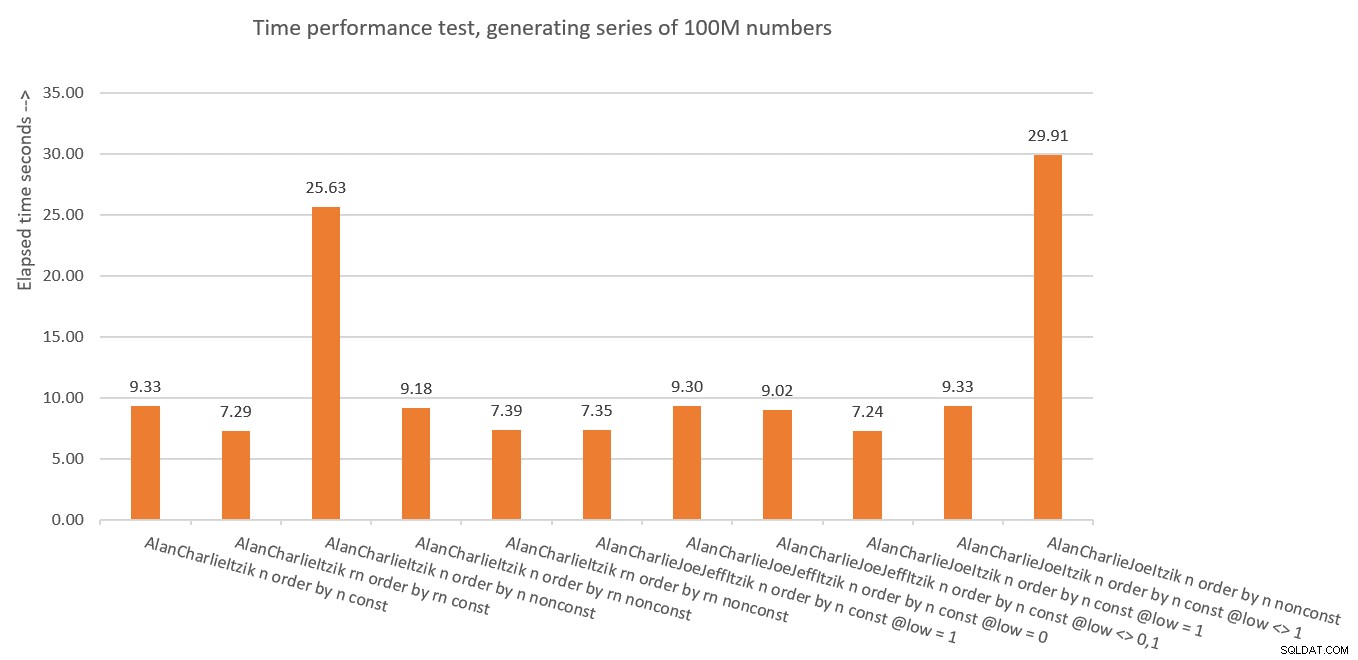 Figur 10:Oversigt over løsningernes ydeevne på tid
Figur 10:Oversigt over løsningernes ydeevne på tid