Som ethvert programmeringssprog har T-SQL sin andel af almindelige fejl og faldgruber, hvoraf nogle forårsager forkerte resultater og andre forårsager ydeevneproblemer. I mange af disse tilfælde er der bedste praksis, der kan hjælpe dig med at undgå at komme i problemer. Jeg undersøgte andre Microsoft Data Platform MVP'er og spurgte om de fejl og faldgruber, som de ser ofte, eller som de bare synes er særligt interessante, og den bedste praksis, de anvender for at undgå dem. Jeg har mange interessante sager.
Mange tak til Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser og Chan Ming Man for at dele din viden og erfaring!
Denne artikel er den første i en serie om emnet. Hver artikel fokuserer på et bestemt tema. Denne måned fokuserer jeg på fejl, faldgruber og bedste praksis, der er relateret til determinisme. En deterministisk beregning er en beregning, der med garanti giver gentagelige resultater givet de samme input. Der er mange fejl og faldgruber som følge af brugen af ikke-deterministiske beregninger. I denne artikel dækker jeg implikationerne af at bruge ikke-deterministisk rækkefølge, ikke-deterministiske funktioner, flere referencer til tabeludtryk med ikke-deterministiske beregninger og brugen af CASE-udtryk og NULLIF-funktionen med ikke-deterministiske beregninger.
Jeg bruger eksempeldatabasen TSQLV5 i mange af eksemplerne i denne serie.
Ikketerministisk rækkefølge
En almindelig kilde til fejl i T-SQL er brugen af ikke-deterministisk rækkefølge. Det vil sige, når din bestilling efter liste ikke entydigt identificerer en række. Det kunne være præsentationsbestilling, TOP/OFFSET-FETCH bestilling eller vinduesbestilling.
Tag for eksempel et klassisk personsøgningsscenarie med OFFSET-FETCH-filteret. Du skal forespørge i Sales.Orders-tabellen og returnere én side med 10 rækker ad gangen, sorteret efter ordredato, faldende (senest først). Jeg vil bruge konstanter til offset- og hente-elementerne for nemheds skyld, men typisk er de udtryk, der er baseret på inputparametre.
Følgende forespørgsel (kald det forespørgsel 1) returnerer den første side af de 10 seneste ordrer:
BRUG TSQLV5; SELECT orderid, orderdate, custid FRA Sales.Order BESTIL EFTER ordredato DESC OFFSET 0 RÆKER HENT KUN NÆSTE 10 RÆKKER;
Planen for forespørgsel 1 er vist i figur 1.
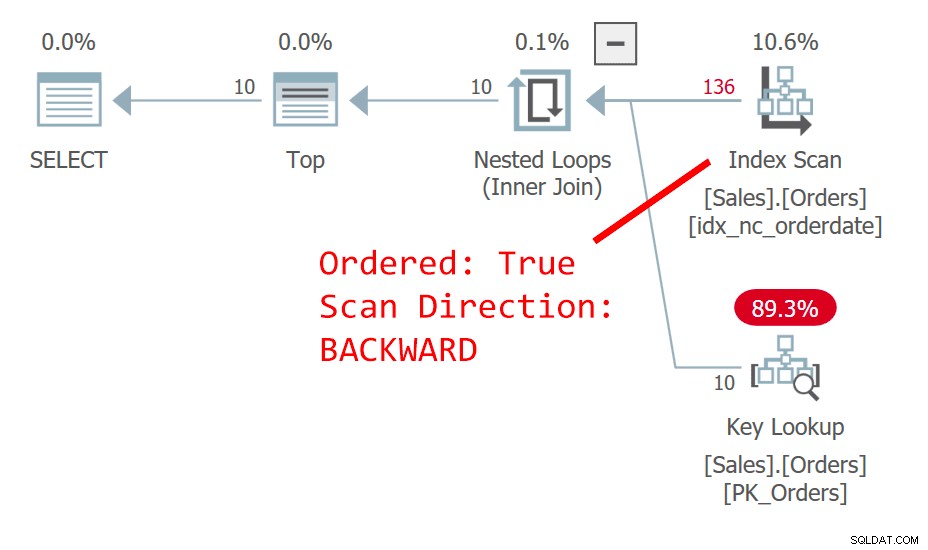 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Forespørgslen sorterer rækkerne efter ordredato, faldende. Kolonnen for ordredato identificerer ikke en række entydigt. Denne ikke-deterministiske rækkefølge betyder, at der begrebsmæssigt ikke er nogen præference mellem rækkerne med samme dato. I tilfælde af uafgjorte forhold er det, der afgør, hvilken række SQL Server vil foretrække, ting som planvalg og fysisk datalayout – ikke noget, du kan stole på som værende gentageligt. Planen i figur 1 scanner indekset på ordredatoen bestilt bagud. Det sker sådan, at denne tabel har et klynget indeks på orderid, og i en klynget tabel bruges den klyngede indeksnøgle som en rækkelokalisator i ikke-klyngede indekser. Det bliver faktisk implicit placeret som det sidste nøgleelement i alle ikke-klyngede indekser, selvom SQL Server teoretisk set kunne have placeret det i indekset som en inkluderet kolonne. Så implicit er det ikke-klyngede indeks på orderdate faktisk defineret på (orderdate, orderid). I vores bestilte baglæns scanning af indekset, mellem bundne rækker baseret på ordredato, tilgås en række med en højere orderid-værdi før en række med en lavere orderid-værdi. Denne forespørgsel genererer følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 2019 5019 5019 5019 5019 5019 1009 80 *** 11068 2019-05-04 62
Brug derefter følgende forespørgsel (kald det forespørgsel 2) for at få den anden side på 10 rækker:
VÆLG ordre-id, ordredato, custid FRA Salg. Ordrer BESTIL EFTER ordredato DESC OFFSET 10 RÆKER HENT KUN NÆSTE 10 RÆKKER;
Planen for forespørgsel er vist i figur 2.
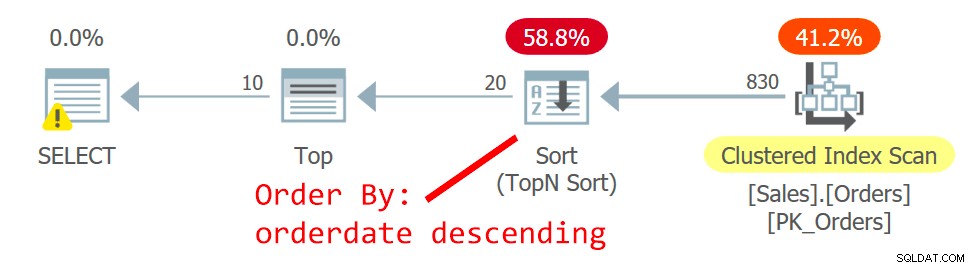
Figur 2:Plan for forespørgsel 2
Optimizeren vælger en anden plan - den ene scanner det klyngede indeks på en uordnet måde og bruger en TopN Sort til at understøtte Top-operatørens anmodning om at håndtere offset-hente-filteret. Årsagen til ændringen er, at planen i figur 1 bruger et ikke-klyngede, ikke-dækkende indeks, og jo længere siden du leder efter, jo flere opslag kræves der. Med den anden sideanmodning krydsede du det vendepunkt, der retfærdiggør brugen af det ikke-dækkende indeks.
Selvom scanningen af det klyngede indeks, som er defineret med orderid som nøglen, er uordnet, anvender lagermotoren en indeksordrescanning internt. Dette har at gøre med størrelsen af indekset. Op til 64 sider foretrækker lagringsmaskinen generelt indeksordrescanninger frem for allokeringsordrescanninger. Selvom indekset var større, under det læseforpligtede isolationsniveau og data, der ikke er markeret som skrivebeskyttet, bruger lagermotoren en indeksordrescanning for at undgå dobbeltlæsning og spring over rækker som følge af sideopdelinger, der opstår under scanning. Under de givne forhold, i praksis, mellem rækker med samme dato, får denne plan adgang til en række med et lavere ordensid før en med et højere ordensid.
Denne forespørgsel genererer følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 32 11062 6- 109 04-29 53 11058 2019-04-29 6
Bemærk, at selvom de underliggende data ikke ændrede sig, endte du med den samme ordre (med ordre-id 11069) returneret på både den første og anden side!
Forhåbentlig er den bedste praksis her klar. Tilføj en tiebreaker til din ordre efter liste for at få en deterministisk rækkefølge. For eksempel rækkefølge efter ordredato faldende, ordenid faldende.
Prøv igen at bede om den første side, denne gang med en deterministisk rækkefølge:
VÆLG ordre-id, ordredato, custid FRA Salg. Ordrer BESTIL EFTER ordredato DESC, ordre-id DESC OFFSET 0 RÆKKER HENT KUN NÆSTE 10 RÆKKER;
Du får garanteret følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 2019 5019 5019 5019 5019 5019 1009 80 11068 2019-05-04 62
Spørg efter den anden side:
VÆLG ordre-id, ordredato, custid FRA Salg. Ordrer BESTIL EFTER ordredato DESC, ordre-id DESC OFFSET 10 RÆKER HENT KUN NÆSTE 10 RÆKKER;
Du får garanteret følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 301 2019 2019 2019 2019 2019 2019 2019 2019 2019 67 11058 2019-04-29 6
Så længe der ikke var nogen ændringer i de underliggende data, er du garanteret at få fortløbende sider uden gentagelser eller spring over rækker mellem siderne.
På lignende måde kan du ved at bruge vinduesfunktioner som ROW_NUMBER med ikke-deterministisk rækkefølge få forskellige resultater for den samme forespørgsel afhængigt af planformen og den faktiske adgangsrækkefølge blandt båndene. Overvej følgende forespørgsel (kald det forespørgsel 3), implementering af anmodningen på første side ved hjælp af rækkenumre (tvinger brugen af indekset på ordredatoen til illustrationsformål):
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 OG 10;
Planen for denne forespørgsel er vist i figur 3:
Figur 3:Plan for forespørgsel 3
Du har meget lignende betingelser her som dem, jeg beskrev tidligere for forespørgsel 1 med dens plan, der blev vist tidligere i figur 1. Mellem rækker med bindinger i ordredatoværdierne får denne plan adgang til en række med en højere ordensværdi før en med en lavere ordreid værdi. Denne forespørgsel genererer følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 2019 5019 5019 5019 5019 5019 1009 80 *** 11068 2019-05-04 62
Kør derefter forespørgslen igen (kald det forespørgsel 4), og anmod om den første side, kun denne gang tvinge brugen af det klyngede indeks PK_Orders:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT orderid, orderdate, custid FROM C WHERE n MELLEM 1 OG 10;
Planen for denne forespørgsel er vist i figur 4.

Figur 4:Plan for forespørgsel 4
Denne gang har du meget lignende betingelser som dem, jeg beskrev tidligere for forespørgsel 2 med dens plan, der blev vist tidligere i figur 2. Mellem rækker med bindinger i ordredatoværdierne får denne plan adgang til en række med en lavere ordensværdi før en med en højere orderid værdi. Denne forespørgsel genererer følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 5-09 501-1009 5019 5019 2019 2019 2019 2019 2019 2019 2019 2019 17 *** 11068 2019-05-04 62
Bemærk, at de to udførelser gav forskellige resultater, selvom intet ændrede sig i de underliggende data.
Igen, den bedste praksis her er enkel – brug deterministisk rækkefølge ved at tilføje en tiebreaker, som sådan:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FRA C WHERE n MELLEM 1 OG 10;
Denne forespørgsel genererer følgende output:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 2019 5019 5019 5019 5019 5019 1009 80 11068 2019-05-04 62
Det returnerede sæt er garanteret gentageligt uanset planens form.
Det er nok værd at nævne, at da denne forespørgsel ikke har en præsentationsrækkefølge efter klausul i den ydre forespørgsel, er der ingen garanteret præsentationsrækkefølge her. Hvis du har brug for en sådan garanti, skal du tilføje en præsentationsrækkefølge efter klausul, som sådan:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FRA C WHERE n MELLEM 1 OG 10 BESTIL EFTER n;
Ikketerministiske funktioner
En ikke-deterministisk funktion er en funktion, der givet de samme input, kan returnere forskellige resultater i forskellige udførelser af funktionen. Klassiske eksempler er SYSDATETIME, NEWID og RAND (når de aktiveres uden et input-seed). Opførselen af ikke-deterministiske funktioner i T-SQL kan være overraskende for nogle og kan i nogle tilfælde resultere i fejl og faldgruber.
Mange mennesker antager, at når du kalder en ikke-deterministisk funktion som en del af en forespørgsel, bliver funktionen evalueret separat pr. række. I praksis bliver de fleste ikke-deterministiske funktioner evalueret én gang pr. reference i forespørgslen. Overvej følgende forespørgsel som et eksempel:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Da der kun er én reference til hver af de ikke-deterministiske funktioner SYSDATETIME og RAND i forespørgslen, evalueres hver af disse funktioner kun én gang, og dens resultat gentages på tværs af alle resultatrækker. Jeg fik følgende output, da jeg kørte denne forespørgsel:
orderid dt rnd ------------------ -------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0,962042872007464 11019 2019-02-04 17:03:07.9229177 0.96210207 0.9620107 0.96210207:01-96201407 0.96220107:01-9 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177774242444Som et eksempel, hvor ikke at forstå denne adfærd kan resultere i en fejl, antag, at du skal skrive en forespørgsel, der returnerer tre tilfældige ordrer fra Sales.Orders-tabellen. Et almindeligt indledende forsøg er at bruge en TOP-forespørgsel med bestilling baseret på RAND-funktionen, idet man tænker, at funktionen ville blive evalueret separat pr. række, som sådan:
SELECT TOP (3) orderid FROM Sales.Orders BESTILLING BY RAND();I praksis bliver funktionen kun evalueret én gang for hele forespørgslen; derfor får alle rækker det samme resultat, og bestilling er fuldstændig upåvirket. Faktisk, hvis du tjekker planen for denne forespørgsel, vil du ikke se nogen sorteringsoperator. Da jeg kørte denne forespørgsel flere gange, fik jeg det samme resultat:
orderid ---------- 11008 11019 11039Forespørgslen svarer faktisk til en uden en ORDER BY-klausul, hvor præsentationsrækkefølge ikke er garanteret. Så teknisk set er rækkefølgen ikke-deterministisk, og teoretisk set kan forskellige udførelser resultere i en anden rækkefølge og dermed et andet udvalg af top 3 rækker. Sandsynligheden for dette er dog lav, og du kan ikke tænke på, at denne løsning producerer tre tilfældige rækker i hver udførelse.
En undtagelse fra reglen om, at en ikke-deterministisk funktion aktiveres én gang pr. reference i forespørgslen, er NEWID-funktionen, som returnerer en globalt unik identifikator (GUID). Når den bruges i en forespørgsel, er denne funktion er påberåbes separat pr. række. Følgende forespørgsel viser dette:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;Denne forespørgsel genererede følgende output:
orderid mynewid ------------------ ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...Værdien af NEWID i sig selv er ret tilfældig. Hvis du anvender CHECKSUM-funktionen oven på den, får du et heltalsresultat med en endnu bedre tilfældig fordeling. Så en måde at få tre tilfældige ordrer på er at bruge en TOP-forespørgsel med bestilling baseret på CHECKSUM(NEWID()), som sådan:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Kør denne forespørgsel gentagne gange, og bemærk, at du får et andet sæt med tre tilfældige ordrer hver gang. Jeg fik følgende output i én udførelse:
orderid ---------- 11031 10330 10962Og følgende output i en anden udførelse:
orderid ---------- 10308 10885 10444Bortset fra NEWID, hvad hvis du har brug for at bruge en ikke-deterministisk funktion som SYSDATETIME i en forespørgsel, og du har brug for, at den skal evalueres separat pr. række? En måde at opnå dette på er at bruge en brugerdefineret funktion (UDF), der påkalder den ikke-deterministiske funktion, som sådan:
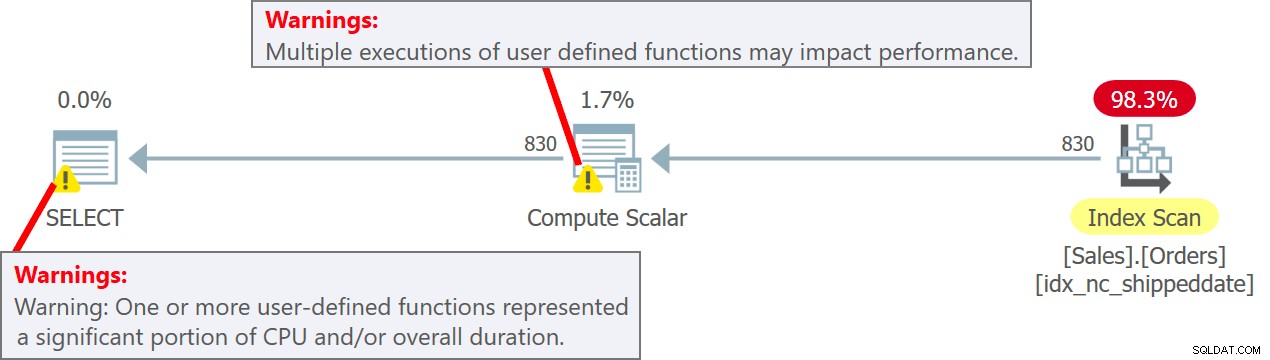
OPRET ELLER ÆNDRING FUNKTION dbo.MySysDateTime() RETURNERER DATETIME2 AS BEGIN RETURN SYSDATETIME(); ENDE; GÅDu påberåber derefter UDF i forespørgslen sådan (kald det Query 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FRA Sales.Orders;UDF'en bliver udført pr. række denne gang. Du skal dog være opmærksom på, at der er en ret skarp præstationsstraf forbundet med udførelsen af UDF pr. række. Desuden er påkaldelse af en skalar T-SQL UDF en parallelismehæmmer.
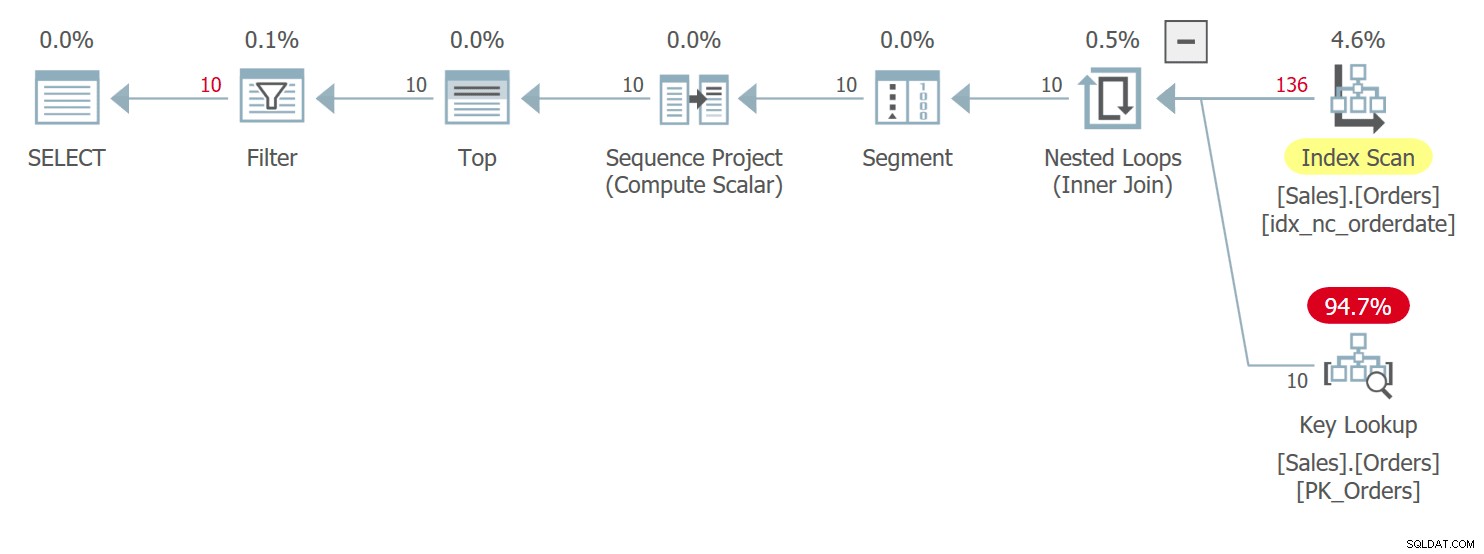
Planen for denne forespørgsel er vist i figur 5.
Figur 5:Plan for forespørgsel 5Bemærk i planen, at UDF'en faktisk bliver påkaldt pr. kilderække i Compute Scalar-operatoren. Bemærk også, at SentryOne Plan Explorer advarer dig om den potentielle præstationsstraf forbundet med brugen af UDF både i Compute Scalar-operatoren og i planens rodknude.
Jeg fik følgende output fra udførelsen af denne forespørgsel:
orderid mydt ------------------ -------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-200:2019-200:2019-2019-2019-2019-2019-2019:2019-200:2019-200-1 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07 .Bemærk, at outputrækkerne har flere forskellige dato- og tidsværdier i mydt-kolonnen.
Du har måske hørt, at SQL Server 2019 løser det almindelige ydeevneproblem forårsaget af skalære T-SQL UDF'er ved at inlinere sådanne funktioner. UDF skal dog opfylde en liste over krav for at være inlineable. Et af kravene er, at UDF ikke påberåber sig nogen ikke-deterministisk iboende funktion såsom SYSDATETIME. Begrundelsen for dette krav er, at du måske har oprettet UDF nøjagtigt for at få en udførelse pr. række. Hvis UDF'en blev inlinet, ville den underliggende ikke-deterministiske funktion kun blive udført én gang for hele forespørgslen. Faktisk blev planen i figur 5 genereret i SQL Server 2019, og du kan tydeligt se, at UDF'en ikke blev indlejret. Det skyldes brugen af den ikke-deterministiske funktion SYSDATETIME. Du kan kontrollere, om en UDF er inlinebar i SQL Server 2019 ved at forespørge om attributten is_inlineable i sys.sql_modules-visningen, som sådan:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Denne kode genererer følgende output, der fortæller dig, at UDF MySysDateTime ikke er inlineable:
is_inlineable ------------ 0For at demonstrere en UDF, der er inlinebar, er her definitionen af en UDF kaldet EndOfyear, der accepterer en inputdato og returnerer den respektive slutdato for året:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURDATO AS BEGIN RETURN DATEADD(år, DATEDIFF(år, '18991231', @dt), '18991231'); ENDE; GODer er ingen brug af ikke-deterministiske funktioner her, og koden opfylder også de andre krav til inlining. Du kan bekræfte, at UDF'en er inlinebar ved at bruge følgende kode:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Denne kode genererer følgende output:
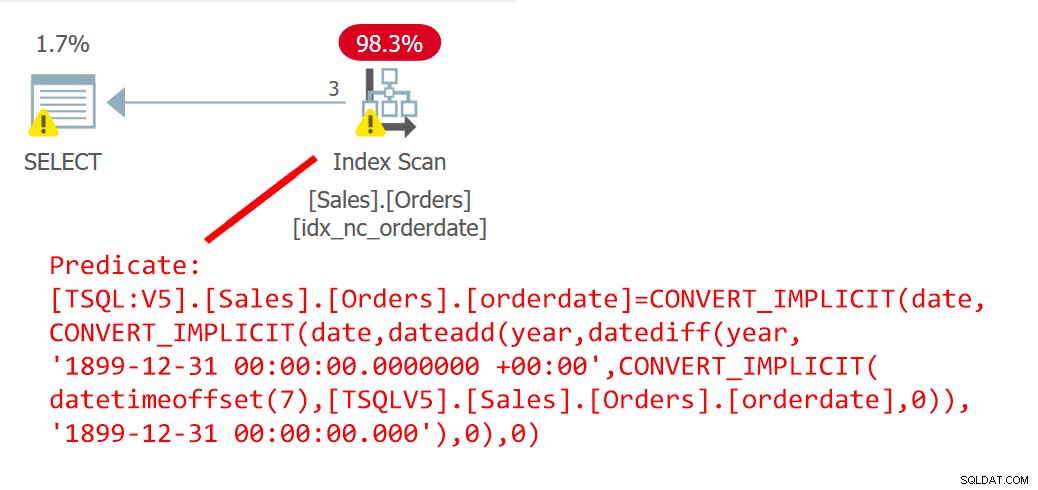
is_inlineable ------------- 1Følgende forespørgsel (kald det forespørgsel 6) bruger UDF EndOfYear til at filtrere ordrer, der blev afgivet på en slutningsdato for året:
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Planen for denne forespørgsel er vist i figur 6.
Figur 6:Plan for forespørgsel 6Planen viser tydeligt, at UDF fik indlejret sig.
Tabeludtryk, ikke-determinisme og flere referencer
Som nævnt kaldes ikke-deterministiske funktioner som SYSDATETIME én gang pr. reference i en forespørgsel. Men hvad hvis du refererer til en sådan funktion én gang i en forespørgsel i et tabeludtryk som en CTE, og derefter har en ydre forespørgsel med flere referencer til CTE? Mange mennesker er ikke klar over, at hver reference til tabeludtrykket udvides separat, og den indlejrede kode resulterer i flere referencer til den underliggende ikke-deterministiske funktion. Med en funktion som SYSDATETIME, afhængigt af den nøjagtige timing af hver af henrettelserne, kan du ende med at få et andet resultat for hver. Nogle mennesker finder denne adfærd overraskende.
Dette kan illustreres med følgende kode:
DECLARE @i AS INT =1, @rc AS INT =NULL; WHILE 1 =1 BEGIN; MED C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt FROM C1 UNION SELECT dt FROM C1 ) SELECT @rc =COUNT(*) FROM C2; HVIS @rc> 1 BREAK; SET @i +=1; ENDE; VÆLG @rc AS distinctvalues, @i AS iterationer;Hvis begge referencer til C1 i forespørgslen i C2 repræsenterede det samme, ville denne kode have resulteret i en uendelig løkke. Men da de to referencer udvides separat, når timingen er sådan, at hver påkaldelse finder sted i et forskelligt 100-nanosekunders interval (præcisionen af resultatværdien), resulterer foreningen i to rækker, og koden bør bryde fra sløjfe. Kør denne kode og se selv. Faktisk går den i stykker efter nogle gentagelser. Jeg fik følgende resultat i en af henrettelserne:
distinctvalues iterations -------------------- ----------- 2 448Den bedste praksis er at undgå at bruge tabeludtryk som CTE'er og visninger, når den indre forespørgsel bruger ikke-deterministiske beregninger, og den ydre forespørgsel refererer til tabeludtrykket flere gange. Det er selvfølgelig, medmindre du forstår implikationerne, og du er okay med dem. Alternative muligheder kunne være at fastholde det indre forespørgselsresultat, f.eks. i en midlertidig tabel, og derefter at forespørge den midlertidige tabel et vilkårligt antal gange, du har brug for.
For at demonstrere eksempler på, hvor det kan få dig i problemer, hvis du ikke følger den bedste praksis, skal du antage, at du skal skrive en forespørgsel, der parrer medarbejdere fra HR.Employees-tabellen tilfældigt. Du kommer med følgende forespørgsel (kald det forespørgsel 7) for at håndtere opgaven:
MED C AS (VÆLG empid, fornavn, efternavn, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FRA HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. efternavn AS efternavn1, C2.empid AS empid2, C2.fornavn AS fornavn2, C2.efternavn AS efternavn2 FRA C AS C1 INDRE JOIN C AS C2 PÅ C1.n =C2.n + 1;Planen for denne forespørgsel er vist i figur 7.
Figur 7:Plan for forespørgsel 7Bemærk, at de to referencer til C udvides separat, og rækkenumrene beregnes uafhængigt for hver reference sorteret efter uafhængige påkaldelser af CHECKSUM(NEWID())-udtrykket. Det betyder, at den samme medarbejder ikke er garanteret at få samme rækkenummer i de to udvidede referencer. Hvis en medarbejder får rækkenummer x i C1 og rækkenummer x – 1 i C2, vil forespørgslen parre medarbejderen med ham eller hende selv. For eksempel fik jeg følgende resultat i en af henrettelserne:
empid1 fornavn1 efternavn1 empid2 fornavn2 efternavn2 ----------- ---------- -------------------- ---------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russell King ***Bemærk, at der her er tre tilfælde af selv-par. Dette er nemmere at se ved at tilføje et filter til den ydre forespørgsel, der specifikt søger efter selvpar, som sådan:
MED C AS (VÆLG empid, fornavn, efternavn, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FRA HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. efternavn AS efternavn1, C2.empid AS empid2, C2.fornavn AS fornavn2, C2.efternavn AS efternavn2 FRA C AS C1 INNER JOIN C AS C2 PÅ C1.n =C2.n + 1 HVOR C1.empid =C2.empid;Du skal muligvis køre denne forespørgsel et antal gange for at se problemet. Her er et eksempel på resultatet, som jeg fik i en af henrettelserne:
empid1 fornavn1 efternavn1 empid2 fornavn2 efternavn2 ----------- ---------- -------------------- ---------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkI overensstemmelse med den bedste praksis er en måde at løse dette problem på at fortsætte det indre forespørgselsresultat i en midlertidig tabel og derefter forespørge flere forekomster af den midlertidige tabel efter behov.
Et andet eksempel illustrerer fejl, der kan skyldes brugen af ikke-deterministisk rækkefølge og flere referencer til et tabeludtryk. Antag, at du skal forespørge i Sales.Orders-tabellen, og for at lave trendanalyse, vil du parre hver ordre med den næste baseret på ordredato-bestilling. Din løsning skal være kompatibel med præ-SQL Server 2012-systemer, hvilket betyder, at du ikke kan bruge de åbenlyse LAG/LEAD-funktioner. Du beslutter dig for at bruge en CTE, der beregner rækkenumre til at placere rækker baseret på ordredato-rækkefølge, og derefter forbinde to forekomster af CTE'en, parre ordrer baseret på en offset på 1 mellem rækkenumrene, som sådan (kald denne forespørgsel 8):
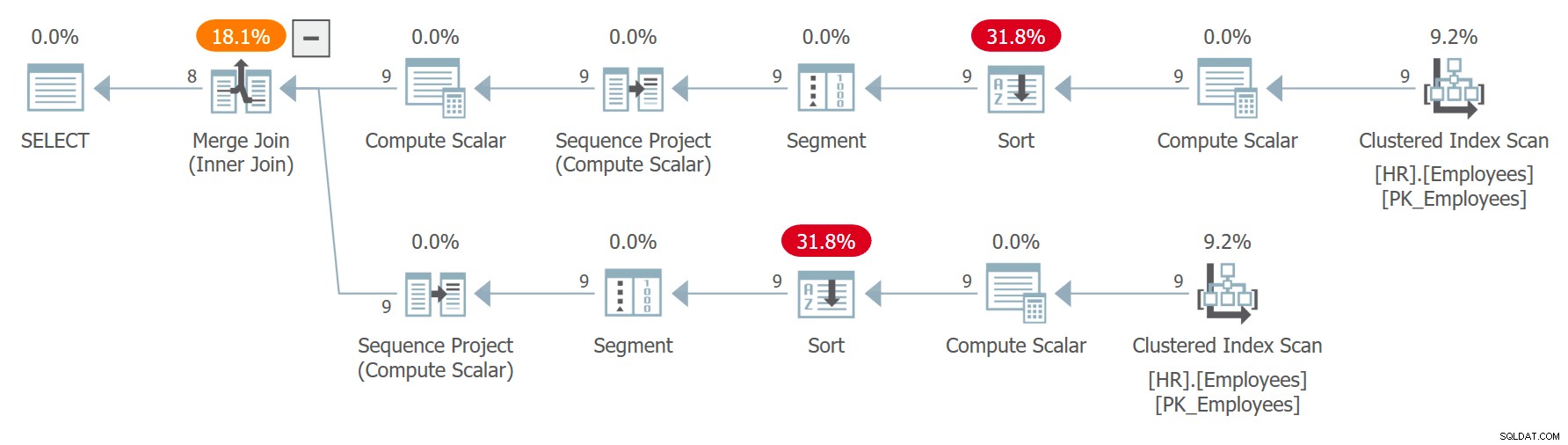
MED C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) VÆLG C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FRA C AS C1 VENSTRE YDRE JOIN C AS C2 PÅ C1.n =C2.n + 1;Planen for denne forespørgsel er vist i figur 8.
Figur 8:Plan for forespørgsel 8
Rækkenummerrækkefølgen er ikke deterministisk, da ordredato ikke er unik. Bemærk, at de to referencer til CTE udvides separat. Mærkeligt nok, da forespørgslen leder efter et andet undersæt af kolonner fra hver af forekomsterne, beslutter optimeringsværktøjet at bruge et andet indeks i hvert tilfælde. I et tilfælde bruger den en ordnet baglæns scanning af indekset på ordredato, og scanner effektivt rækker med den samme dato baseret på orden i faldende rækkefølge. I det andet tilfælde scanner den det klyngede indeks, ordnet falsk og sorterer derefter, men effektivt blandt rækker med samme dato, får den adgang til rækkerne i orden i stigende rækkefølge. Det skyldes lignende ræsonnement, som jeg gav i afsnittet om ikke-deterministisk rækkefølge tidligere. Dette kan resultere i, at den samme række får rækkenummer x i det ene tilfælde og rækkenummer x – 1 i det andet tilfælde. I et sådant tilfælde vil joinforbindelsen ende med at matche en ordre med sig selv i stedet for med den næste, som den skal.
Jeg fik følgende resultat, da jeg udførte denne forespørgsel:
orderid1 orderdate1 custid1 orderid2 orderdate2 ---------- ---------- ---------- ---------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 5-107 *** 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 110973 110973 10-20 5 20-10 20-1 05 *** ...Observer selvkampene i resultatet. Igen kan problemet lettere identificeres ved at tilføje et filter, der leder efter selv-matches, som sådan:
MED C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) VÆLG C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FRA C AS C1 VENSTRE YDRE JOIN C AS C2 PÅ C1.n =C2.n + 1 HVOR C1.orderid =C2.orderid;Jeg fik følgende output fra denne forespørgsel:
orderid1 orderdate1 custid1 orderid2 orderdate2 ---------- ---------- ---------- ---------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 60 62 01 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...Den bedste praksis her er at sikre, at du bruger unik rækkefølge for at garantere determinisme ved at tilføje en tiebreaker som orderid til vinduesrækkefølgen. Så selvom du har flere referencer til den samme CTE, vil rækkenumrene være de samme i begge. Hvis du ønsker at undgå gentagelsen af beregningerne, kan du også overveje at fastholde det indre forespørgselsresultat, men så skal du overveje de ekstra omkostninger ved et sådant arbejde.
CASE/NULLIF og ikke-deterministiske funktioner
Når du har flere referencer til en ikke-deterministisk funktion i en forespørgsel, bliver hver reference evalueret separat. Hvad der kunne være overraskende og endda resultere i fejl er, at nogle gange skriver du én reference, men implicit bliver den konverteret til flere referencer. Sådan er situationen med nogle anvendelser af CASE-udtrykket og IIF-funktionen.
Overvej følgende eksempel:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Lige' WHEN 1 THEN 'Ulige' END;Here the outcome of the tested expression is a nonnegative integer value, so clearly it has to be either even or odd. It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Konklusion
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!