Regneark – Excel, Google Sheets eller et ark med et hvilket som helst andet navn – er virkelig seje og kraftfulde værktøjer. Men altså, det er databaser også. Hvornår skal du holde dig til et regneark? Hvornår skal du flytte op til en database?
Dette er fortsættelsen af min tidligere artikel "Regneark vs. Databaser:Er det tid til at skifte?" hvor vi har diskuteret de mest almindelige ulemper ved at bruge regneark til at organisere masser af data. I denne artikel vil vi finde ud af, hvordan en database løser disse problemer.
Brug af en database til at organisere data
Mit motto er "brug den passende teknologi til dine behov". Hvis du kan drive din virksomhed via ark, fantastisk! Hvis du har brug for en simpel database, er MS Access ikke en dårlig mulighed. Men hvis disse produkter ikke virker for dig, har du sandsynligvis brug for en tilpasset database og en webapplikation. Databasen gemmer dine data; webappen vil være en brugervenlig måde at interagere med databasen og kommunikere med datalaget.
Vores fiktive servicevirksomhed var ikke særlig kompliceret, så vi kunne drive den ved hjælp af en ret simpel datamodel. Hvis du ser på billedet nedenfor, vil du se, at alt, hvad vi har brug for, er gemt i kun fem tabeller:client_type , client , service , replacement , og has_service .
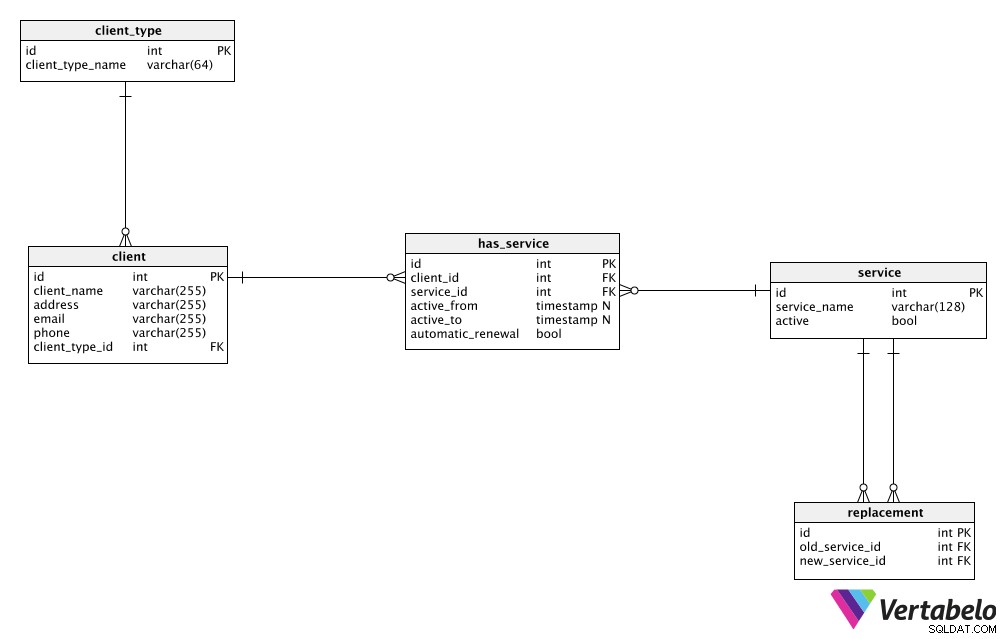
En nøgleregel for databasedesign er at opbevare relaterede data fra den virkelige verden ét sted . I dette tilfælde beholder vi alle vores client data i klienttabellen. På denne måde undgår vi at gemme de samme data flere steder (den dårlige form for redundans nævnt tidligere). Hvis vi ændrer noget relateret til en klient, gør vi det kun én gang i denne tabel. Dette vil i høj grad forbedre datakvaliteten og være godt for ydeevnen.
Den næste tabel, der indeholder data fra den virkelige verden, er service bord. Igen kan vi gemme alle detaljer relateret til vores tjenester her, og vi kan foretage ændringer i dataene ganske effektivt.
client tabellen og service tabellen er enheder i den virkelige verden, der kunne eksistere uden den anden. Men at oprette en database med ikke-relaterede enheder giver ikke for meget mening - det er som at have kunder uden produkter eller tjenester uden købere. Så vi relaterer disse to tabeller ved hjælp af has_service bord. For at gemme oplysninger om, hvilke klienter der har hvilken tjeneste, bruger vi fremmednøgler, der fungerer som referencer til den pågældende klient og tjeneste. Disse fremmednøgler peger tilbage til poster i tjeneste- og klienttabellerne. Vi kan også opbevare yderligere oplysninger relateret til hvert kunde-serviceforhold i denne tabel.
client_type tabel bruges som en ordbog, der gemmer alle mulige typer klienter. Det er bedst at opbevare forskellige segmenteringer i separate ordbogstabeller (hvis vi f.eks. havde kundetyper og medarbejderrolletyper, ville vi gemme dem i forskellige tabeller). Vi har dog kun brug for én tabel, fordi dette er en simpel model.
Den sidste tabel i vores model er replacement bord. Vi vil bruge det til at relatere to tjenester:en tjeneste, som vi ønsker at erstatte, og erstatningstjenesten. Dette giver os fleksibiliteten til at tilbyde kunder erstatninger for eksisterende tjenester (ligesom at skifte fra en mobilopkaldsplan til en anden).
Databasefordele
Databaser er mere komplicerede at oprette end regneark, men det giver dem faktisk nogle betydelige fordele med hensyn til dataintegritet og sikkerhed:
Nøgler og begrænsninger
Databaser har indbyggede regler og kontroller, der, hvis de bruges korrekt, vil forhindre de fleste problemer med datakvalitet og ydeevne. Primære nøgler (kolonner, der entydigt identificerer hver post i en tabel) og fremmednøgler (kolonner, der henviser til en post i en anden tabel) er afgørende for datasikkerheden, men definerer alternative eller UNIKKE nøgler (der indeholder data, der er unikke for hver post i en tabel) ) er også meget nyttigt.
I relationelle databaser relaterer nøgler data fra forskellige tabeller. Tabellens primære nøgle er altid UNIK, mens en fremmednøgle refererer til den primære nøgle fra en anden tabel. Denne reference relaterer data fra disse to tabeller (f.eks. fremmednøglerne i has_service tabel relaterer kundedata til de tjenester, de har). Det vil også advare os, hvis vi er ved at slette en primærnøgle, der henvises til i en anden tabel. Dette forhindrer os i at slette poster, der stadig er nødvendige (som referencer) i en anden tabel.
Begrænsninger definerer den type data, der kan indtastes i et felt. Vi kan angive, at dataene skal have værdi (IKKE NULL), definere et format for telefonnumre, kun indeholde bogstaver og så videre. Det betyder, at vi kan undgå dataproblemer fra folk, der indtaster den forkerte type data i et felt.
Sikkerhed og tilladelser
En anden meget vigtig databasefunktion er kontrol af adgang til dine data . Dette giver dig mulighed for ikke kun at angive, hvem der kan få adgang til din database, men også at kontrollere, hvad de kan se eller ændre. Dette er en stor del af datasikkerheden. For eksempel kan du definere en brugerrolle, der giver en medarbejder mulighed for at ændre kundeoplysninger, men ikke servicedetaljer. Du kan også sætte regler for, hvilke medarbejdere der kan ændre eller slette data. Det er en god standardpraksis at sikre, at folk kun har adgang til de data, de skal bruge for at udføre deres arbejde.
Selvfølgelig kunne vi forsøge at genskabe disse funktioner i ark (i hvert fald på en eller anden måde), men det ville helt sikkert være at "genopfinde hjulet".
Kunne vi ikke bare bruge et regneark?
Selvfølgelig kunne vi det. Vi kunne lave ark, der følger det samme mønster, der blev brugt i datamodellen. Det ville løse mange dataproblemer, men...
At kopiere datamodellen i ark er bestemt ikke en ideel mulighed. Vi ville miste alle de fordele, som databasesystemet giver os, alle regler og begrænsninger, der holder data "sunde", alle de ting, der forhindrer utilsigtede sletninger og andre fejl. Vi ville tabe på optimering, og hvis datasættet var stort nok, ville ydeevnen blive ramt.
Selvom vi løste det, hvad med at dele data, f.eks. har flere brugere, der bruger det samme ark på samme tid? Hvilke problemer med dataintegritet og ydeevne ville dette forårsage? Dette ville være det modsatte af at holde tingene enkle.
Så hvis du tror, at ark ikke kan håndtere dine forretningsbehov, er du sandsynligvis allerede på vej mod en database. Hvis du sidder fast med data gemt i ark, og du vil flytte til en database, bør du:
- Opret en databasemodel, der gemmer dine data optimalt.
- Byg et program med databasen i baggrunden.
- Ryd dine data, transformer dem (om nødvendigt), og importer dem til databasen.
- Fortsæt kun med at arbejde med databasen.
Hvad skal du vælge – regneark eller database?
I dagens artikel har vi lært, hvordan en database løser problemer med at bruge ark til at organisere masser af data. Mit råd er gå altid med den enkleste løsning på dit problem . Hvis regneark vil gøre arbejdet ordentligt, skal du bruge dem. Men hvis du er en datadrevet virksomhed, bør du begynde at bruge en database ASAP. Jo længere du venter med at rense og migrere dine data, jo mere smertefuld vil processen være.