Jeg har længe været fortaler for at vælge den rigtige datatype. Jeg har talt om nogle eksempler i et tidligere "Bad Habits" blogindlæg, men denne weekend på SQL Saturday #162 (Cambridge, UK), emnet for brug af DATETIME som standard kom op. I en samtale efter min T-SQL :Dårlige vaner og bedste praksis-præsentation, sagde en bruger, at de bare bruger DATETIME Selv hvis de kun har brug for detaljeret minut eller dag, er dato/klokkeslætskolonnerne på tværs af deres virksomhed altid den samme datatype. Jeg foreslog, at det kunne være spild, og at konsistensen måske ikke var det værd, men i dag besluttede jeg mig for at prøve at bevise min teori.
TL;DR-version
Min test nedenfor afslører, at der bestemt er scenarier, hvor du måske vil overveje at bruge en tyndere datatype i stedet for at holde fast i DATETIME overalt. Men det er vigtigt at se, hvor mine tests for dette pegede den anden vej, og det er også vigtigt at teste disse scenarier mod dit skema, i dit miljø, med hardware og data, der er så produktionstro som muligt. Dine resultater kan, og vil næsten helt sikkert, variere.
Destinationstabellerne
Lad os overveje det tilfælde, hvor granularitet kun er vigtig for dagen (vi er ligeglade med timer, minutter, sekunder). Til dette kunne vi vælge DATETIME (som den foreslåede bruger), eller SMALLDATETIME eller DATE på SQL Server 2008+. Der er også to forskellige typer data, som jeg ville overveje:
- Data, der ville blive indsat nogenlunde sekventielt i realtid (f.eks. begivenheder, der sker lige nu);
- Data, der vil blive indsat tilfældigt (f.eks. fødselsdatoer for nye medlemmer).
Jeg startede med 2 tabeller som følgende, og oprettede derefter 4 mere (2 for SMALLDATETIME, 2 for DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Gentag derefter for DATE og SMALLDATETIME.
Og mit mål var at teste batch-indsætningsydelse på disse to forskellige måder, såvel som indvirkningen på den samlede lagerstørrelse og fragmentering og endelig ydeevnen af rækkeforespørgsler.
Eksempel på data
For at generere nogle eksempeldata brugte jeg en af mine praktiske teknikker til at generere noget meningsfuldt fra noget, der ikke er:katalogvisningerne. På mit system returnerede dette 971 distinkte dato/tidsværdier (i alt 1.000.000 rækker) på cirka 12 sekunder:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) BESTIL EFTER NEWID()) VÆLG DISTINCT D FROM y;
Jeg satte disse millioner rækker i en tabel, så jeg kunne simulere sekventielle/tilfældige indsættelser ved hjælp af forskellige adgangsmetoder til nøjagtig de samme data fra tre forskellige sessionsvinduer:
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000_fROM sys. AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Denne proces tog lidt længere tid at fuldføre (20 sekunder). Derefter oprettede jeg en anden tabel til at gemme de samme data, men fordelt tilfældigt (så jeg kunne gentage den samme fordeling på tværs af alle inserts).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Forespørgsler til at udfylde tabellerne
Dernæst skrev jeg et sæt forespørgsler for at udfylde de andre tabeller med disse data, ved at bruge tre forespørgselsvinduer til at simulere mindst en lille smule samtidighed:
WAITFOR TIME '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- afhængig af metode / datatype SELECT source_date FROM dbo.Staging[_Random] -- afhængig af destination WHERE ID % 3 =<0,1,2> -- afhængig af forespørgselsvinduet ORDER VED ID; SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Som i mit sidste indlæg, udvidede jeg databasen på forhånd for at forhindre enhver form for automatisk væksthændelser for datafiler i at forstyrre resultaterne. Jeg er klar over, at det ikke er helt realistisk at udføre million-række-indsættelser på én gang, da jeg ikke kan forhindre logaktivitet for så stor en transaktion i at forstyrre, men det bør gøre det konsekvent på tværs af hver metode. I betragtning af, at den hardware, jeg tester med, er fuldstændig anderledes end den hardware, du bruger, bør de absolutte resultater ikke være en vigtig ting, men kun den relative sammenligning.
(I en fremtidig test vil jeg også prøve dette med rigtige batches, der kommer ind fra logfiler med relativt blandede data, og ved at bruge bidder af kildetabellen i loops – jeg tror også, det ville være interessante eksperimenter. Og selvfølgelig tilføjer komprimering i blandingen.)
Resultaterne:
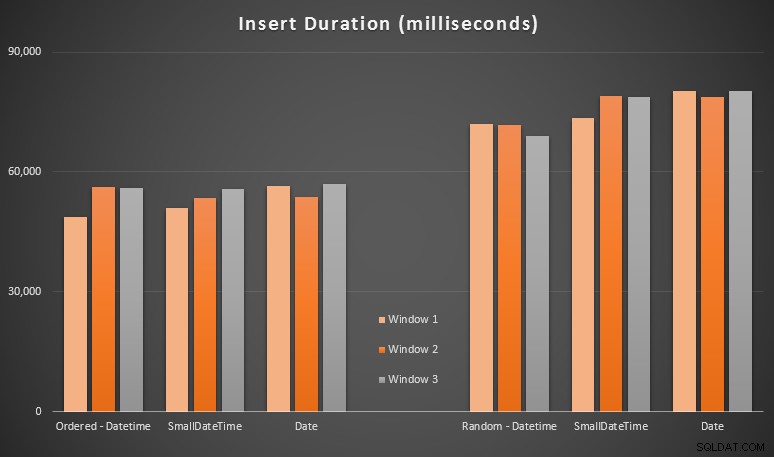
Disse resultater var ikke så overraskende for mig – indsættelse i tilfældig rækkefølge førte til længere køretider end indsættelse sekventielt, noget vi alle kan tage tilbage til vores rødder med at forstå, hvordan indekser i SQL Server fungerer, og hvordan flere "dårlige" sideopdelinger kan ske i dette scenarie (jeg overvågede ikke specifikt for sideopdelinger i denne øvelse, men det er noget, jeg vil overveje i fremtidige tests).
Jeg har bemærket, at på den tilfældige side, kan de implicitte konverteringer på de indgående data have haft en indflydelse på timings, da de virkede en lille smule højere end den oprindelige DATETIME -> DATETIME indsætter. Så jeg besluttede at bygge to nye tabeller indeholdende kildedata:en ved at bruge DATE og en bruger SMALLDATETIME . Dette ville simulere, til en vis grad, at konvertere din datatype korrekt, før den overføres til insert-sætningen, således at en implicit konvertering ikke er påkrævet under indsættelsen. Her er de nye tabeller, og hvordan de blev udfyldt:
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Dette havde ikke den effekt, jeg håbede på - timingen var ens i alle tilfælde. Så det var en vild gåsejagt.
Udnyttet plads og fragmentering
Jeg kørte følgende forespørgsel for at bestemme, hvor mange sider der var reserveret til hver tabel:
SELECT name ='dbo.' + OBJECT_NAME([object_id]), sider =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY sider;
Resultaterne:
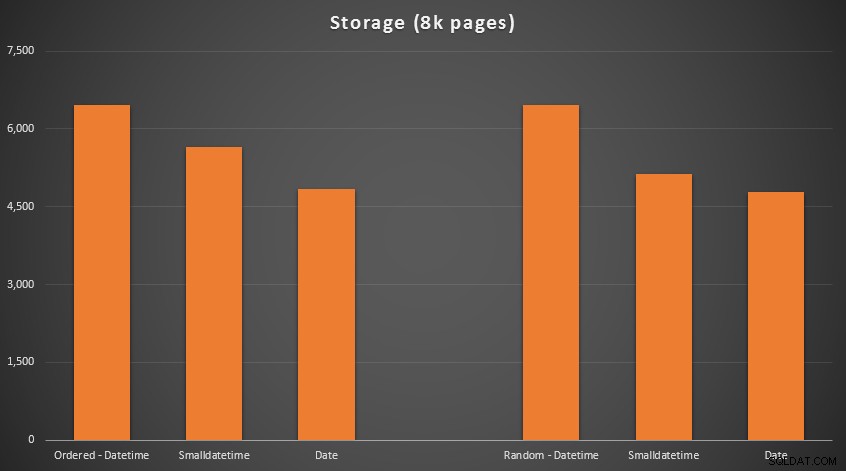
Ingen raketvidenskab her; bruge en mindre datatype, bør du bruge færre sider. Skifter fra DATETIME til DATE gav konsekvent en reduktion på 25 % i antallet af brugte sider, mens SMALLDATETIME reducerede kravet med 13-20%.
Nu til fragmentering og sidetæthed på de ikke-klyngede indekser (der var meget lille forskel for de klyngede indekser):
VÆLG '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED' index =_WELHERE'0; /pre>
Resultater:
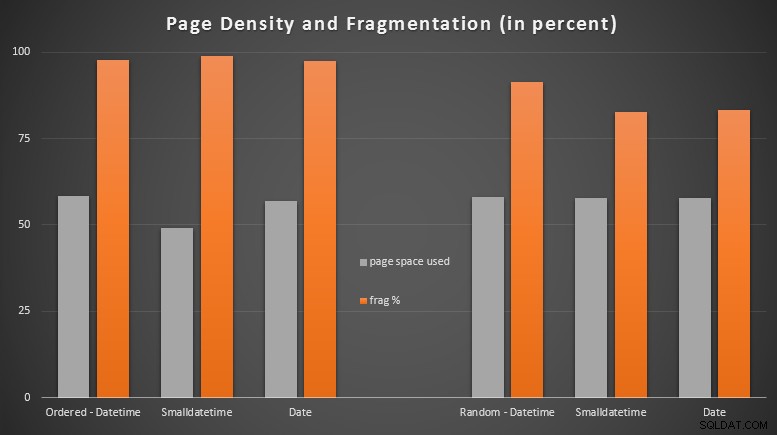
Jeg var ret overrasket over at se de bestilte data blive næsten fuldstændig fragmenterede, mens de data der blev indsat tilfældigt faktisk endte med en lidt bedre sidebrug. Jeg har noteret mig, at dette berettiger yderligere undersøgelser uden for rammerne af disse specifikke tests, men det kan være noget, du bør tjekke, hvis du har ikke-klyngede indekser, der stort set er afhængige af sekventielle inserts.
[En online-genopbygning af de ikke-klyngede indekser på alle 6 tabeller kørte på 7 sekunder, hvilket satte sidetætheden tilbage til 99,5 %-området og bragte fragmenteringen ned til under 1 %. Men jeg kørte det ikke, før jeg udførte forespørgselstestene nedenfor...]
Rangeforespørgselstest
Til sidst ville jeg se indvirkningen på kørselstider for simple datointervalforespørgsler mod de forskellige indekser, både med den iboende fragmentering forårsaget af skriveaktivitet af OLTP-typen og på et rent indeks, der genopbygges. Selve forespørgslen er ret enkel:
VÆLG TOP (200000) dt FRA dbo.{table_name} HVOR dt>='20110101' BESTIL EFTER dt;
Her er resultaterne før indekserne blev genopbygget ved hjælp af SQL Sentry Plan Explorer:
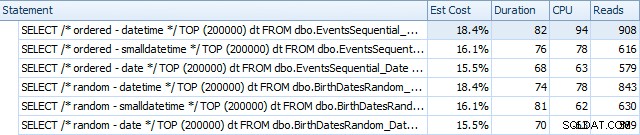
Og de adskiller sig lidt efter ombygningerne:
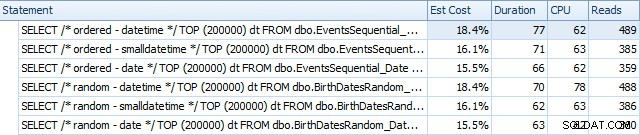
Grundlæggende ser vi lidt højere varighed og læsninger for DATETIME-versionerne, men meget lille forskel i CPU. Og forskellene mellem SMALLDATETIME og DATE er ubetydelige i sammenligning. Alle forespørgslerne havde forenklede forespørgselsplaner som denne:

(Søgningen er selvfølgelig en bestilt rækkeviddescanning.)
Konklusion
Selvom disse test ganske vist er ret fabrikerede og kunne have haft gavn af flere permutationer, viser de nogenlunde, hvad jeg forventede at se:Den største indvirkning på dette specifikke valg er på plads optaget af det ikke-klyngede indeks (hvor valg af en tyndere datatype vil helt sikkert fordel), og på den tid, der kræves for at udføre indsættelser i vilkårlig, snarere end sekventiel, rækkefølge (hvor DATETIME har kun en marginal kant).
Jeg ville elske at høre dine ideer til, hvordan man kan sætte datatypevalg som disse gennem mere grundige og straffende tests. Jeg planlægger at gå ind i flere detaljer i fremtidige indlæg.