Parameterdatatyper
Som nævnt i den første del af denne serie, er en af grundene til, at det er bedre at eksplicit parametrisere, så du har fuld kontrol over parameterdatatyper. Simpel parameterisering har en række særheder på dette område, som kan resultere i, at flere parametriserede planer bliver cachelagret end forventet, eller at man finder andre resultater sammenlignet med den uparametriserede version.
Når SQL Server anvender simpel parameterisering til en ad-hoc-erklæring giver den et gæt om datatypen for erstatningsparameteren. Jeg vil dække årsagerne til gætten senere i serien.
Lad os indtil videre se på nogle eksempler på brug af Stack Overflow 2010-databasen på SQL Server 2019 CU 14. Databasekompatibilitet er sat til 150, og omkostningstærsklen for parallelitet er sat til 50 for at undgå parallelisme indtil videre:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 25221;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252552; Disse udsagn resulterer i seks cachelagrede planer, tre Adhoc og tre Forberedt :
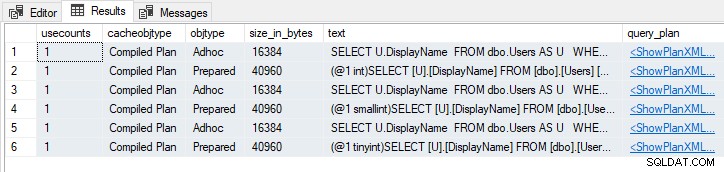 Forskellige gættede typer
Forskellige gættede typer
Bemærk de forskellige parameterdatatyper i Forberedt planer.
Datatypeinferens
Detaljerne om, hvordan hver datatype gættes, er komplekse og ufuldstændigt dokumenterede. Som udgangspunkt udleder SQL Server en grundlæggende type ud fra den tekstlige repræsentation af værdien og bruger derefter den mindste kompatible undertype.
For en streng af tal uden anførselstegn eller et decimaltegn, vælger SQL Server fra tinyint , smallint , og integer . For sådanne tal uden for rækkevidden af et integer , SQL Server bruger numeric med mindst mulig præcision. For eksempel er tallet 2.147.483.648 indtastet som numeric(10,0) . bigint type bruges ikke til parametrering på serversiden. Dette afsnit forklarer de datatyper, der er valgt i de foregående eksempler.
Strænger af tal med et decimaltegn fortolkes som numeric , med en præcision og skala lige stor nok til at indeholde den angivne værdi. Strenge med et valutasymbol som præfiks tolkes som money . Strenge i videnskabelig notation oversættes til float . smallmoney og real typer er ikke ansat.
datetime og uniqueidentifer typer kan ikke udledes fra naturlige strengformater. For at få en datetime eller uniqueidentifier parametertype, skal den bogstavelige værdi angives i ODBC-escape-format. For eksempel {d '1901-01-01'} , {ts '1900-01-01 12:34:56.790'} , eller {guid 'F85C72AB-15F7-49E9-A949-273C55A6C393'} . Ellers skrives den påtænkte dato eller UUID-literal som en streng. Andre dato- og tidstyper end datetime ikke bruges.
Generel streng og binære literaler skrives som varchar(8000) , nvarchar(4000) , eller varbinary(8000) efter behov, medmindre den bogstavelige overskridelse overstiger 8000 bytes, i hvilket tilfælde max variant anvendes. Denne ordning hjælper med at undgå cache-forurening og lave genbrugsniveau, som ville følge af brug af specifikke længder.
Det er ikke muligt at bruge CAST eller CONVERT for at indstille datatypen for parametre af årsager, jeg vil detaljere senere i denne serie. Der er et eksempel på dette i næste afsnit.
Jeg vil ikke dække tvungen parameterisering i denne serie, men jeg vil gerne nævne, at reglerne for datatype-inferens i så fald har nogle vigtige forskelle sammenlignet med simpel parameterisering . Tvunget parametrisering blev ikke tilføjet før SQL Server 2005, så Microsoft havde mulighed for at inkorporere nogle lektioner fra den enkle parameterisering erfaring, og behøvede ikke at bekymre sig meget om problemer med bagudkompatibilitet.
Numeriske typer
For tal med et decimalkomma og hele tal uden for området for integer , giver de udledte typeregler særlige problemer for plangenbrug og cacheforurening.
Overvej følgende forespørgsel med decimaler:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
SomeValue decimal(19,8) NOT NULL
);
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 987.65432
AND T.SomeValue < 123456.789;
Denne forespørgsel kvalificerer til simpel parameterisering . SQL Server vælger den mindste præcision og skala for de parametre, der kan indeholde de leverede værdier. Det betyder, at den vælger numeric(8,5) for 987.65432 og numeric(9,3) for 123456.789 :
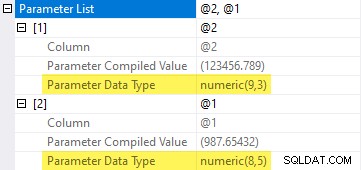 Udledte numeriske datatyper
Udledte numeriske datatyper
Disse udledte typer matcher ikke decimal(19,8) type af kolonnen, så en konvertering omkring parameteren vises i udførelsesplanen:
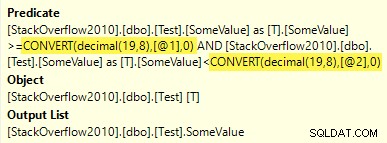 Konvertering til kolonnetype
Konvertering til kolonnetype
Disse konverteringer repræsenterer kun en lille runtime ineffektivitet i dette særlige tilfælde. I andre situationer kan et misforhold mellem kolonnedatatypen og den udledte type af en parameter forhindre en indekssøgning eller kræve, at SQL Server udfører ekstra arbejde for at fremstille en dynamisk søgning.
Selv hvor den resulterende udførelsesplan virker rimelig, kan en typemismatch nemt påvirke plankvaliteten på grund af effekten af typemismatchet på kardinalitetsestimat. Det er altid bedst at bruge matchende datatyper og være omhyggelig opmærksom på de afledte typer, der stammer fra udtryk.
Planlæg genbrug
Hovedproblemet med den nuværende plan er de specifikke udledte typer, der påvirker cachelagret planmatching og derfor genbrug. Lad os køre et par forespørgsler mere af samme generelle form:
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 98.76
AND T.SomeValue < 123.4567;
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 1.2
AND T.SomeValue < 1234.56789;
GO Se nu på planens cache:
SELECT
CP.usecounts,
CP.objtype,
ST.[text]
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) AS ST
WHERE
ST.[text] NOT LIKE '%dm_exec_cached_plans%'
AND ST.[text] LIKE '%SomeValue%Test%'
ORDER BY
CP.objtype ASC; Det viser en AdHoc og Forberedt erklæring for hver forespørgsel, vi sendte:
 Særskilte forberedte erklæringer
Særskilte forberedte erklæringer
Den parametriserede tekst er den samme, men parameterdatatyperne er forskellige, så separate planer cachelagres, og der forekommer ingen plangenbrug.
Hvis vi fortsætter med at indsende forespørgsler med forskellige kombinationer af skala eller præcision, vil en ny Forberedt planen oprettes og cachelagres hver gang. Husk, at den udledte type af hver parameter ikke er begrænset af kolonnedatatypen, så vi kan ende med et enormt antal cachelagrede planer, afhængigt af de indsendte numeriske bogstaver. Antallet af kombinationer fra numeric(1,0) til numeric(38,38) er allerede stor, før vi tænker på flere parametre.
Eksplicit parametrering
Dette problem opstår ikke, når vi bruger eksplicit parameterisering, idet vi ideelt set vælger den samme datatype som den kolonne, parameteren sammenlignes med:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DECLARE
@stmt nvarchar(4000) =
N'SELECT T.SomeValue FROM dbo.Test AS T WHERE T.SomeValue >= @P1 AND T.SomeValue < @P2;',
@params nvarchar(4000) =
N'@P1 numeric(19,8), @P2 numeric(19,8)';
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 987.65432,
@P2 = 123456.789;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 98.76,
@P2 = 123.4567;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 1.2,
@P2 = 1234.56789; Med eksplicit parameterisering viser plancache-forespørgslen kun én plan cachelagret, brugt tre gange, og ingen typekonverteringer er nødvendige:
 Eksplicit parameterisering
Eksplicit parameterisering
Som en sidste sidebemærkning har jeg brugt decimal og numeric i flæng i dette afsnit. De er teknisk forskellige typer, selvom det er dokumenteret at være synonymer og opfører sig ens. Dette er normalt tilfældet, men ikke altid:
-- Raises error 8120: -- Column 'dbo.Test.SomeValue' is invalid in the select list -- because it is not contained in either an aggregate function -- or the GROUP BY clause. SELECT CONVERT(decimal(19,8), T.SomeValue) FROM dbo.Test AS T GROUP BY CONVERT(numeric(19,8), T.SomeValue);
Det er sandsynligvis en lille parser-fejl, men det kan stadig betale sig at være konsekvent (medmindre du skriver en artikel og vil påpege en interessant undtagelse).
Aritmetiske operatorer
Der er en anden kantsag, jeg vil tage fat på, baseret på et eksempel givet i dokumentationen, men lidt mere detaljeret (og måske nøjagtighed):
-- The dbo.LinkTypes table contains two rows -- Uses simple parameterization SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization due to -- constant-constant comparison SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT WHERE 1 = 1;
Resultaterne er forskellige, som dokumenteret:
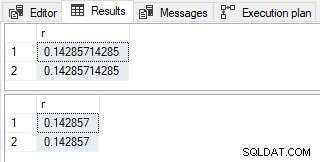 Forskellige resultater
Forskellige resultater
Med simpel parametrering
Når simpel parameterisering forekommer, parametrerer SQL Server begge bogstavelige værdier. 1. værdi indtastes som numeric(1,0) som forventet. Noget inkonsekvent er 7 er skrevet som integer (ikke tinyint ). Reglerne for typeslutning er blevet bygget over tid af forskellige hold. Adfærd opretholdes for at undgå at bryde ældre kode.
Det næste trin involverer / aritmetisk operator. SQL Server kræver kompatible typer før opdelingen udføres. Givet numeric (decimal ) har en højere datatypeprioritet end integer , integer vil blive konverteret til numeric .
SQL Server skal implicit konvertere integer til numeric . Men hvilken præcision og skala skal man bruge? Svaret kunne være baseret på den originale bogstavelige, som SQL Server gør under andre omstændigheder, men den bruger altid numeric(10) her.
Datatypen for resultatet af at dividere en numeric(1,0) med en numeric(10,0) bestemmes af en anden regelsæt, angivet i dokumentationen for præcision, skala og længde. Ved at sætte tallene ind i formlerne for resultatpræcision og skala givet der, har vi:
- Resultatpræcision:
- p1 – s1 + s2 + max(6, s1 + p2 + 1)
- =1 – 0 + 0 + maks.(6, 0 + 10 + 1)
- =1 + maks.(6, 11)
- =1 + 11
- =12
- Resultatskala:
- max(6, s1 + p2 + 1)
- =max(6, 0 + 10 + 1)
- =max(6, 11)
- =11
Datatypen 1. / 7 er derfor numeric(12, 11) . Denne værdi konverteres derefter til float som anmodet og vist som 0.14285714285 (med 11 cifre efter decimaltegnet).
Uden Simple Parameterization
Når simpel parameterisering ikke udføres, vises 1. literal skrives som numeric(1,0) som før. 7 er oprindeligt skrevet som integer også som tidligere set. Den vigtigste forskel er integer konverteres til numeric(1,0) , så divisionsoperatøren har almindelige typer at arbejde med. Dette er den mindste præcision og skala, der kan indeholde værdien 7 . Husk simpel parameterisering brugt numeric(10,0) her.
Præcisions- og skalaformlerne til at dividere numeric(1,0) ved numeric(1,0) giv en resultatdatatype numeric(7,6) :
- Resultatpræcision:
- p1 – s1 + s2 + max(6, s1 + p2 + 1)
- =1 – 0 + 0 + maks.(6, 0 + 1 + 1)
- =1 + maks.(6, 2)
- =1 + 6
- =7
- Resultatskala:
- max(6, s1 + p2 + 1)
- =max(6, 0 + 1 + 1)
- =max(6, 2)
- =6
Efter den endelige konvertering til float , det viste resultat er 0.142857 (med seks cifre efter decimaltegnet).
Den observerede forskel i resultaterne skyldes derfor midlertidig typeafledning (numeric(12,11) vs. numeric(7,6) ) i stedet for den endelige konvertering til float .
Hvis du har brug for yderligere beviser, konverteringen til float ikke er ansvarlig, overvej:
-- Simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT OPTION (MAXDOP 1);
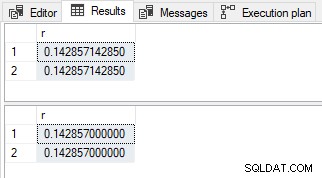 Resultat med decimal
Resultat med decimal
Resultaterne er forskellige i værdi og skala som før.
Denne sektion dækker ikke alle særheder ved datatypeslutning og konvertering med simpel parameterisering på nogen måde. Som sagt før, er du bedre stillet at bruge eksplicitte parametre med kendte datatyper, hvor det er muligt.
Slut på del 2
Den næste del af denne serie beskriver hvordan simpel parameterisering påvirker udførelsesplaner.