At arrangere børnefester er ikke en nem opgave:alt skal være perfekt planlagt og leveret. Ellers opstår der kaos. Det er op til de voksne – mere specifikt festplanlæggerne – at tage sig af alt og gøre det ordentligt.
Er der en bedre måde at gøre dette på end at organisere alt i en database? Det tror vi ikke!
Børnefester varierer meget. Nogle er enkle, som fødselsdagsfester, der kun inkluderer invitationer, mad (snacks, drikkevarer og en kage) og måske en klovn eller en tryllekunstner til at underholde børnene. Andre partier er meget mere komplekse. De kan kræve en tur ud af byen, sovepladser og mange andre aktiviteter. Jo mere kompliceret festen er, jo mindre plads til fejl. Selvom en klovn, der er 10 minutter forsinket, ikke er en big deal, er der ingen, der ønsker at vente med en gruppe kede børn på en bus, der er to timer forsinket!
Lad os se, hvad en datamodel kan gøre for at hjælpe festplanlæggere med at holde sig organiseret.
Hvad har vi brug for i vores datamodel?
Lad os antage, at vi driver en festplanlægningsvirksomhed. Vi har en liste over tjenester, som vi tilbyder til kunder. Disse tjenester kan leveres af os, eller vi kan bruge partnere (f.eks. hyrer vi klovnen).
Vi kombinerer disse tjenester og tilbyder dem til kunderne som en festpakke. Hver pakke har et start- og slutpunkt eller tidsplan. Dette inkluderer ikke kun selve festen, men at sætte festen op og rydde op bagefter. Vi kan også have flere steder (f.eks. starter en fest med pizza på en restaurant og flytter derefter til stranden for at svømme).
Vi skal også relatere aktiviteter til medarbejdere, spore festernes fremskridt og opkræve betaling for vores tjenester. Lad os se, hvordan dette gøres.
Børnefestdatamodellen
Vores børnefestdatamodel består af fire emneområder:
Lande og byerPartnere og tjenesterMedarbejdere og rollerFest
Vi præsenterer hvert emneområde i samme rækkefølge, som det er angivet.
Afsnit 1:Lande og byer
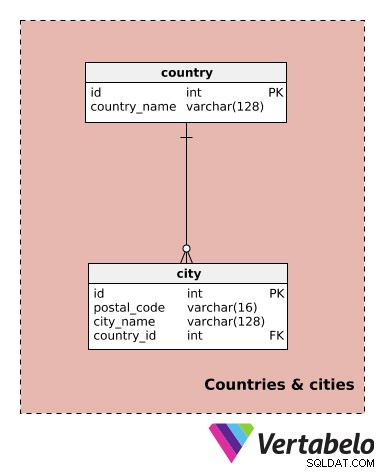
Dette emneområde indeholder kun to tabeller. De er ikke specifikke for denne model, men vi vil bruge dem i andre fagområder.
Vi kan forvente at operere i flere byer og måske endda i flere lande. Derfor skal vi henvise til forskellige byer. Dette vil hjælpe os med at spore, hvor festerne er placeret, og også hvilke tjenester vi tilbyder på hver lokation.
landet ordbogen indeholder kun det UNIKKE landsnavn værdi. For hver by , gemmer vi den UNIKKE kombination af postal_code – bynavn – country_id .
Afsnit 2:Partnere og tjenester
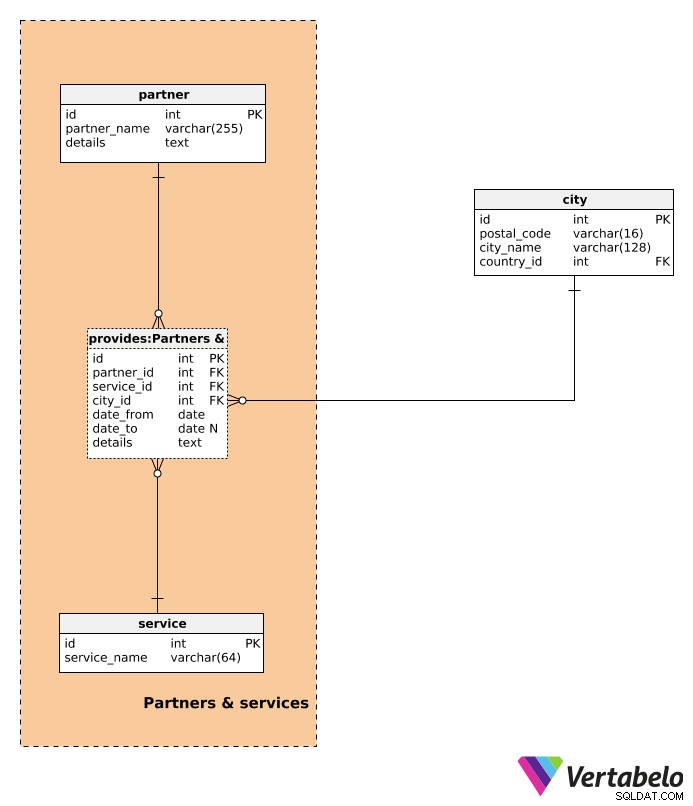
Lad os derefter beskrive de tjenester, vi vil levere til vores kunder.
En liste over alle mulige tjenester er gemt i tjenesten ordbog. Den indeholder kun det UNIKKE service_name attribut.
I denne datamodel leveres alle tjenester af partnere. Selv når vores virksomhed faktisk leverer tjenesten, behandler vi den som en partner service (og vi er partneren). Partnerordbogen gemmer alle partnere, vi samarbejder med, inklusive os. For hver partner gemmer vi et UNIKT partner_name . detaljerne attribut gemmer alle yderligere detaljer relateret til den pågældende partner ved hjælp af et ustruktureret eller struktureret format (f.eks. ved hjælp af navn-værdi-par adskilt af foruddefineret separator).
partner_id–partnerender leverer en tjeneste.service_id–tjenestendenne partner leverer.by_id– Henviser tilbyenhvor denne service leveres af den pågældende partner.dato_fra– Datoen, hvor partneren begyndte at tilbyde denne tjeneste.dato_til– Datoen, hvor partneren stoppede med at tilbyde denne tjeneste. Denne værdi kan være NULL, hvis dette service-partnerforhold stadig er i gang.detaljer– Alle yderligere detaljer relateret til den pågældende tjeneste, såsom tjenestebeskrivelse, pris osv. Vi kan forvente, at alle detaljer vil være i et struktureret tekstformat, ved hjælp af nøgle-værdi-par.
Kombinationen af partner_id – service_id – by_id – dato_fra danner den UNIKKE nøgle i denne tabel. Når vi indtaster en ny post, bør vi kontrollere, at den ikke overlapper med eksisterende poster.
Afsnit 3:Medarbejdere og roller
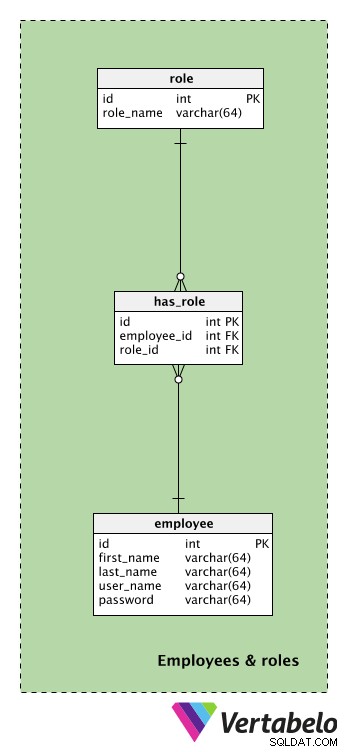
Før vi går over til den centrale og vigtigste del af vores model, er vi nødt til at se på tabellerne relateret til vores medarbejdere og deres roller.
Den centrale tabel i dette emneområde er medarbejderen bord. For hver medarbejder gemmer vi deres first_name , efternavn , brugernavn og adgangskode . De bruger disse to sidste attributter til at få adgang til vores applikation.
En liste over alle mulige roller er gemt i rollen ordbog. Hver rolle er UNIKT defineret af dens rolle_name . Roller er relateret til handlinger, som hver medarbejder udfører under en fest. Derfor kan vi forvente værdier som "festleder" eller "assistent" her.
Roller kan tildeles til medarbejdere ved hjælp af has_role bord. employee_id – rolle_id par vil angive de aktive roller, hver medarbejder har på det tidspunkt.
Afsnit 4:Part
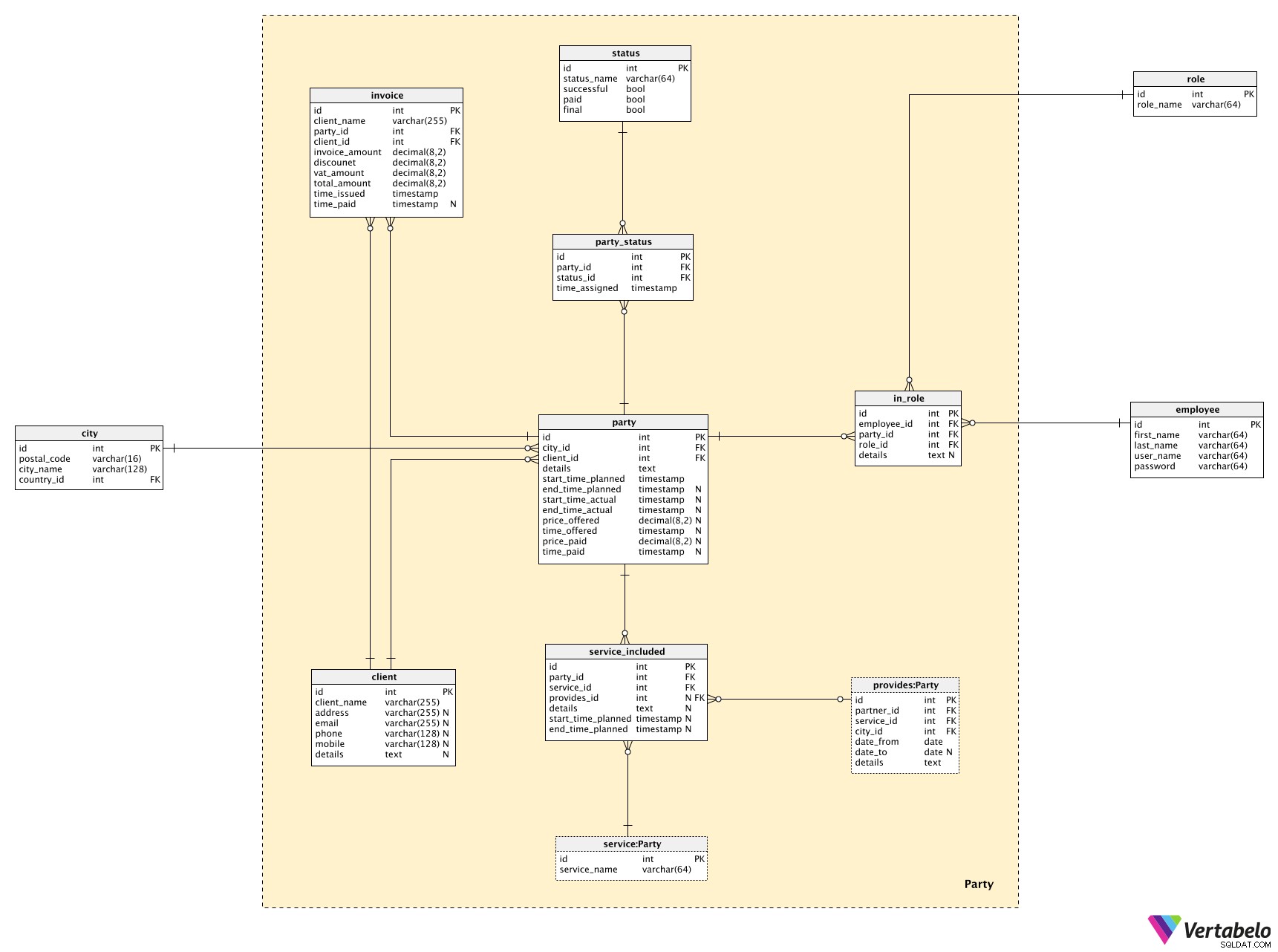
Festen fagområdet er den centrale del af denne model. Vi vil bruge det til at relatere tabeller fra andre fagområder, og vi vil også have nogle nye oplysninger her.
Den centrale tabel her er partiet bord. For hver part gemmer vi:
by_id–byenhvor festen finder sted.klient_id–klientendenne fest er arrangeret for.detaljer– En detaljeret tekstbeskrivelse af festen.planlagt_starttidspunktogend_time_planned– Det tidspunkt, vi har planlagt til denne fest, inklusive opsætning og oprydning.start_tidspunkt_faktiskogend_time_actual– De faktiske tidspunkter, hvor festen (og dens relaterede tjenester) fandt sted.pris_tilbuddet– Den pris, vi citerede for at organisere denne fest for denne klient.tid_tilbuddet– Hvornår tilbuddet blev afgivet.pris_betalt– Det faktiske beløb, kunden har betalt for denne fest.tid_betalt– Hvornår betalingen blev foretaget.
Hver part er relateret til en klient. Vi har allerede henvist til klienten tabel, men nu vil vi se, hvad der er gemt der. Jeg gik kun med grundlæggende data:client_name , kontaktoplysninger (adresse , e-mail , telefon , mobil ), og eventuelle yderligere detaljer i tekstformat.
Hver part vil også have en liste over tjenester tilknyttet. Denne liste er gemt i service_included bord. For hver post har vi brug for:
party_id– Henviser til den relateredepart.service_id– Henviser tiltjenesteninkluderet i partiet.leverer_id– Henviser tiludbyderenaf denne service, såvel som selve servicen. Denne attribut kan være NULL, da vi opdaterer den, når vi vælger den specifikke udbyder.detaljer– Eventuelle yderligere tekstmæssige detaljer relateret til den pågældende tjeneste i den pågældende part.planlagt_starttidspunktogend_time_planned– De planlagte tidspunkter, hvor servicen skal ydes under festen.
Vi bliver også nødt til at spore hver parts fremskridt. Vi bruger to tabeller til at gøre dette.
status tabel vil vise alle mulige statusser, der kan tildeles en part. For hver post gemmer vi et UNIKT status_name og tre flag:
vellykket– Gik alt godt? Eller var der problemer med vores tjenester?betalt– Er festen blevet betalt?endelig– Er dette den endelige status for denne fest?
Vi tildeler statusser til tjenester ved at tilføje nye registreringer til party_status bord. For hver post gemmer vi referencer til parten og service tabeller og tidsstemplet når denne status blev tildelt.
Den sidste tabel i vores model er fakturaen bord. Det er ikke specifikt for denne model, men vi har brug for en grundlæggende struktur til at opbevare fakturaer. For hver faktura registrerer vi:
klientnavn– Kundens navn på det tidspunkt, hvor fakturaen blev udstedt.party_id–partietrelateret til denne faktura.klient_id– ID'et forklientenbliver faktureret.fakturabeløb,rabat,moms_beløb,total_amount– De økonomiske detaljer for fakturaen.tid_udstedt- Når denne faktura blev udstedt eller tilføjet til databasen.tid_betalt- Hvornår denne faktura blev betalt.
Hvad ville du gøre med denne datamodel?
Denne model er ret ligetil, men jeg ser flere måder, vi kan forbedre den på. Hvilke ændringer vil du foreslå? Er der noget, vi kunne organisere anderledes? Måske skal vi tilføje eller fjerne en funktion. Fortæl os venligst i kommentarerne.