Introduktion
- Der er nogle specifikke regler, som skal følges, mens du opretter databaseobjekterne. For at forbedre ydeevnen af en database bør en primær nøgle, klyngede og ikke-klyngede indekser og begrænsninger tildeles en tabel. Selvom vi følger alle disse regler, kan duplikerede rækker stadig forekomme i en tabel.
- Det er altid en god praksis at gøre brug af databasenøglerne. Brug af databasenøglerne vil reducere chancerne for at få duplikerede poster i en tabel. Men hvis duplikerede poster allerede er til stede i en tabel, er der specifikke måder, der bruges til at fjerne disse duplikerede poster.
Måder at fjerne duplikerede rækker
- Brug af DELETE JOIN sætning for at fjerne dublerede rækker
DELETE JOIN-sætningen findes i MySQL, som hjælper med at fjerne duplikerede rækker fra en tabel.
Overvej en database med navnet "studentdb". Vi vil oprette en tabelelev ind i den.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
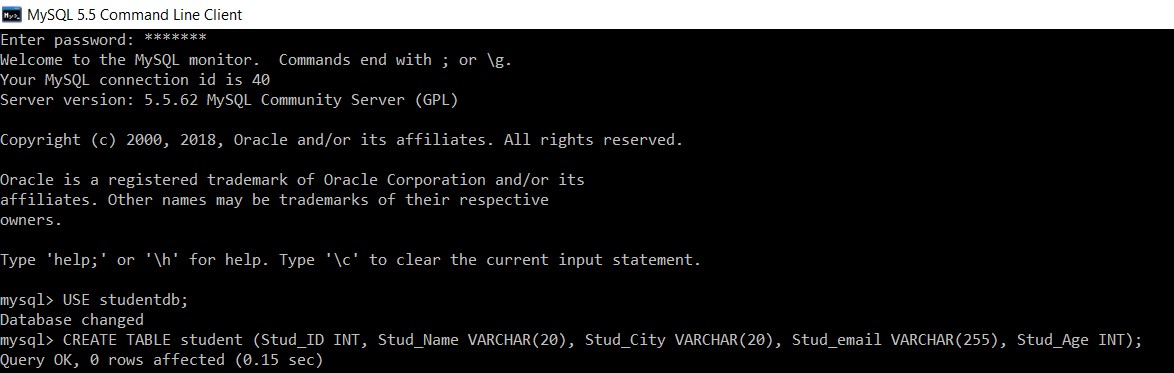
Vi har oprettet en 'student'-tabel i 'studentdb'-databasen.
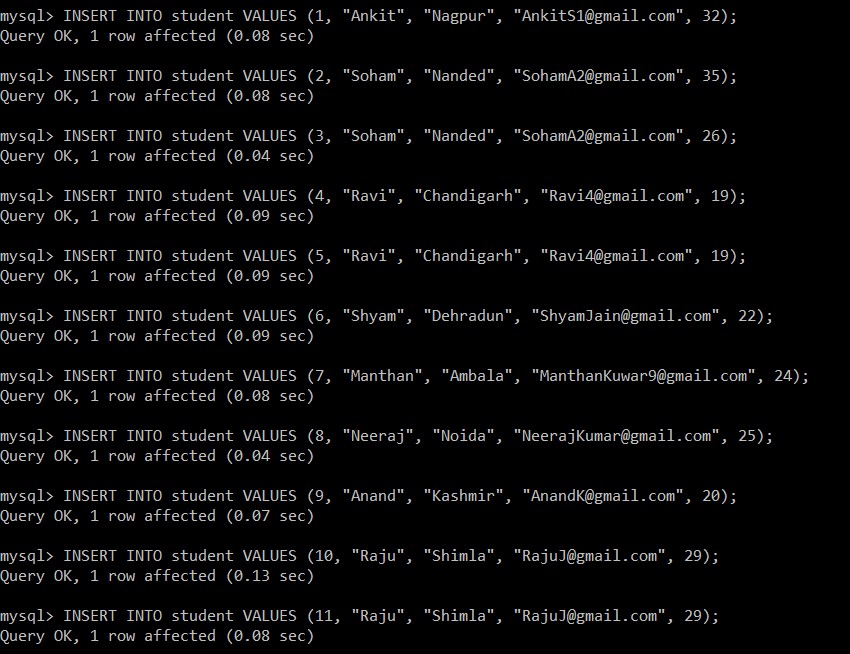
Nu vil vi skrive følgende forespørgsler for at indsætte data i elevtabellen.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
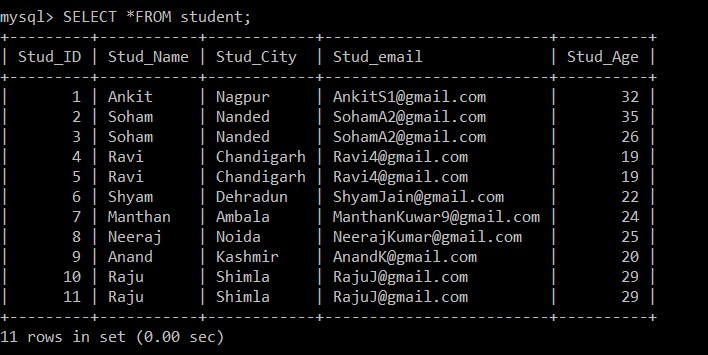
Nu vil vi hente alle posterne fra elevbordet. Vi vil overveje denne tabel og database for alle de følgende eksempler.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Eksempel 1:
Skriv en forespørgsel for at slette dublerede rækker fra elevtabellen ved hjælp af DELETE JOIN erklæring.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email; Vi har brugt DELETE-forespørgslen med INNER JOIN. For at implementere INNER JOIN på en enkelt tabel har vi oprettet to instanser s1 og s2. Derefter har vi ved hjælp af WHERE-sætningen kontrolleret to betingelser for at finde ud af de duplikerede rækker i elevtabellen. Hvis e-mail-id'et i to forskellige poster er det samme, og elev-id'et er forskelligt, vil det blive behandlet som en dubletpost i henhold til WHERE-klausulens betingelse.
Output:
Query OK, 3 rows affected (0.20 sec) Resultaterne af ovenstående forespørgsel viser, at der er tre duplikerede poster til stede i elevtabellen.

Vi vil bruge SELECT-forespørgslen til at finde de duplikerede poster, der blev slettet.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
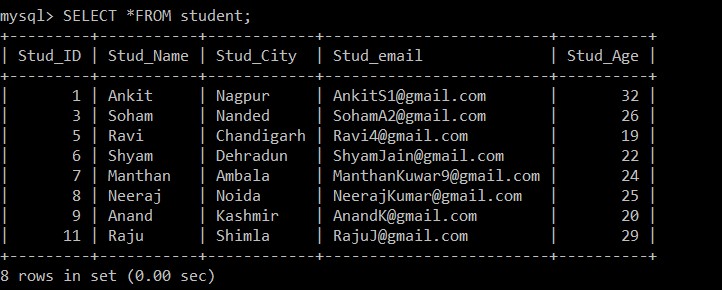
Nu er der kun 8 poster, der er til stede i elevtabellen, da de tre duplikerede poster slettes fra den aktuelt valgte tabel. I henhold til følgende betingelse:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email; Hvis e-mail-id'erne for to poster er de samme, da mindre end-tegnet bruges mellem elev-id'et, vil kun posten med større medarbejder-id'er blive opbevaret, og den anden dubletpost vil blive slettet mellem de to poster.
Eksempel 2:
Skriv en forespørgsel for at slette duplikerede rækker fra elevtabellen ved hjælp af delete join-erklæringen, mens du beholder dubletposten med et mindre medarbejder-id og sletter den anden.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email; Vi har brugt DELETE-forespørgslen med INNER JOIN. For at implementere INNER JOIN på en enkelt tabel har vi oprettet to instanser s1 og s2. Derefter har vi ved hjælp af WHERE-sætningen kontrolleret to betingelser for at finde ud af duplikatrækkerne i elevtabellen. Hvis e-mail-id'et, der findes i to forskellige poster, er det samme, og elev-id'et er forskelligt, vil det blive behandlet som en dubletpost i henhold til WHERE-klausulens betingelse.
Output:
Query OK, 3 rows affected (0.09 sec) Resultaterne af ovenstående forespørgsel viser, at der er tre duplikerede poster til stede i elevtabellen.

Vi vil bruge SELECT-forespørgslen til at finde de duplikerede poster, der blev slettet.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
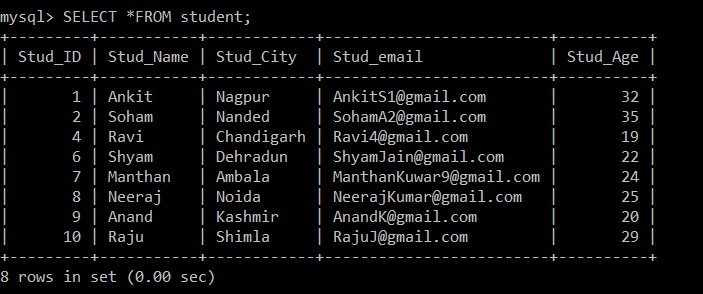
Nu er der kun 8 poster, der er til stede i elevtabellen, da de tre duplikerede poster slettes fra den aktuelt valgte tabel. I henhold til følgende betingelse:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email; Hvis e-mail-id'erne for to poster er de samme, da større end-tegnet bruges mellem elev-id'et, vil kun posten med det mindste medarbejder-id blive opbevaret, og den anden dubletpost vil blive slettet blandt de to poster.
- Brug af en mellemtabel til at fjerne dublerede rækker
Følgende trin skal følges, mens du fjerner de duplikerede rækker ved hjælp af en mellemtabel.
- Der skal oprettes en ny tabel, som vil være den samme som den faktiske tabel.
- Tilføj forskellige rækker fra den faktiske tabel til den nyoprettede tabel.
- Slip den faktiske tabel og omdøb den nye tabel med samme navn som en faktisk tabel.
Eksempel:
Skriv en forespørgsel for at slette de duplikerede poster fra elevtabellen ved at bruge en mellemtabel.
Trin 1:
Først vil vi oprette en mellemtabel, der vil være den samme som medarbejdertabellen.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Her er 'medarbejder' den oprindelige tabel og 'temp_student' er mellemtabellen.
Trin 2:
Nu vil vi kun hente de unikke poster fra elevtabellen og indsætte alle de hentede poster i temp_student tabellen.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Her, før du indsætter de distinkte poster fra elevtabellen i temp_student, filtreres alle duplikatposterne af Stud_email. Så er det kun posterne med unikke e-mail-id'er, der er indsat i temp_student.
Trin 3:
Derefter vil vi fjerne elevtabellen og omdøbe tabellen temp_student til elevtabellen.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
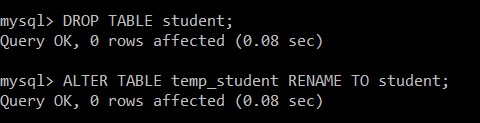
Elevtabellen er fjernet, og temp_student omdøbes til elevtabellen, som kun indeholder de unikke poster.
Derefter skal vi verificere, at elevtabellen nu kun indeholder de unikke poster. For at bekræfte dette har vi brugt SELECT-forespørgslen til at se dataene i elevtabellen.
mysql> SELECT *FROM student; Output:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
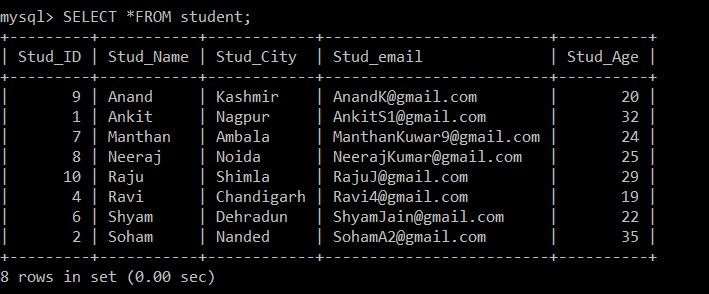
Nu er der kun 8 poster, der er til stede i elevtabellen, da de tre duplikerede poster slettes fra den aktuelt valgte tabel. I trin 2, mens man hentede de forskellige poster fra den originale tabel og indsatte dem i en mellemtabel, blev der brugt en GROUP BY-klausul på Stud_email, så alle posterne blev indsat baseret på elevernes e-mail-id'er. Her holdes kun posten med et lavere medarbejder-id blandt de duplikerede poster som standard, og den anden slettes.