Du ved sikkert, hvordan du indsætter poster i en tabel ved hjælp af enkelte eller flere VALUES-sætninger. Du ved også, hvordan man laver masseindsættelser ved hjælp af SQL INSERT INTO SELECT. Men du har stadig klikket på artiklen. Handler det om at håndtere dubletter?
Mange artikler dækker SQL INSERT INTO SELECT. Google eller Bing it, og vælg den overskrift, du bedst kan lide – det gør det. Jeg vil heller ikke dække grundlæggende eksempler på, hvordan det gøres. I stedet vil du seeksempler på, hvordan du bruger det OG håndterer dubletter på samme tid . Så du kan lave denne velkendte besked ud af din INSERT indsats:
Besked 2601, niveau 14, tilstand 1, linie 14Kan ikke indsætte dublet nøglerække i objektet 'dbo.Table1' med det unikke indeks 'UIX_Table1_Key1'. Dubletnøgleværdien er (værdi1). Men først ting først.

[sendpulse-form id="12989″]
Forbered testdata til SQL INSERT INTO SELECT Code Samples
Jeg tænker lidt på pasta denne gang. Så jeg vil bruge data om pastaretter. Jeg fandt en god liste over pastaretter i Wikipedia, som vi kan bruge og udtrække i Power BI ved hjælp af en webdatakilde. Jeg indtastede Wikipedia URL. Så specificerede jeg 2-tabel data fra siden. Ryddede lidt op i det og kopierede data til Excel.
Nu har vi dataene – du kan downloade dem her. Det er råt, fordi vi skal lave 2 relationelle tabeller ud af det. Brug af INSERT INTO SELECT hjælper os med at udføre denne opgave,
Importer dataene i SQL Server
Du kan enten bruge SQL Server Management Studio eller dbForge Studio til SQL Server til at importere 2 ark til Excel-filen.
Opret en tom database, før du importerer dataene. Jeg gav bordene navnet dbo.ItalianPastaDishes og dbo.NonItalianPastaDishes .
Opret 2 flere tabeller
Lad os definere de to outputtabeller med kommandoen SQL Server ALTER TABLE.
OPRET TABEL [dbo].[Origin]( [OriginID] [int] IDENTITY(1,1) NOT NULL, [Origin] [varchar](50) NOT NULL, [Modified] [datetime] NOT NULL, BEGRÆNSNING [PK_Origin] PRIMÆR NØGLE KLUSTERET ( [OriginID] ASC))GOALTER TABEL [dbo].[Oprindelse] TILFØJ BEGRÆNSNING [DF_Origin_Modified] STANDARD (getdate()) FOR [Modified]GOCREATE UNIQUE NOCLUSTERED INDEX [INDEX] ].[Oprindelse]( [Oprindelse] ASC)GOCREATE TABEL [dbo].[PastaDishes]( [PastaDishID] [int] IDENTITY(1,1) NOT NULL, [PastaDishName] [nvarchar](75) NOT NULL, [OriginID ] [int] NOT NULL, [Description] [nvarchar](500) NOT NULL, [Modified] [datetime] NOT NULL, CONSTRAINT [PK_PastaDishes_1] PRIMÆR NØGLE CLUSTERED ( [PastaDishID] ASC))GOALTER TABLE [dbo].[PastaDishes ] TILFØJ BEGRÆNSNING [DF_PastaDishes_Modified_1] STANDARD (getdate()) FOR [Modified]GOALTER TABLE [dbo].[PastaDishes] MED KONTROL TILFØJ BEGRÆNSNING [FK_PastaDishes_Origin] UDENLANDSKE NØGLE([OriginID])REFERENCER [Originbo].[OriginID] ])GOALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_Pa] staDishes_Origin]GOCREATE UNIKT IKKE-KLUSTERET INDEX [UIX_PastaDishes_PastaDishName] PÅ [dbo].[PastaDishes]( [PastaDishName] ASC)GO Bemærk:Der er oprettet unikke indekser på to tabeller. Det vil forhindre os i at indsætte duplikerede poster senere. Begrænsninger vil gøre denne rejse lidt sværere, men spændende.
Nu hvor vi er klar, lad os dykke ind.
5 nemme måder at håndtere dubletter ved hjælp af SQL INSERT INTO SELECT
Den nemmeste måde at håndtere dubletter på er at fjerne unikke begrænsninger, ikke?
Forkert!
Med unikke begrænsninger væk, er det nemt at lave en fejl og indsætte data to gange eller mere. Det ønsker vi ikke. Og hvad hvis vi har en brugergrænseflade med en dropdown-liste til at vælge pastarettens oprindelse? Vil dubletterne gøre dine brugere glade?
Derfor er fjernelse af de unikke begrænsninger ikke en af de fem måder at håndtere eller slette duplikerede poster i SQL. Vi har bedre muligheder.
1. Brug INSERT INTO SELECT DISTINCT
Den første mulighed for at identificere SQL-poster i SQL er at bruge DISTINCT i din SELECT. For at udforske sagen udfylder vi Oprindelsen bord. Men lad os først bruge den forkerte metode:
-- Dette er forkert og vil udløse duplikerede nøglefejlINSERT INTO Origin(Origin)SELECT origin FROM NonItalianPastaDishesGOINSERT INTO Origin(Origin)SELECT ItalianRegion + ', ' + 'Italien'FROM ItalianPastaDishesGO Dette vil udløse følgende duplikerede fejl:
Besked 2601, niveau 14, tilstand 1, linje 2. Kan ikke indsætte en dublet nøglerække i objektet 'dbo.Origin' med det unikke indeks 'UIX_Origin'. Dubletnøgleværdien er (USA). Udsagnet er blevet afsluttet. Besked 2601, niveau 14, tilstand 1, linje 6. Kan ikke indsætte dubletnøglerække i objektet 'dbo.Origin' med det unikke indeks 'UIX_Origin'. Dubletnøgleværdien er (Lombardia, Italien). Der er et problem, når du prøver at vælge dublerede rækker i SQL. For at starte SQL-kontrollen for dubletter, der eksisterede før, kørte jeg SELECT-delen af INSERT INTO SELECT-sætningen:
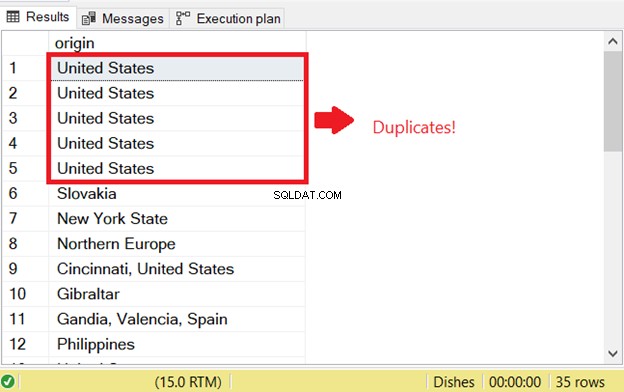
Det er årsagen til den første SQL-duplikatfejl. For at forhindre det skal du tilføje nøgleordet DISTINCT for at gøre resultatsættet unikt. Her er den korrekte kode:
-- Den korrekte måde at INSERTINSERT INTO Origin(Origin)SELECT DISTINCT origin FROM NonItalianPastaDishesINSERT INTO Origin(Origin)SELECT DISTINCT ItalianRegion + ', ' + 'Italien'FROM ItalianPastaDishes Det indsætter posterne med succes. Og vi er færdige med Oprindelsen tabel.
Brug af DISTINCT vil lave unikke poster ud af SELECT-sætningen. Det garanterer dog ikke, at der ikke findes dubletter i måltabellen. Det er godt, når du er sikker på, at måltabellen ikke har de værdier, du vil indsætte.
Så kør ikke disse udsagn mere end én gang.
2. Brug af WHERE NOT IN
Dernæst udfylder vi PastaDishes bord. Til det skal vi først indsætte poster fra ItalianPastaDishes bord. Her er koden:
INSERT INTO [dbo].[PastaDishes](PastaDishName,OriginID, Description)VÆLG a.DishName,b.OriginID,a.DescriptionFROM ItalianPastaDishes aINNER JOIN Origin b PÅ a.ItalianRegion + ', ' + 'Italien ' =b.OriginWHERE a.DishName NOT IN (VÆLG PastaDishName FRA PastaDishes) Siden ItalianPastaDishes indeholder rådata, skal vi tilslutte os Oprindelsen tekst i stedet for OriginID . Prøv nu at køre den samme kode to gange. Anden gang den kører, vil der ikke være indsat poster. Det sker på grund af WHERE-sætningen med NOT IN-operatoren. Den filtrerer poster fra, der allerede findes i måltabellen.
Dernæst skal vi udfylde PastaDishes tabel fra NonItalianPastaDishes bord. Da vi kun er ved det andet punkt i dette indlæg, vil vi ikke indsætte alt.
Vi valgte pastaretter fra USA og Filippinerne. Her kommer:
-- Indsæt pastaretter fra USA (22) og Filippinerne (15) ved brug af NOT ININSERT INTO dbo.PastaDishes(PastaDishName, OriginID, Description)SELECT a.PastaDishName,b.OriginID,a.DescriptionFROM NonItalianPastaDishes aINNER JOIN Oprindelse b PÅ a.Origin =b.OriginWHERE a.PastaDishName NOT IN (VÆLG PastaDishName FRA PastaDishes) OG b.OriginID IN (15,22) Der er indsat 9 poster fra denne erklæring – se figur 2 nedenfor:
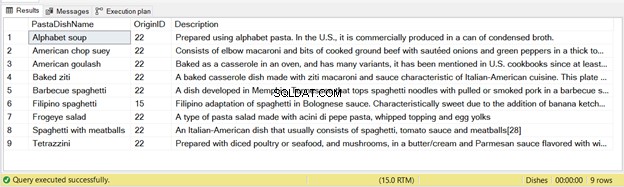
Igen, hvis du kører koden ovenfor to gange, vil den anden kørsel ikke have poster indsat.
3. Brug af WHERE NOT EXISTS
En anden måde at finde dubletter i SQL er at bruge NOT EXISTS i WHERE-sætningen. Lad os prøve det med de samme betingelser fra forrige afsnit:
-- Indsæt pastaretter fra USA (22) og Filippinerne (15) ved hjælp af WHERE NOT EXISTSINSERT INTO dbo.PastaDishes(PastaDishName, OriginID, Description)SELECT a.PastaDishName,b.OriginID,a. BeskrivelseFRA NonItalianPastaDishes aINNER JOIN Oprindelse b PÅ a.Origin =b.OriginWHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd WHERE pd.OriginID IN (15,22)) AND b.OriginID IN (15,22) Koden ovenfor vil indsætte de samme 9 poster, som du så i figur 2. Den vil undgå at indsætte de samme poster mere end én gang.
4. Bruger HVIS IKKE FINDER
Nogle gange kan det være nødvendigt at implementere en tabel til databasen, og det er nødvendigt at kontrollere, om en tabel med samme navn allerede findes for at undgå dubletter. I dette tilfælde kan kommandoen SQL DROP TABLE IF EXISTS være til stor hjælp. En anden måde at sikre, at du ikke vil indsætte dubletter på, er at bruge HVIS IKKE FINDER. Igen vil vi bruge de samme betingelser fra forrige afsnit:
-- Indsæt pastaretter fra USA (22) og Filippinerne (15) ved at bruge IF NOT EXISTSIF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd WHERE pd.OriginID IN (15,22))BEGIN INSERT INTO dbo.PastaDishes (PastaDishName, OriginID, Description) VÆLG a.PastaDishName ,b.OriginID ,a.Description FROM NonItalianPastaDishes a INNER JOIN Origin b ON a.Origin =b.Origin WHERE b.OriginID IN (15,22)END
kode>
Ovenstående kode vil først kontrollere, om der findes 9 poster. Hvis det returnerer sandt, fortsætter INSERT.
5. Bruger COUNT(*) =0
Endelig kan brugen af COUNT(*) i WHERE-sætningen også sikre, at du ikke indsætter dubletter. Her er et eksempel:
INSERT INTO dbo.PastaDishes(PastaDishName, OriginID, Description)SELECT a.PastaDishName,b.OriginID,a.DescriptionFROM NonItalianPastaDishes aINNER JOIN Origin b ON a.Origin =b.OriginWHERE b.OriginID IN (15, 22) OG (VÆLG ANTAL(*) FRA PastaDishes pd WHERE pd.OriginID IN (15,22)) =0
For at undgå dubletter skal COUNT eller poster returneret af underforespørgslen ovenfor være nul.
Bemærk :Du kan designe enhver forespørgsel visuelt i et diagram ved hjælp af Query Builder-funktionen i dbForge Studio til SQL Server.
Sammenligning af forskellige måder at håndtere dubletter på med SQL INSERT INTO SELECT
4 sektioner brugte det samme output, men forskellige tilgange til at indsætte bulk-poster med en SELECT-sætning. Du kan undre dig over, om forskellen kun er på overfladen. Vi kan tjekke deres logiske læsninger fra STATISTICS IO for at se, hvor forskellige de er.
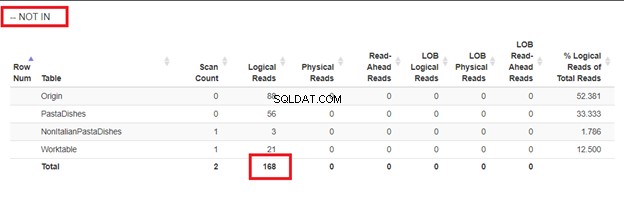
Brug af WHERE NOT IN:
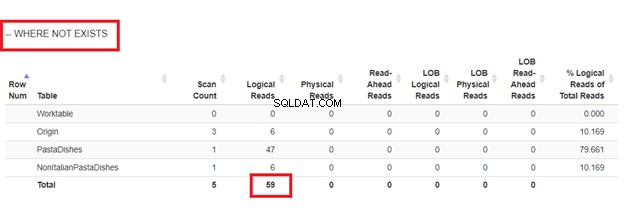
Bruger NOT EXISTS:
Brug af IF NOT EXISTS:
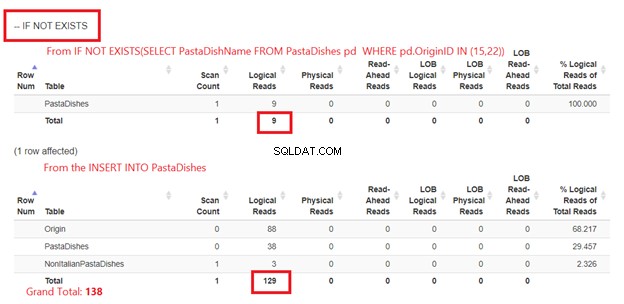
Figur 5 er lidt anderledes. 2 logiske læsninger vises for Pastaretter bord. Den første er fra IF NOT EXISTS(SELECT PastaDishName fra PastaDishes HVOR OriginID IN (15,22)). Den anden er fra INSERT-sætningen.
Brug endelig COUNT(*) =0
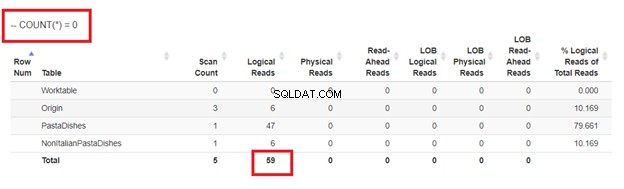
Ud fra de logiske aflæsninger af 4 tilgange, vi havde, er det bedste valg, WHERE NOT EXISTS eller COUNT(*) =0. Når vi inspicerer deres eksekveringsplaner, ser vi, at de har den samme QueryHashPlan . Derfor har de lignende planer. I mellemtiden bruger den mindst effektive NOT IN.
Betyder det, at WHERE NOT EXISTS altid er bedre end NOT IN? Slet ikke.
Undersøg altid de logiske læsninger og udførelsesplanen for dine forespørgsler!
Men før vi konkluderer, skal vi afslutte opgaven. Så indsætter vi resten af registreringerne og inspicerer resultaterne.
-- Indsæt resten af posterneINSERT INTO dbo.PastaDishes(PastaDishName, OriginID, Description)SELECT a.PastaDishName,b.OriginID,a.DescriptionFROM NonItalianPastaDishes aINNER JOIN Origin b ON a.OriginWHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)GO-- Se outputVÆLG a.PastaDishID,a.PastaDishName,b.Origin,a.Description,a.ModifiedFROM PastaDishes aINNER JOIN Origin b PÅ a.OriginID =b.BYOriginIDORDER b.Oprindelse, a.PastaDishName
At gennemse listen over 179 pastaretter fra Asien til Europa gør mig sulten. Se en del af listen fra Italien, Rusland og mere nedenfor:

Konklusion
At undgå dubletter i SQL INSERT INTO SELECT er trods alt ikke så svært. Du har operatører og funktioner ved hånden for at tage dig til det niveau. Det er også en god vane at tjekke udførelsesplanen og logiske læsninger for at sammenligne, hvad der er bedst.
Hvis du tror, at en anden vil drage fordel af dette opslag, så del det venligst på dine foretrukne sociale medieplatforme. Og hvis du har noget at tilføje, som vi har glemt, så fortæl os det i kommentarfeltet nedenfor.