Et databasestyringssystem er informationens stærke boks. Vi vil forsøge at designe databasestyringssystemet, så databasen skal forblive veladministreret og levere formålene.
I denne artikel vil vi diskutere design og administration af store databasesystemer. Vi vil bruge flere forfatninger, der vil omfatte databaseteknologier, lagring, datadistribution, serveraktiver, arkitekturmønster og nogle andre.
Helst skal vi kigge efter en stor database inden for Telco-domænet, e-handelsplatforme, forsikringsdomæne, banksystem, sundhedsvæsen, energisystem osv. Vi skal have nogle få parametre for øje, før vi vælger den rigtige databaseteknologi. dvs. trafik, TPS (Transactions Per Second), estimeret lagerplads pr. dag, HA og DR.
Design af en stor database
Når vi opbygger vores database, skal vi være opmærksomme på flere parametre, fordi det ofte er meget problematisk at ændre databasen med en erstatning. Lad os overveje dem nu.
Databaseteknologi
Databaseteknologi er den primære faktor. Hvis du vælger det rigtige databasestyringssystem, hjælper det din virksomhed med at køre effektivt og ubesværet.
Der er forskellige databaseteknologier med mange funktioner. Men mens du arbejder med open source-databaseteknologier, får du muligvis ikke adgang til nogle eksplicitte funktioner i foruddefinerede løsninger. Virksomhedsdatabaseteknologier som Microsoft SQL Server, Oracle osv. ville give dem.
Masser af virksomhedsdatabaseteknologier implementerer HA (High Availability), DR (Disaster Recovery), Mirroring, Datareplikering, Secondary Read Replica og betydeligt mere bekvemme og klar konfigurerbare forretningsløsninger. De kan være til stede i open source-databaser eller ikke.
Der er mange mange grunde. For eksempel oplever vi nogle gange, at den eksisterende arkitektur bliver forstyrret, fordi de ovennævnte faktorer ikke er funktionelle, da vi har brug for dem.
Opbevaring
Lageret påvirker ydeevnen af forretningsløsningen drastisk. Forretningsløsninger kræver førsteklasses storage eller SSD med en vis mængde IOPS. Men er det sådan? On-premises eller Cloud, Storagestørrelsen og -typen bestemmer infrastrukturomkostningerne.
Mens vi overvejer lagringsydelsen, skal vi være opmærksomme på typen af data og opførsel af databehandlingen. Vi er nødt til at vælge lagervalg i henhold til brugerens data og behandling af dem. Hvis brugeren skal bruge flere databaser, skal vi give lagervalget frem for SAN for forskellige databaser for datatyperne og databehandlingsadfærden.
Databaseingeniøren vil give et bedre tilbageblik på de forskellige databaser, der er nødvendige for IOPS-beregning, hvis brugerne slet ikke har brug for premium storage.
Datadistribution
De fleste af de seneste databaseteknologier (SQL eller NoSQL) tilbyder partitionerings- eller Sharding-funktioner.
- Partitionen omdistribuerer data i filsystemet, som er baseret på partitionsnøglen.
- Sharding distribuerer information på tværs af databasenoderne, og dataene vil blive gemt på den samme eller en anden maskine.
Grundlæggende vil hver databasetjeneste eller databasetabel ikke kræve datapartitionerings-/shardingfunktionerne. De skal kun anvendes på databaser med større objekter. Det vil forbedre ydeevnen.
Serveraktiver
Forskellige maskiner kræver forskellige typer og størrelser af hukommelse og CPU. Du skal overveje aktiver på hardwareniveau, såsom hukommelse, processor osv. For eksempel vil en maskine, der skal håndtere større databaser eller flere databaser, have brug for mere hukommelse og CPU'er. Derfor er kvaliteten af hukommelse og processor betydelig. Det kommer til at håndtere forskellige typer processorer, der er tilgængelige på markedet med forskellige CPU-caches.
Mange gange støder vi på problemer, som vi måske ikke er opmærksomme på. Vi var ikke opmærksomme på udnyttelsen og rollen af hardwarens CPU-cache. Men det er afgørende for at vælge og opfylde hardwarekravene med større databasesystemer.
Arkitekturmønster
I databasedesign spiller arkitekturmønsteret altid en eksemplarisk rolle. Tidligere blev databasesystemer designet på en ekstremt monolitisk måde. Nu bruger vi Micro-Service baseret eller Hybrid (Monolitisk + Micro).
Ydeevnen, udvidelsesmulighederne og nul nedetid afhænger meget af arkitekturmønsteret og databasedesignet. Hver applikation kunne have en separat database, og alle databaser kunne være løst koblet med hinanden. I tilfælde af at en applikation eller database går ned, vil en anden del af produktet ikke blive forstyrret. Alle mikrotjenester ville være uafhængige og løst koblede.
Mikrotjeneste
Diagrammet nedenfor forklarer, hvordan alle applikationer implementeres og kommunikerer ved hjælp af deres databaser, som er løst koblede på samme tid. Vi kan manipulere dataene med T-SQL. Oplysningerne vil blive indsamlet eller akkumuleret af forskellige applikationer, og klienten vil være i stand til at få adgang til dataene. Se diagrammet med antallet af skalerede applikationer og dens integrerede database.
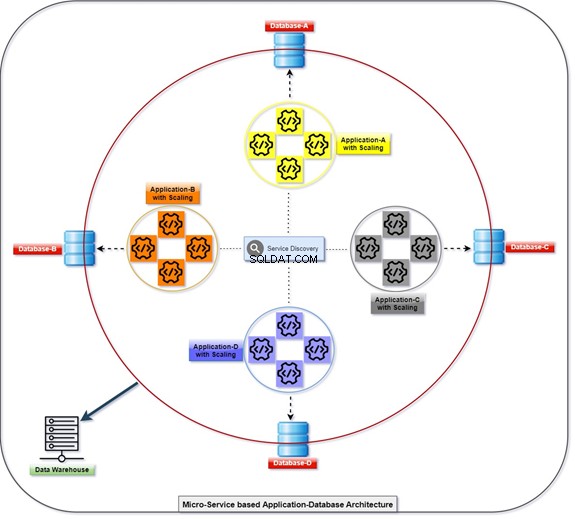
Monolitisk
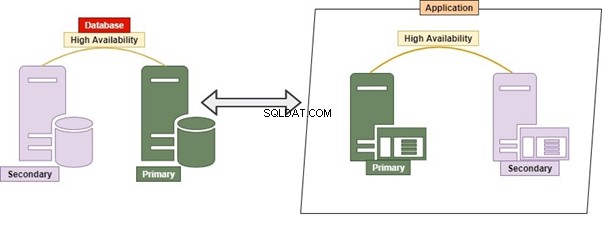
Hvilken RDBMS skal vi bruge? Det kunne være Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB eller enhver anden database. Den konventionelle måde at håndtere alle tabeller eller objekter på i en enkelt eller flere databaser på en enkelt server er kendt som Monolithic.
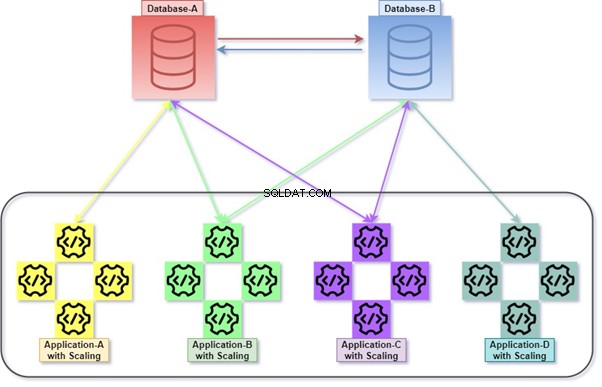
Hybrid
Hybrid er en permutation af Monolithic og Micro Service. Det er ret almindelig praksis, da det tillader mange applikationer, talrige databaser og databaseservere. Talrige databaser og databaseservere kunne være tæt forbundet med hinanden.
For eksempel forespørgsel med JOINs mellem tabeller, der tilhører to eller flere databaser i samme databaseserver eller forskellige. Fjernforespørgsel brugt til datahentning/-manipulation med en anden databaseserver.
Alt handler om SQL Server-arkitektur. Vi taler dog om datamanipulation mellem forskellige tabeller i den samme database eller forskellige databaser, der kunne ligge på den samme server eller forskellige servere.
Enten i hybrid eller monolitisk arkitektur bruger vi JOINs mellem forskellige tabeller i den samme eller forskellige databaser. Det er ret komplekst, når vi følger de centrale Micro-Service-standarder, fordi tabellernes fordeling kan være mellem databasetjenesterne (Dbas).
Under Enterprise-databaseteknologierne som Microsoft SQL Server, Oracle osv., kunne brugeren forespørge i den distribuerede databases tabeller ved hjælp af Linked Server Joins. Men det er ikke tilgængeligt i alle open source-databaseteknologier. Det er kendt som Tight-Coupled-tilgangen, der muligvis ikke virker, når fjerndatabasetjenesten ikke er tilgængelig.
Lad os nu diskutere at gøre det løst koblet. Hvorfor har vi brug for datamanipulation mellem eksterne databaser?
Hvorfor kræver vi datamanipulation mellem fjerndatabaser?
Brugere vil kræve, at dataene hentes fra mere end én databasetjeneste, når systemet er designet ved hjælp af Micro eller Hybrid Services. Hele processen ses fra backend, som kan håndtere datamængder manipuleret af applikationen.
Når vi ser på forespørgsler på tværs af databaser i realtid, forbinder vi altid masterentitetstabellerne, ikke metadatatabellerne. Mastertabellerne vil ikke være større end metadatatabeller. Til rapporteringsformål bruger vi altid datavarehuset til at samle alle oplysninger. Men det er ikke let at administrere og vedligeholde for hvert produkt. Hvis vi designer virksomhedsløsningen, har vi råd til lageret. Men vi har ikke råd til små eller mellemstore produkter.
For eksempel har vi brug for en rapport med data fra flere tabeller i forskellige databaser. Det er ikke en nem opgave at udføre, da den samler dataene ved hjælp af forskellige mikrotjenester og fusionerer dem for at producere rapporten. Derfor skal de nødvendige data synkroniseres.
Hvad kan vi bruge som standardløsning at lave løst koblede tabeldatasynkronisering mellem to databaser?
Tabelreplikering bør bruges til simpel datasynkronisering mellem flere databaser. Eksemplet er transaktionsreplikeringen til Simplex-datasynkroniseringen og Merge-replikeringen til Duplex-datasynkroniseringen leveret af SQL Server.
Der er et par betalte tredjeparts- og open source-løsninger, der kan synkronisere data mellem flere databaser. Selv løst koblede løsninger ved hjælp af beskedkøer som SQL Server Transaction Replication kan udvikles af brugere på egen hånd.
Konklusion
DBA'er designer databaser på deres måde. Mens de opbygger databasen og vælger databasestyringssystemet, skal de have mange aspekter i tankerne. Vi præsenterede de mest væsentlige faktorer for databasedesignet, især for de større databaser. Hold øje med de næste materialer!