Det er vigtigt at vide, hvilken af kolonnerne du vil gruppere efter, og hvordan du vil gruppere dem. Du skal vide det for at konfigurere CASE STATEMENT vi kommer til at skrive som en klumme i vores udvalgte erklæring. I vores tilfælde, i en gruppe af e-mails, der har adgang til vores websted, ønsker vi at vide, hvor mange klik hver e-mail-udbyder står for siden begyndelsen af august. Vi vil også gerne sammenligne en individuel e-mail-tjenesteudbyder med resten. I dette eksempel kommer vi til at bruge Gmail som vores tjenesteudbyder.
I vores SELECT erklæring, skal vi bruge DATE , PROVIDER og SUM af KLIK til vores side. Vi kan få disse fra TEST E-MAILS tabel i vores datakilde.
DATE kolonne er ret ligetil:
"Test E Mails"."Created_Date" AS "DATE
Og da vi leder efter SUM af KLIK , bliver vi nødt til at caste en SUM funktion over CLICKS kolonne.
SUM("Test E Mails"."Clicks") AS "CLICKS"
Det bringer os til vores CASE STATEMENT . Vi ved fra PostgreSQL-dokumentationen, at en CASE STATEMENT eller en betinget erklæring skal arrangeres på følgende måde:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Vores første og i dette tilfælde eneste betingelse er, at vi ønsker at vide, at alle de e-mail-adresser, der leveres af Gmail, skal være adskilt fra alle andre e-mail-udbydere. Så den eneste HVORNÅR er:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
Og den anden erklæring ville være 'Andet' for hver anden e-mail-adresseudbyder. Den resulterende tabel i denne CASE STATEMENT alene med tilhørende e-mails. Ville se sådan ud:
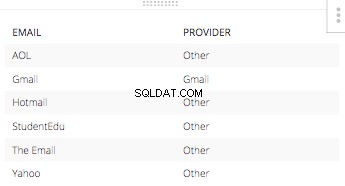
Når du samler alle tre af disse kolonner til én SELECT STATEMENT og smid resten af de nødvendige stykker ind for at bygge en SQL-forespørgsel, det hele tager form nedenfor.
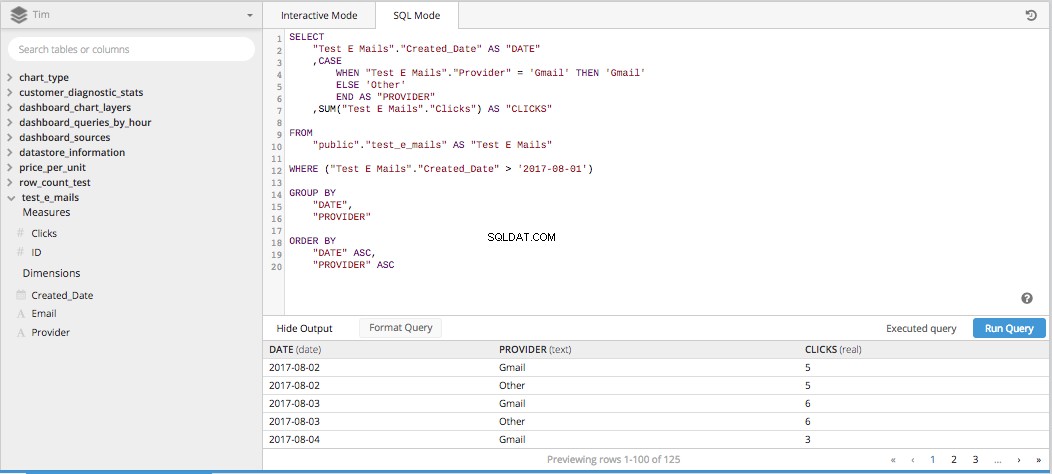
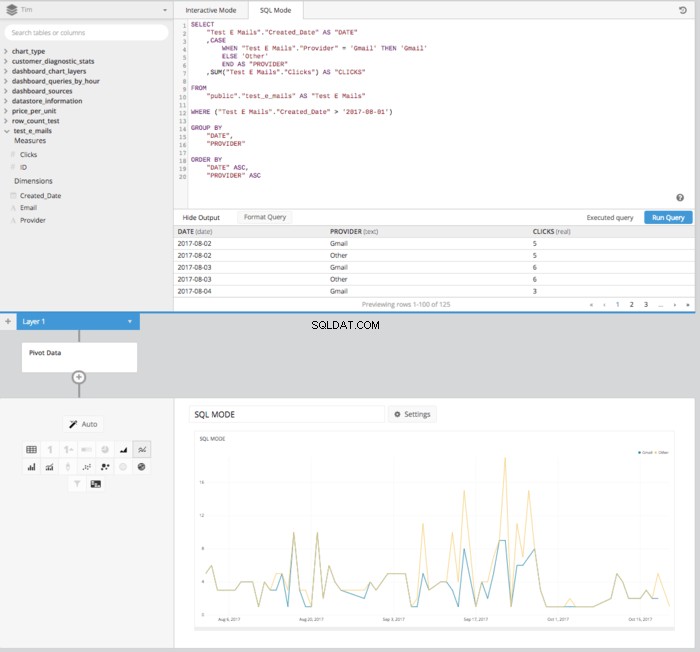
Derefter efter tilføjelse af en PIVOT DATA træder ind i datapipelinen, får vi en tabel korrekt arrangeret i det rigtige format for at opsætte et linjediagram, der viser, hvordan klik sammenlignes over tid.
Ved at bruge Chartio kan vi gøre alt det ovenstående uden at skrive SQL, men udnytte Data Explorer og Data Pipeline-funktionerne. Efter at have bygget vores underliggende forespørgsel til at trække alle kolonnerne ind, får vi brug for SUM AF KLIK , DATE og EMAILADRESSE vi kan bruge Data Pipeline til at manipulere disse data efter SQL. Lad os først bygge forespørgslen.
Træk 'Klik-kolonnen' til måleboksen og aggregér den med TOTAL SUM af kolonneklikkene, og ommærk den derefter som 'KLIK'.
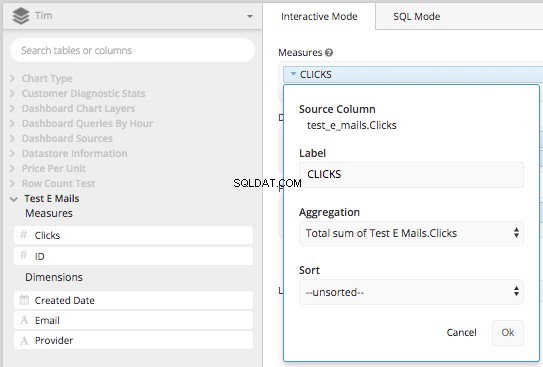
Træk derefter 'Oprettelsesdato' og 'Udbyder' til dimensionsboksen, og mærk dem igen med 'Dato' og 'E-mail-udbyder'. Derefter kan du ved hjælp af kolonnen 'Oprettet dato' indstille datospændet (eller bygge din CASE STATEMENT vi gjorde ovenfor, i Chartios Data Pipeline.
Tilføjelse af en CASE STATEMENT pipeline-trin giver os mulighed for at indstille betingelserne for HVORNÅR og ELSE ligesom vi gjorde før, uden at skulle indtaste hele SQL-syntaksen.
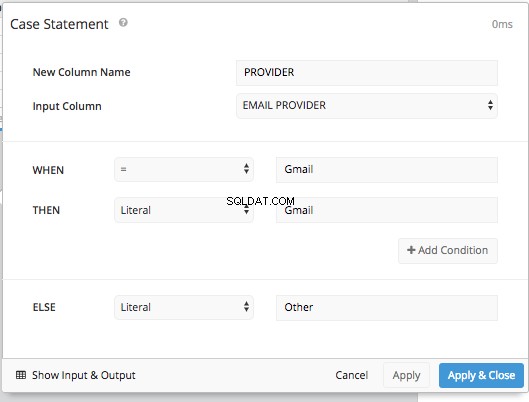
Derefter efter at have skjult den originale 'Udbyder'-kolonne og brugt en GENBEORDNELSE KOLUMNER trin og en PIVOT DATA trin, vi får det samme bordarrangement, som vi fik i SQL-tilstand og kan præsentere den samme tabel, som vi gjorde i SQL-tilstand.
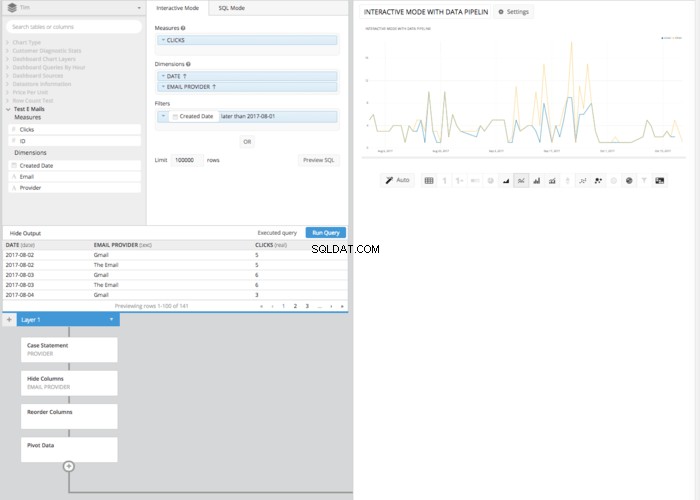
Selvom det kan tage et par flere klik og trin end i SQL-tilstand, kræver det resulterende linjediagram udført i interaktiv tilstand ingen viden om SQL-syntaks. I stedet kræver det blot en grundlæggende forståelse af de involverede principper. Dette er endnu et eksempel på, hvordan Chartio hjælper med at lægge kraften i data i alles hænder, uanset SQL-viden.