Dit spørgsmål er virkelig upræcis. Følg venligst @RiggsFolly forslag og læs referencerne om, hvordan du stiller et godt spørgsmål.
Også, som foreslået af @DuduMarkovitz, bør du starte med at forenkle problemet og rense dine data. Et par ressourcer til at komme i gang:
- Grundlæggende tekstbehandlingsvejledning af Matt Deny
- Håndtering og behandling af strenge i R af Gaston Sanchez
Når du er tilfreds med resultaterne, kan du fortsætte med at identificere en gruppe for hver Var1 indtastning (dette vil hjælpe dig på vej til at udføre yderligere analyser/manipulationer på lignende poster) Dette kan gøres på mange forskellige måder, men som nævnt af @GordonLinoff, er en mulighed Levenshtein-distancen.
Bemærk :for 50.000 poster vil resultatet ikke være 100 % nøjagtigt, da det ikke altid kategoriser vilkårene i den relevante gruppe, men dette burde reducere den manuelle indsats betydeligt.
I R kan du gøre dette ved at bruge adist()
Brug af dine eksempeldata:
d <- adist(df$Var1)# tilføj rækkenavne (dette vil vise sig nyttigt senere)rækkenavne(d) <- df$Var1> d# [,1] [,2] [,3] [ ,4] [,5] [,6] [,7] [,8] [,9] [,10]#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14#125 Hollywood St 1 2 0 15 15 15 14 14 15 15#Target Store 16 15 15 0 2 1 2 10 10 9#Trget Stre 15 291 0. Butik 16 15 15 1 3 0 3 11 11 10#T argetStore 15 15 14 2 4 3 0 10 11 9#Walmart 15 14 14 10 9 11 10 0 5 2#Walmart Inc. 1 0 1 0 1 0 1 0 #Wal marte 15 14 15 9 8 10 9 2 6 0 For denne lille prøve kan du se de 3 forskellige grupper (klynger med lave Levensthein-afstandsværdier) og kunne nemt tildele dem manuelt, men for større sæt har du sandsynligvis brug for en klyngealgoritme.
Jeg har allerede henvist dig i kommentarerne til en af mine tidligere svar
viser, hvordan man gør dette ved hjælp af hclust() og afdelingens minimum varians metode, men jeg tror, at du her ville være bedre stillet ved at bruge andre teknikker (en af mine foretrukne ressourcer om emnet for et hurtigt overblik over nogle af de mest udbredte metoder i R er denne detaljeret svar
)
Her er et eksempel, der bruger affinitetsudbredelsesklynger:
bibliotek(apcluster)d_ap <- apcluster(negDistMat(r =1), d)
Du finder i APResult-objektet d_ap elementerne forbundet med hver klynger og det optimale antal klynger, i dette tilfælde:3.
> eksempel@sqldat.com
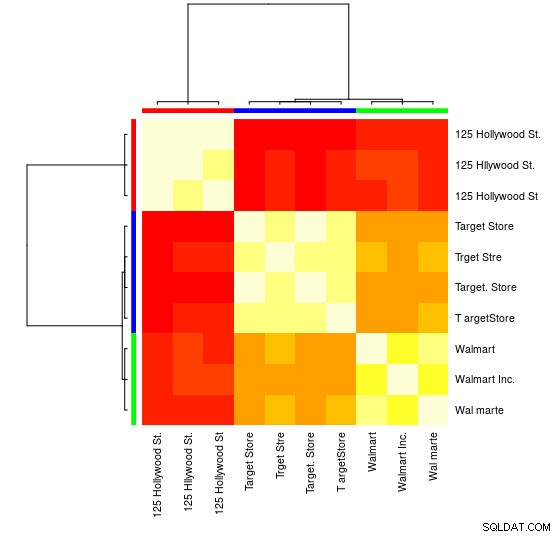
#[[1]]#125 Hollywood St. 125 Hllywood St. 125 Hollywood St. # 1 2 3 ##[[2]]# Target Store Trget Stre Target. Butik T argetButik # 4 5 6 7 ##[[3]]# Walmart Walmart Inc. Wal marte # 8 9 10 Du kan også se en visuel repræsentation:
> heatmap(d_ap, margins =c(10, 10))
Derefter kan du udføre yderligere manipulationer for hver gruppe. Som et eksempel bruger jeg her hunspell at slå hvert separate ord op fra Var1 i en en_US ordbog for stavefejl og prøv at finde inden for hver gruppe , hvilket id har ingen stavefejl (potential_id )
library(dplyr)library(tidyr)library(hunspell)tibble(Var1 =sapply(eksempel@sqldat.com
, navne)) %>% unnest(.id ="gruppe") %>% group_by(group) %>% mutate(id =row_number()) %>% separate_rows(Var1) %>% mutate(check =hunspell_check( Var1)) %>% group_by(id, add =TRUE) %>% summarise(checked_vars =toString(Var1), result_per_word =toString(check), potential_id =all(check)) Hvilket giver:
#Kilde:lokal dataramme [10 x 5]#Grupper:gruppe [?]## gruppe-id checked_vars result_per_word potential_id# #1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE#4 2 1 Mål, Gem TRUE, TRUE TRUE#5 2 2 Trget, Stre FALSE, FALSE FALSE#6 2 3 Target., Store TRUE, TRUE TRUE#7 2 4 T, argetStore TRUE, FALSE FALSE#8 3 1 Walmart FALSE FALSE#9 3 2 Walmart, Inc. FALSK, TRUE FALSE#10 3 3 Wal, marte FALSE, FALSE FALSE Bemærk :Her, da vi ikke har udført nogen tekstbehandling, er resultaterne ikke særlig afgørende, men du forstår ideen.
Data
df <- tibble::tribble( ~Var1, "125 Hollywood St.", "125 Hllywood St.", "125 Hollywood St", "Target Store", "Trget Stre", "Target. Butik", "T argetStore", "Walmart", "Walmart Inc.", "Wal marte" )