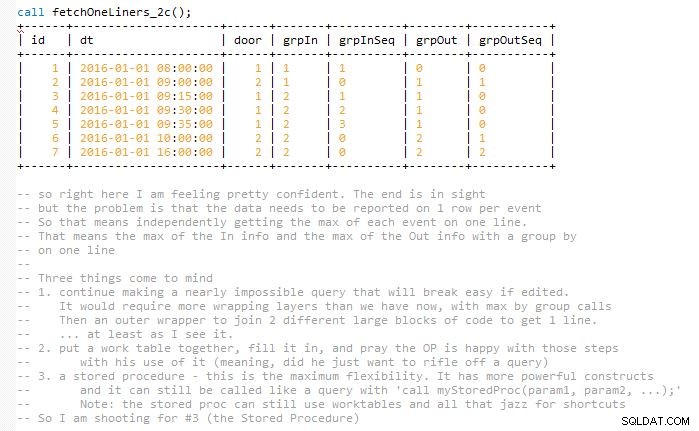
Dette stræber efter at holde løsningen let at vedligeholde uden at afslutte den endelige forespørgsel i ét skud, hvilket næsten ville have fordoblet størrelsen (efter min mening). Dette skyldes, at resultaterne skal matches og repræsenteres på én række med matchede In- og Out-begivenheder. Så til sidst bruger jeg et par arbejdsborde. Det er implementeret i en lagret procedure.
Den lagrede procedure bruger flere variabler, der bringes ind med en cross join . Tænk på krydsforbindelsen som blot en mekanisme til at initialisere variabler. Variablerne vedligeholdes sikkert, så jeg tror, i ånden af denne dokument
ofte refereret i variable forespørgsler. De vigtige dele af referencen er sikker håndtering af variabler på en linje, der tvinger dem til at blive indstillet før andre kolonner bruger dem. Dette opnås gennem greatest() og least() funktioner, der har højere forrang end variabler, der indstilles uden brug af disse funktioner. Bemærk også, at coalesce() bruges ofte til samme formål. Hvis deres brug virker mærkelig, såsom at tage det største af et tal, der vides at være større end 0 eller 0, er det bevidst. Bevidst at fremtvinge prioritetsrækkefølgen af variabler, der sættes.
Kolonnerne i forespørgslen navngav ting som dummy2 osv. er kolonner, som output ikke blev brugt til, men de blev brugt til at sætte variabler inde i f.eks. greatest() eller en anden. Dette blev nævnt ovenfor. Output som 7777 var en pladsholder i den 3. plads, da en vis værdi var nødvendig for if() der blev brugt. Så ignorer alt det.
Jeg har inkluderet flere skærmbilleder af koden, efterhånden som den udviklede sig lag for lag for at hjælpe dig med at visualisere outputtet. Og hvordan disse gentagelser af udvikling langsomt foldes ind i den næste fase for at udvide det foregående.
Jeg er sikker på, at mine jævnaldrende kunne forbedre dette i én forespørgsel. Jeg kunne have afsluttet det på den måde. Men jeg tror, det ville have resulteret i et forvirrende rod, der ville gå i stykker, hvis man rørte ved det.
Skema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Lagret procedure:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Dette er slutningen på svaret. Nedenstående er til en udviklers visualisering af de trin, der førte til færdiggørelsen af den lagrede procedure.
Versioner af udvikling, der førte op til slutningen. Forhåbentlig hjælper dette med visualiseringen i modsætning til blot at droppe en mellemstørrelse forvirrende stykke kode.
Trin A
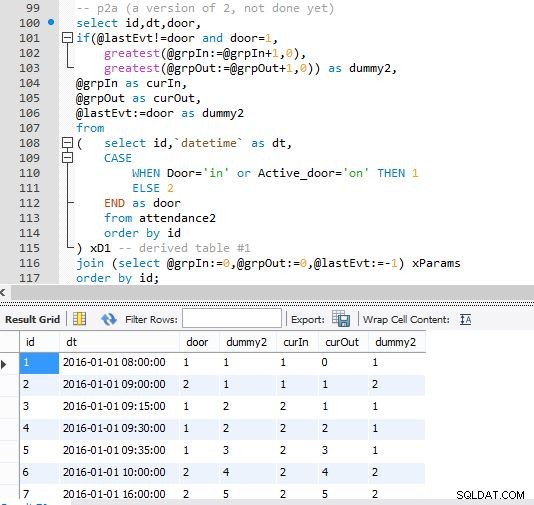
Trin B
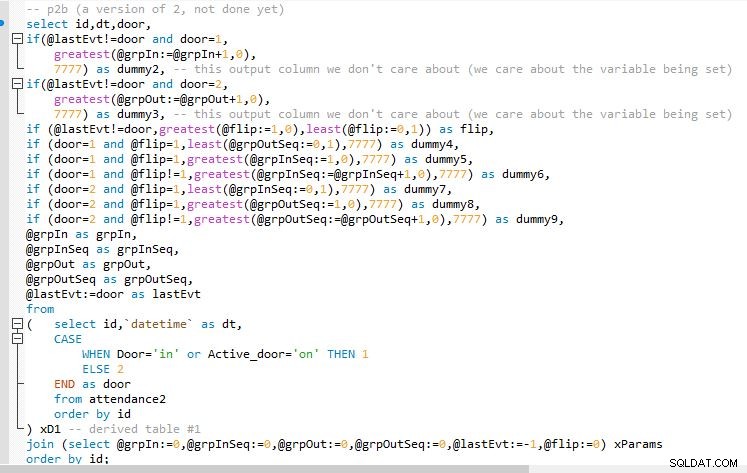
Trin B output

Trin C
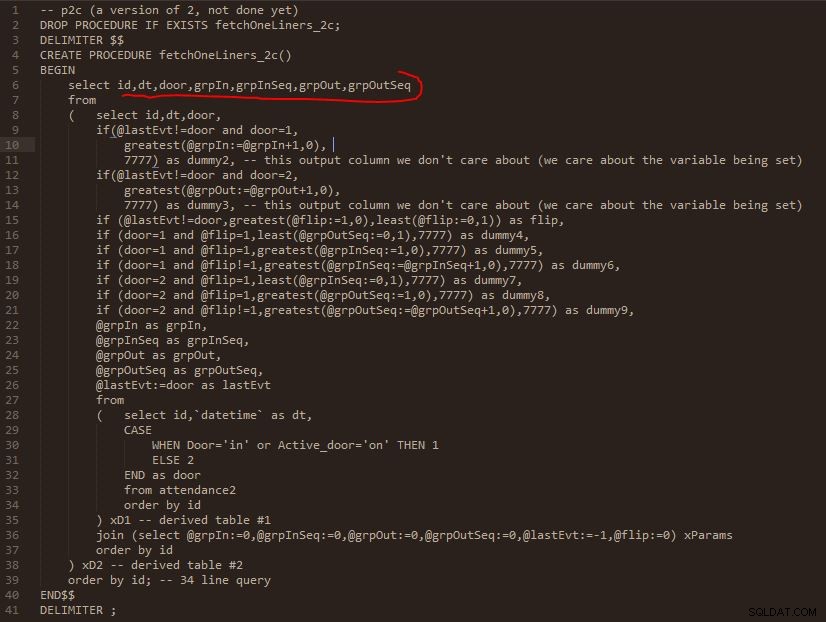
Trin C output