Når jeg arbejdede med personnavne og lavede uklare opslag på dem, var det, der virkede for mig, at oprette en anden tabel med ord. Opret også en tredje tabel, der er en skærende tabel for mange til mange-forholdet mellem tabellen, der indeholder teksten, og ordtabellen. Når en række føjes til teksttabellen, opdeler du teksten i ord og udfylder skæringstabellen korrekt, og tilføjer nye ord til ordtabellen, når det er nødvendigt. Når først denne struktur er på plads, kan du lave opslag lidt hurtigere, fordi du kun skal udføre din damlev-funktion over tabellen med unikke ord. En simpel join giver dig teksten, der indeholder de matchende ord. 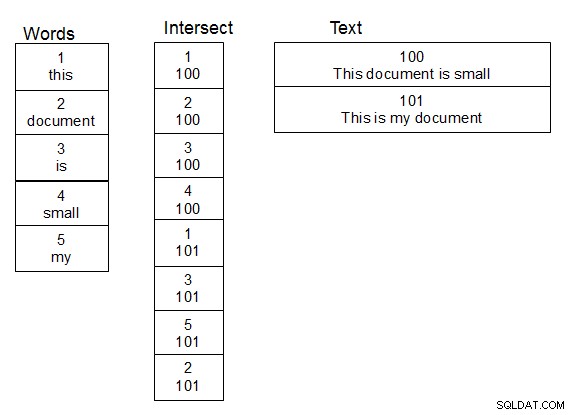
En forespørgsel efter et enkelt ordmatch ville se sådan ud:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
og to ord ville se sådan ud (fra toppen af mit hoved, så det er måske ikke helt korrekt):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Fordelene her, på bekostning af noget databaseplads, er, at du kun skal anvende den tidskrævende damlev-funktion på de unikke ord, som sandsynligvis kun vil tælle i 10'erne af tusinder uanset størrelsen på din teksttabel. Dette betyder noget, fordi damlev UDF'en ikke vil bruge indekser - den vil scanne hele tabellen, som den er anvendt på, for at beregne en værdi for hver række. Scanning af kun de unikke ord burde være meget hurtigere. Den anden fordel er, at damlev anvendes på ordniveau, hvilket ser ud til at være det, du beder om. En anden fordel er, at du kan udvide forespørgslen til at understøtte søgning på flere ord, og du kan rangere resultaterne ved at gruppere de matchende krydsende rækker på TextId og rangere på antallet af matches.