Alle I har hørt om skalering - din arkitektur skal være skalerbar, du skal være i stand til at skalere op for at imødekomme efterspørgslen, så videre og så videre. Hvad betyder det, når vi taler om databaser? Hvordan ser skaleringen ud bag kulisserne? Dette emne er stort, og der er ingen måde at dække alle aspekterne på. Denne serie med to blogindlæg er et forsøg på at give dig et indblik i emnet databaseskalerbarhed.
Hvorfor skalerer vi?
Lad os først se på, hvad skalerbarhed handler om. Kort sagt, vi taler om evnen til at håndtere højere belastning af dine databasesystemer. Det kan være et spørgsmål om at håndtere kortvarige spidser i aktiviteten, det kan være et spørgsmål om at håndtere en gradvist øget arbejdsbyrde i dit databasemiljø. Der kan være mange grunde til at overveje skalering. De fleste af dem kommer med deres egne udfordringer. Vi kan bruge lidt tid på at gennemgå eksempler på situationen, hvor vi måske ønsker at skalere ud.
Forøgelse af ressourceforbrug
Dette er den mest generiske - din belastning er steget til det punkt, hvor dine eksisterende ressourcer ikke længere er i stand til at håndtere det. Det kan være hvad som helst. CPU-belastningen er steget, og din databaseklynge er ikke længere i stand til at levere data med en rimelig og stabil forespørgselsudførelsestid. Hukommelsesudnyttelsen er vokset i en sådan grad, at databasen ikke længere er CPU-bundet, men blev I/O-bundet, og som sådan er ydeevnen af databasenoderne blevet væsentligt reduceret. Netværk kan også være en bootle-neck. Du kan blive overrasket over at se, hvilke grænser relateret til netværk har dine cloud-instanser tildelt. Faktisk kan dette blive den mest almindelige grænse, du skal forholde dig til, da netværket er alt i skyen - ikke kun de data, der sendes mellem applikationen og databasen, men også lagring er knyttet over netværket. Det kan også være diskbrug - du er lige ved at løbe tør for diskplads, eller mere sandsynligt, da vi kan have ret store diske i dag, voksede databasestørrelsen ud af den "håndterbare" størrelse. Vedligeholdelse som skemaændring bliver en udfordring, ydeevne reduceres på grund af datastørrelse, sikkerhedskopiering tager evigheder at fuldføre. Alle disse sager kan være en gyldig sag for et behov for opskalering.
Pludselig stigning i arbejdsbyrden
Et andet eksempel, hvor skalering er påkrævet, er en pludselig stigning i arbejdsbyrden. Af en eller anden grund (det være sig marketingindsats, indhold, der går viralt, nødsituationer eller lignende) oplever din infrastruktur en betydelig stigning i belastningen på databaseklyngen. CPU-belastning går over taget, disk I/O bremser forespørgslerne osv. Stort set alle ressourcer, som vi nævnte i det foregående afsnit, kan blive overbelastet og begynde at forårsage problemer.
Planlagt operation
Den tredje grund, vi gerne vil fremhæve, er den mere generiske - en slags planlagt operation. Det kan være en planlagt markedsføringsaktivitet, som du forventer vil give mere trafik, Black Friday, belastningstest eller stort set alt, hvad du ved i forvejen.
Hver af disse grunde har sine egne karakteristika. Hvis du kan planlægge på forhånd, kan du forberede processen i detaljer, teste den og udføre den, når du har lyst. Du vil højst sandsynligt kunne lide at gøre det i en periode med "lav trafik", så længe sådan noget findes i dine arbejdsbelastninger (det behøver ikke at eksistere). På den anden side vil pludselige stigninger i belastningen, især hvis de er betydelige nok til at påvirke produktionen, fremtvinge øjeblikkelig reaktion, uanset hvor forberedt du er, og hvor sikker den er - hvis dine tjenester allerede er påvirket, kan du lige så godt bare gå efter det i stedet for at vente.
Typer af databaseskalering
Der er to hovedtyper af skalering:lodret og vandret. Begge har fordele og ulemper, begge er nyttige i forskellige situationer. Lad os tage et kig på dem og diskutere use cases for begge scenarier.
Lodret skalering
Denne skaleringsmetode er sandsynligvis den ældste:Hvis din hardware ikke er kraftig nok til at klare arbejdsbyrden, så forstærk den. Vi taler her blot om at tilføje ressourcer til eksisterende noder med en hensigt at gøre dem i stand til at håndtere de givne opgaver. Dette har nogle konsekvenser, som vi gerne vil gennemgå.
Fordele ved lodret skalering
Det vigtigste er, at alt forbliver det samme. Du havde tre noder i en databaseklynge, du har stadig tre noder, bare mere dygtige. Der er ingen grund til at redesigne dit miljø, ændre, hvordan applikationen skal få adgang til databasen - alt forbliver nøjagtigt det samme, fordi konfigurationsmæssigt har intet virkelig ændret sig.
En anden væsentlig fordel ved vertikal skalering er, at det kan være meget hurtigt, især i skymiljøer. Hele processen er stort set at stoppe den eksisterende node, foretage ændringen i hardwaren, starte noden igen. For klassiske, lokale opsætninger, uden nogen virtualisering, kan dette være vanskeligt - du har muligvis ikke hurtigere CPU'er til rådighed til at bytte, opgradering af diske til større eller hurtigere kan også være tidskrævende, men for skymiljøer, det være sig offentlige eller private, dette kan være lige så nemt som at køre tre kommandoer:stop instans, opgrader instans til større størrelse, start instans. Virtuelle IP'er og gentilslutbare volumener gør det nemt at flytte data rundt mellem forekomster.
Ulempe ved lodret skalering
Den største ulempe ved vertikal skalering er, at den simpelthen har sine begrænsninger. Hvis du kører på den største tilgængelige forekomststørrelse, med de hurtigste diskvolumener, er der ikke meget andet, du kan gøre. Det er heller ikke så nemt at øge ydeevnen af din databaseklynge markant. Det afhænger for det meste af den oprindelige instansstørrelse, men hvis du allerede kører ganske effektive noder, kan du muligvis ikke opnå 10x skalering ved hjælp af vertikal skalering. Noder, der ville være 10 gange hurtigere, eksisterer muligvis simpelthen ikke.
Horisontal skalering
Horisontal skalering er et andet udyr. I stedet for at gå op med instansstørrelsen, forbliver vi på samme niveau, men vi udvider horisontalt ved at tilføje flere noder. Igen, der er fordele og ulemper ved denne metode.
Fordele ved vandret skalering
Den største fordel ved horisontal skalering er, at himlen teoretisk set er grænsen. Der er ingen kunstig hård grænse for udskalering, selvom der findes grænser, primært på grund af, at intra-klyngekommunikation bliver større og større overhead med hver ny node, der føjes til klyngen.
En anden væsentlig fordel ville være, at du kan opskalere klyngen uden behov for nedetid. Hvis du vil opgradere hardware, skal du stoppe instansen, opgradere den og derefter starte igen. Hvis du vil tilføje flere noder til klyngen, er alt, hvad du skal gøre, at klargøre disse noder, installere den software, du har brug for, inklusive databasen, og lade den slutte sig til klyngen. Eventuelt (afhængigt af om klyngen har interne metoder til at levere nye noder med dataene) kan du være nødt til at klargøre den med data på egen hånd. Typisk er det dog en automatiseret proces.
Idele ved vandret skalering
Det største problem, du skal håndtere, er, at tilføjelse af flere og flere noder gør det svært at administrere hele miljøet. Du skal kunne se, hvilke noder der er tilgængelige, en sådan liste skal vedligeholdes og opdateres med hver ny node oprettet. Du har muligvis brug for eksterne løsninger som directory service (Consul eller Etcd) for at holde styr på noderne og deres tilstand. Dette øger naturligvis kompleksiteten af hele miljøet.
Et andet potentielt problem er, at udskaleringsprocessen tager tid. Tilføjelse af nye noder og klargøring af dem med software og især data kræver tid. Hvor meget, det afhænger af hardwaren (hovedsageligt I/O og netværksgennemstrømning) og størrelsen af dataene. For store opsætninger kan dette være en betydelig mængde tid, og dette kan være en blokering for situationer, hvor opskaleringen skal ske med det samme. Ventetimer for at tilføje nye noder er muligvis ikke acceptabelt, hvis databaseklyngen er påvirket i det omfang, at operationer ikke udføres korrekt.
Forudsætninger for skalering
Datareplikering
Før der kan gøres forsøg på skalering, skal dit miljø opfylde et par krav. For det første skal din applikation kunne drage fordel af mere end én node. Hvis det kun kan bruge én node, er dine muligheder stort set begrænset til lodret skalering. Du kan øge størrelsen af en sådan node eller tilføje nogle hardwareressourcer til bare metal-serveren og gøre den mere effektiv, men det er det bedste, du kan gøre:du vil altid være begrænset af tilgængeligheden af mere ydende hardware, og i sidste ende vil du finde dig selv uden mulighed for at opskalere yderligere.
På den anden side, hvis du har midlerne til at bruge flere databasenoder af din applikation, kan du drage fordel af horisontal skalering. Lad os stoppe her og diskutere, hvad det er, du skal bruge for rent faktisk at bruge flere noder til deres fulde potentiale.
Til at begynde med, muligheden for at opdele læser fra skrivninger. Traditionelt forbinder applikationen kun én node. Denne node bruges til at håndtere alle skrivninger og alle læsninger, der udføres af applikationen.

At tilføje en anden node til klyngen, set fra skaleringssynspunktet, ændrer intet . Du skal huske på, at hvis den ene knude svigter, skal den anden håndtere trafikken, så på intet tidspunkt bør summen af belastningen på tværs af begge knudepunkter være for høj til, at en enkelt knude kan håndteres.

Med tre tilgængelige noder kan du fuldt ud udnytte to noder. Dette giver os mulighed for at udskalere noget af læsetrafikken:Hvis én node har 100 % kapacitet (og vi helst vil køre højst på 70 %), repræsenterer to noder 200 %. Tre noder:300 %. Hvis én knude er nede, og hvis vi presser resterende knudepunkter næsten til grænsen, kan vi sige, at vi er i stand til at arbejde med 170 - 180 % af en enkelt knudekapacitet, hvis klyngen er forringet. Det giver os en pæn belastning på 60 % på hver node, hvis alle tre noder er tilgængelige.
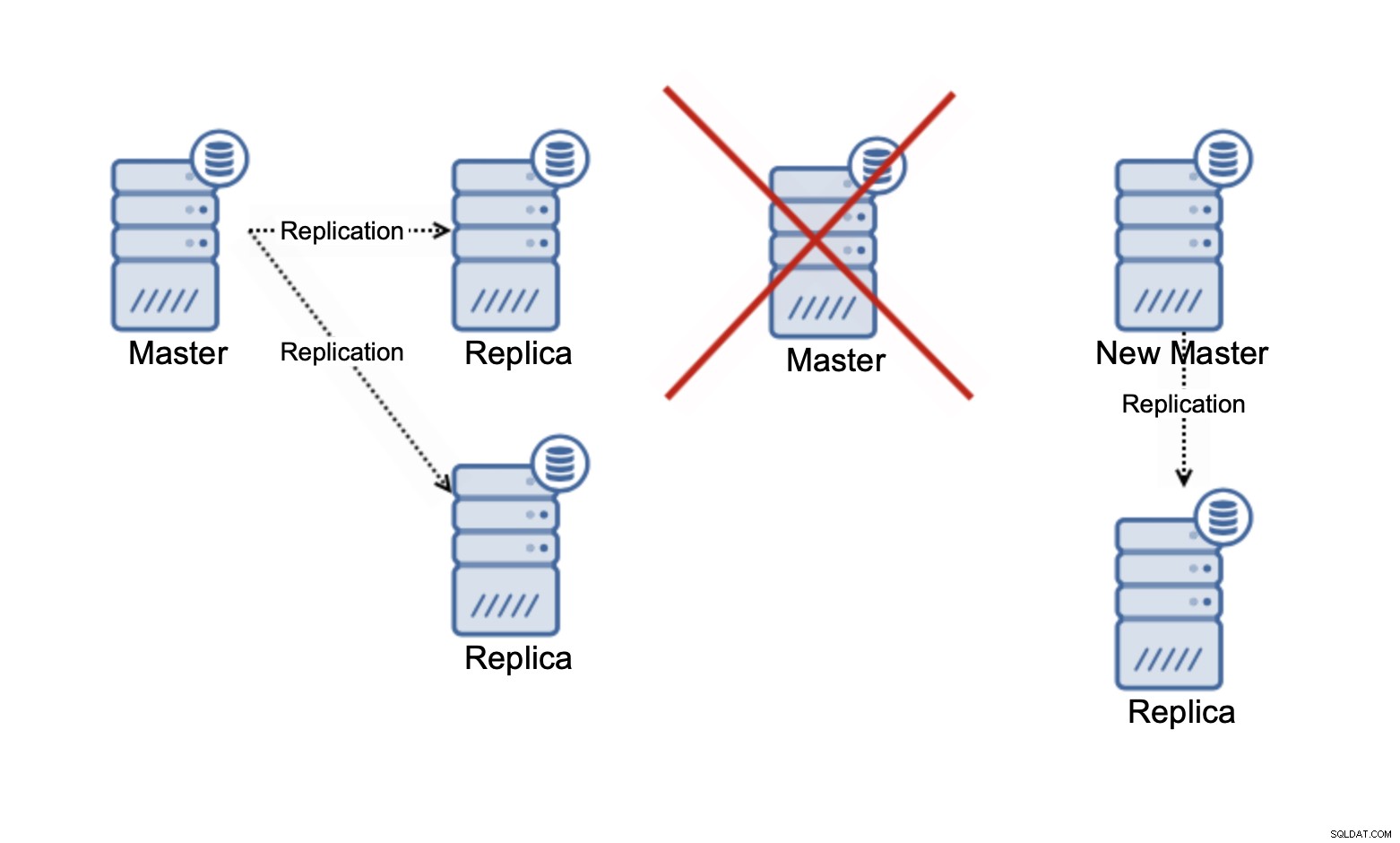
Husk, at vi kun taler om skalering af læsninger i øjeblikket . Replikering kan på intet tidspunkt forbedre din skrivekapacitet. I asynkron replikering har du kun én writer (master), og for den synkrone replikering, som Galera, hvor datasættet deles på tværs af alle noder, skal hver skrivning, der sker på én node, udføres på de resterende noder i klynge.
I en Galera-klynge med tre noder, hvis du skriver en række, skriver du faktisk tre rækker, en for hver node. Tilføjelse af flere noder eller replikaer vil ikke gøre en forskel. I stedet for at skrive den samme række på tre noder, skriver du den på fem. Dette er grunden til at opdele dine skrivninger i en multi-master-klynge, hvor datasættet deles på tværs af alle noder (der er multi-master-klynger, hvor data er sønderdelt, f.eks. MySQL NDB Cluster - her er skriveskalerbarhedshistorien helt anderledes), giver ikke for meget mening. Det tilføjer overhead til håndtering af potentielle skrivekonflikter på tværs af alle noder, mens det ikke rigtig ændrer noget med hensyn til den samlede skrivekapacitet.
Belastningsbalancering og læse/skriveopdeling
Evnen til at opdele læsninger fra skrivninger er et must, hvis du ønsker at skalere dine læsninger i asynkrone replikeringsopsætninger. Du skal være i stand til at sende skrivetrafik til én node og derefter sende læsningerne til alle noder i replikeringstopologien. Som vi nævnte tidligere, er denne funktionalitet også ret nyttig i multi-master-klyngerne, da den giver os mulighed for at fjerne skrivekonflikter, der kan opstå, hvis du forsøger at distribuere skrivningerne på tværs af flere noder i klyngen. Hvordan kan vi udføre læse/skrive opdelingen? Der er flere metoder, du kan bruge til at gøre det. Lad os grave lidt i dette emne.
Applikationsniveau R/W opdelt
Det mest enkle scenarie, også det mindst hyppige:din applikation kan konfigureres, hvilke noder der skal modtage skrivninger, og hvilke noder der skal modtage læsninger. Denne funktionalitet kan konfigureres på et par måder, den mest enkle er den hårdkodede liste over noderne, men det kunne også være noget i retning af dynamisk nodebeholdning opdateret af baggrundstråde. Hovedproblemet med denne tilgang er, at hele logikken skal skrives som en del af applikationen. Med en hårdkodet liste over noder ville det enkleste scenarie kræve ændringer af applikationskoden for hver ændring i replikeringstopologien. På den anden side ville mere avancerede løsninger som implementering af en serviceopdagelse være mere komplekse at vedligeholde i det lange løb.
R/W opdelt i stik
En anden mulighed ville være at bruge et stik til at udføre en læse/skrive-split. Ikke alle af dem har denne mulighed, men nogle har. Et eksempel ville være php-mysqlnd eller Connector/J. Hvordan det er integreret i applikationen, det kan variere baseret på selve stikket. I nogle tilfælde skal konfigurationen udføres i applikationen, i nogle tilfælde skal det udføres i en separat konfigurationsfil for stikket. Fordelen ved denne tilgang er, at selvom du skal udvide din applikation, er det meste af den nye kode klar til brug og vedligeholdes af eksterne kilder. Det gør det nemmere at håndtere en sådan opsætning, og du skal skrive mindre kode (hvis nogen).
R/W opdelt i loadbalancer
Endelig en af de bedste løsninger:loadbalancers. Ideen er enkel - send dine data gennem en loadbalancer, der vil være i stand til at skelne mellem læsning og skrivning og sende dem til et korrekt sted. Dette er en stor forbedring fra et brugervenligt synspunkt, da vi kan adskille databaseopdagelse og forespørgselsrouting fra applikationen. Det eneste, applikationen skal gøre, er at sende databasetrafikken til et enkelt slutpunkt, der består af et værtsnavn og en port. Resten sker i baggrunden. Loadbalancers arbejder på at dirigere forespørgslerne til en backend-databasenoder. Loadbalancers kan også lave replikeringstopologiopdagelse, eller du kan implementere en ordentlig serviceopgørelse ved hjælp af etcd eller konsul og opdatere den gennem dine infrastrukturorkestreringsværktøjer som Ansible.
Dette afslutter den første del af denne blog. I den anden vil vi diskutere de udfordringer, vi står over for, når vi skalere databaseniveauet. Vi vil også diskutere nogle måder, hvorpå vi kan skalere vores databaseklynger ud.