- Kort om pivottabeller
- Pivotering af data ved hjælp af værktøjer (dbForge Studio til MySQL)
- Pivotering af data ved hjælp af SQL
- T-SQL-baseret eksempel for SQL Server
- Eksempel på MySQL
- Automatisk datapivotering, oprettelse af forespørgsler dynamisk
Kort om pivottabeller
Denne artikel omhandler transformation af tabeldata fra rækker til kolonner. En sådan transformation kaldes pivottabeller. Ofte er resultatet af pivoten en oversigtstabel, hvori statistiske data præsenteres i den form, der er passende eller påkrævet til en rapport.
Desuden kan en sådan datatransformation være nyttig, hvis en database ikke er normaliseret, og informationen er lagret deri i en ikke-optimal form. Så når du omorganiserer databasen og overfører data til nye tabeller eller genererer en påkrævet datarepræsentation, kan datapivot være nyttigt, dvs. at flytte værdier fra rækker til resulterende kolonner.
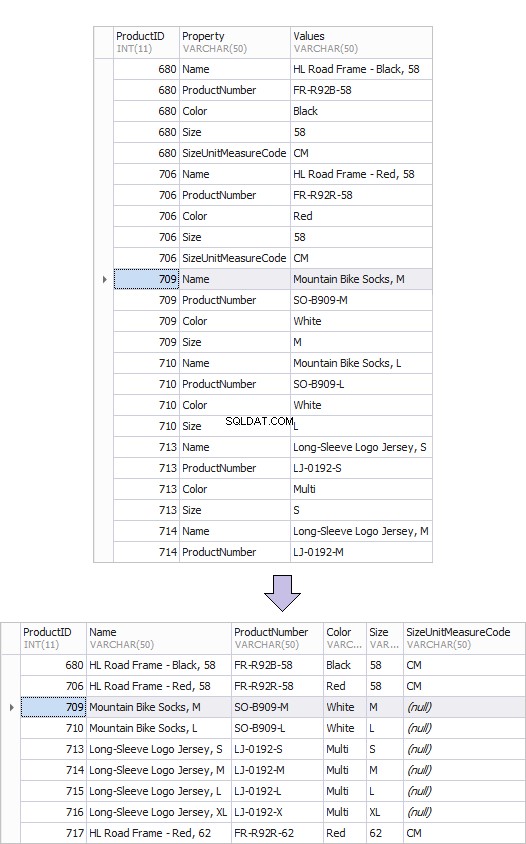
Nedenfor er et eksempel på den gamle tabel over produkter – gamle produkter og den nye – produkter nye. Det er gennem transformationen fra rækker til kolonner, at et sådant resultat nemt kan opnås.
Her er et eksempel på en pivottabel.
Pivotering af data ved hjælp af værktøjer (dbForge Studio til MySQL)
Der er applikationer, der har værktøjer, der gør det muligt at implementere datapivot i et praktisk grafisk miljø. For eksempel inkluderer dbForge Studio til MySQL pivottabeller-funktionalitet, der giver det ønskede resultat i blot nogle få trin.

Lad os se på eksemplet med en forenklet tabel over ordrer – PurchaseOrderHeader .
CREATE TABLE PurchaseOrderHeader ( PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID));INSERT PurchaseOrderHeaderID(PurchaseOrderHeaderID,PurchaseOrderID,PurchaseOrderID,PurchaseOrder) , 258, 1580);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES,INSERT(3, 24chaOrderIDployee; ) VALUES (4, 261, 1650);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654);INSERT PurchaseOrderHeader(PurchaseOrderID, Employee PurchaseID, VendorID,INSERTHeader) 64Pordcha,INSERT; , EmployeeID, VendorID) VALUES (7, 255, 1678);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616);INSERT PurchaseOrderHeader(PurchaseOrderID, (9,2)Værdi-ID, (9,2,5)); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540);...
Antag, at vi skal foretage et udvalg fra tabellen og bestemme antallet af ordrer foretaget af visse medarbejdere fra specifikke leverandører. Listen over medarbejdere, for hvilke oplysninger er nødvendige – 250, 251, 252, 253, 254.
En foretrukken visning af rapporten er som følger.
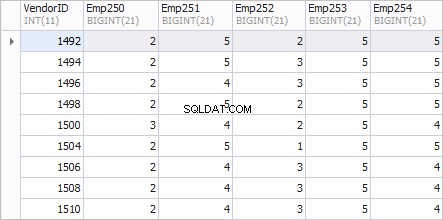
Den venstre kolonne VendorID viser leverandørernes ID'er; kolonner Emp250 , Emp251 , Emp252 , Emp253 og Emp254 vise antallet af ordrer.
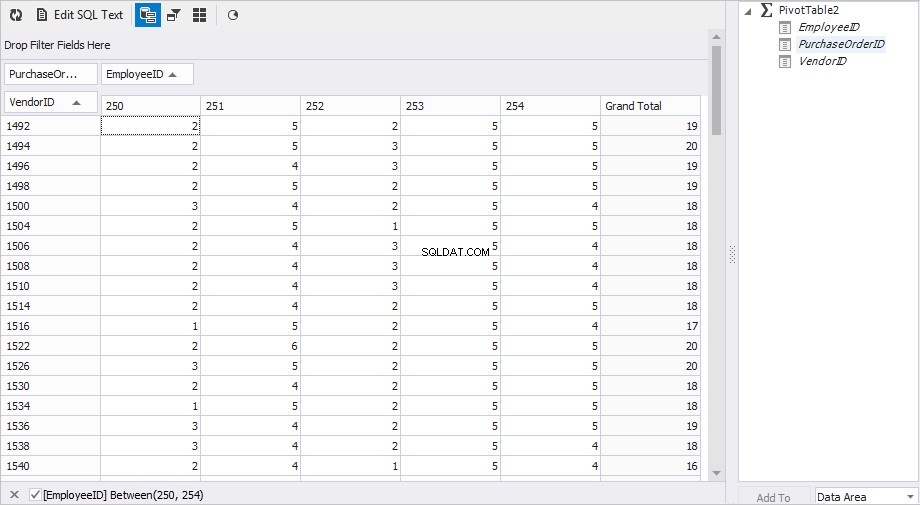
For at opnå dette i dbForge Studio til MySQL skal du:
- Tilføj tabellen som en datakilde for "Pivot Table"-repræsentationen af dokumentet. Højreklik på PurchaseOrderHeader i Database Explorer tabel og vælg Send til og derefter Pivottabel i pop op-menuen.
- Angiv en kolonne, hvis værdier skal være rækker. Træk VendorID kolonnen til boksen 'Drop Rows Fields Here'.
- Angiv en kolonne, hvis værdier skal være kolonner. Træk medarbejder-id'et kolonne til boksen 'Slip kolonnefelter her'. Du kan også indstille et filter for de nødvendige medarbejdere (250, 251, 252, 253, 254).
- Angiv en kolonne, hvis værdier vil være dataene. Træk PurchaseOrderID kolonnen til boksen 'Slip dataelementer her'.
- I egenskaberne for PurchaseOrderID kolonne, angiv typen af aggregering – Antal værdier .
Vi fik hurtigt det resultat, vi skulle bruge.
Pivotering af data ved hjælp af SQL
Datatransformation kan naturligvis udføres ved hjælp af en database ved at skrive en SQL-forespørgsel. Men der er et lille problem, MySQL har ikke en specifik erklæring, der tillader dette.
T-SQL-baseret eksempel for SQL Server
For eksempel har SqlServer og Oracle PIVOT-operatøren, der gør det muligt at foretage en sådan datatransformation. Hvis vi arbejdede med SqlServer, ville vores forespørgsel se sådan ud.
SELECT VendorID ,[250] AS Emp1 ,[251] AS Emp2 ,[252] AS Emp3 ,[253] AS Emp4 ,[254] AS Emp5FROM (SELECT PurchaseOrderID ,EmployeeID ,VendorID FROM Purchasing.PurchaseOrderPIVOTer) COUNT. (PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])) SOM ORDRE AF t.VendorID;
Eksempel på MySQL
I MySQL bliver vi nødt til at bruge SQL-midlerne. Dataene skal grupperes efter leverandørkolonnen – VendorID , og for hver påkrævet medarbejder (EmployeeID ), skal du oprette en separat kolonne med en samlet funktion.
I vores tilfælde skal vi beregne antallet af ordrer, så vi bruger den samlede funktion COUNT.
I kildetabellen er oplysningerne om alle medarbejdere gemt i én kolonne Medarbejder-ID , og vi skal beregne antallet af ordrer for en bestemt medarbejder, så vi skal lære vores aggregerede funktion kun at behandle bestemte rækker.
Den aggregerede funktion tager ikke højde for NULL-værdier, og vi bruger denne ejendommelighed til vores formål.
Du kan bruge den betingede operator IF eller CASE, som vil returnere en specifik værdi for den ønskede medarbejder, ellers vil blot returnere NULL; som et resultat, vil COUNT-funktionen kun tælle værdier, der ikke er NULL.
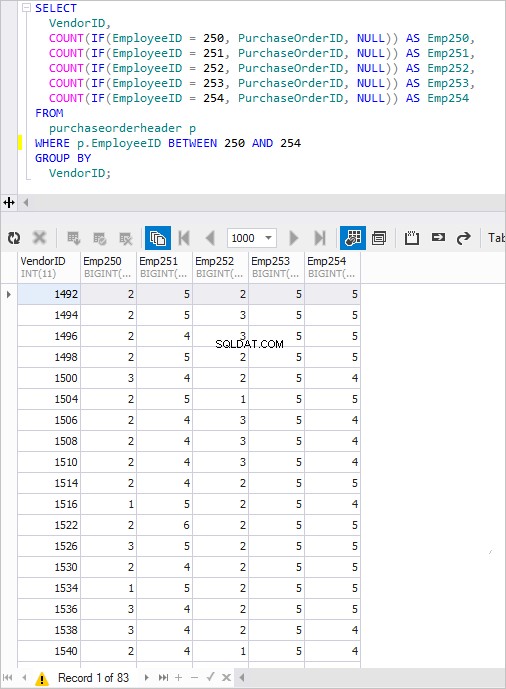
Den resulterende forespørgsel er som følger:
SELECT VendorID, COUNT(IF(EmployeeID =250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID =251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID =252, NULL)ID, NULL ) AS Emp252, COUNT(IF(EmployeeID =253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID =254, PurchaseOrderID, NULL)) AS Emp254FROM PurchaseOrderHeader pWHEREID BY225PRE.>Eller endda sådan her:
LeverandørID, COUNT(IF(Medarbejder-ID =250, 1, NULL)) AS Emp250, COUNT(IF(Medarbejder-ID =251, 1, NULL)) AS Emp251, COUNT(IF(Medarbejder-ID =252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID =253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID =254, 1, NULL)) AS Emp254FROM PurchaseOrderHeader pWHERE p.EmployeeID MELLEM 2540;Når det udføres, opnås et velkendt resultat.
Automatisk datapivot, oprettelse af forespørgsler dynamisk
Som det kan ses, har forespørgslen en vis konsistens, det vil sige, at alle de transformerede kolonner er dannet på samme måde, og for at skrive forespørgslen skal du kende de specifikke værdier fra tabellen. For at danne en pivotforespørgsel skal du gennemgå alle mulige værdier, og først derefter skal du skrive forespørgslen. Alternativt kan du videregive denne opgave til en server, der får den til at opnå disse værdier og dynamisk udføre rutineopgaven.
Lad os vende tilbage til det første eksempel, hvor vi dannede den nye tabel ProductsNew fra ProductsOld bord. Der er værdierne af ejendomme begrænset, og vi kan ikke engang kende alle mulige værdier; vi har kun oplysningerne om, hvor ejendommenes navne og deres værdi er opbevaret. Disse er Ejendommen og Værdi henholdsvis kolonner.
Hele algoritmen for at oprette SQL-forespørgslen kommer ned til at opnå de værdier, hvorfra nye kolonner og sammenkædninger af uforanderlige dele af forespørgslen vil blive dannet.
SELECT GROUP_CONCAT( CONCAT( ' MAX(IF(Property =''', t.Property, ''', Value, NULL)) AS ', t.Property ) ) INTO @PivotQueryFROM (SELECT Property FROM ProductOld GROUP BY Egenskab) t;SET @PivotQuery =CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');Variabel @PivotQuery gemmer vores forespørgsel, teksten er blevet formateret for klarhedens skyld.
SELECT ProductID, MAX(IF(Property ='Farve', Værdi, NULL)) AS Color, MAX(IF(Property ='Navn', Værdi, NULL)) AS Name, MAX(IF(Property ='ProductNumber) ', Værdi, NULL)) AS ProductNumber, MAX(IF(Property ='Size', Value, NULL)) AS Size, MAX(IF(Property ='SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCodeFROM ProductOldGROUP BY ProductIDEfter at have udført det, vil vi opnå det ønskede resultat svarende til skemaet i ProductsNew-tabellen.
Hvad mere er, kan forespørgslen fra variablen @PivotQuery udføres i scriptet ved hjælp af MySQL-sætningen EXECUTE.PREPARE-sætning FRA @PivotQuery;EXECUTE-sætning;DEALLOCATE PREPARE-sætning;