I dette blogindlæg vil vi se på nogle nøglemålinger og status, når vi overvåger en Percona Server til MySQL for at hjælpe os med at finjustere MySQL-serverkonfigurationen i lang tid. Bare for at være opmærksom på, har Percona Server nogle overvågningsmetrikker, der kun er tilgængelige på denne build. Ved sammenligning på version 8.0.20 er følgende 51 statusser kun tilgængelige på Percona Server til MySQL, som ikke er tilgængelige i opstrøms Oracles MySQL Community Server:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Tjek siden Udvidet InnoDB-status for at få flere oplysninger om hver af overvågningsmetrikkene ovenfor. Bemærk, at nogle ekstra statusser som trådpulje kun er tilgængelig i Oracles MySQL Enterprise. Tjek Percona Server til MySQL 8.0-dokumentationen for at se alle forbedringerne specifikt til denne build i forhold til Oracles MySQL Community Server 8.0.
For at hente MySQL globale status skal du blot bruge en af følgende sætninger:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Databasetilstand og oversigt
Vi starter med oppetidsstatus, det antal sekunder, serveren har været oppe.
Alle com_*-status er sætningstællervariablerne, der angiver antallet af gange, hver sætning er blevet udført. Der er én statusvariabel for hver type erklæring. For eksempel tæller com_delete og com_update henholdsvis DELETE- og UPDATE-sætninger. com_delete_multi og com_update_multi ligner hinanden, men gælder for DELETE- og UPDATE-sætninger, der bruger multiple-table-syntaks.
For at få vist alle de kørende processer af MySQL, skal du blot køre en af følgende sætninger:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Forbindelser og tråde
Nuværende forbindelser
Forholdet mellem aktuelt åbne forbindelser (forbindelsesgevind). Hvis forholdet er højt, indikerer det, at der er mange samtidige forbindelser til MySQL-serveren og kan føre til en "For mange forbindelser"-fejl. Sådan får du forbindelsesprocenten:
Current connections(%) = (threads_connected / max_connections) x 100En god værdi bør være 80 % og derunder. Prøv at øge max_connections-variablen eller inspicer forbindelserne ved at bruge VIS FULD PROCESSLISTE. Når "For mange forbindelser"-fejl opstår, bliver MySQL-databaseserveren utilgængelig for ikke-superbrugeren, indtil nogle forbindelser er frigivet. Bemærk, at en forøgelse af max_connections-variablen også potentielt kan øge MySQL's hukommelsesfodaftryk.
Maksimalt antal forbindelser nogensinde set
Forholdet mellem maksimale forbindelser til MySQL-serveren, der nogensinde blev set. En simpel beregning ville være:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Den gode værdi bør være under 80 %. Hvis forholdet er højt, indikerer det, at MySQL engang har nået et højt antal forbindelser, der ville føre til 'for mange forbindelser'-fejl. Undersøg det nuværende forbindelsesforhold for at se, om det faktisk forbliver lavt konsekvent. Ellers skal du øge variablen max_connections. Kontroller max_used_connections_time-statussen for at angive, hvornår max_used_connections-statussen nåede sin aktuelle værdi.
Threads Cache Hit Rate
Status for threads_created er antallet af tråde, der er oprettet for at håndtere forbindelser. Hvis threads_created er stor, vil du måske øge værdien for thread_cache_size. Cache hit/miss rate kan beregnes som:
Threads cache hit rate (%) = (threads_created / connections) x 100Det er en brøkdel, der giver en indikation af trådens cache-hitrate. Jo nærmere mindre end 50 %, jo bedre. Hvis din server ser hundredvis af forbindelser i sekundet, bør du normalt indstille thread_cache_size højt nok, så de fleste nye forbindelser bruger cachelagrede tråde.
Forespørgselsydeevne
Fuld tabelscanninger
Forholdet mellem fuld tabelscanninger, en operation, der kræver læsning af hele indholdet af en tabel, i stedet for kun udvalgte dele ved hjælp af et indeks. Denne værdi er høj, hvis du laver mange forespørgsler, der kræver sortering af resultater eller tabelscanninger. Generelt tyder dette på, at tabeller ikke er korrekt indekseret, eller at dine forespørgsler ikke er skrevet for at drage fordel af de indekser, du har. Sådan beregnes procentdelen af fuld tabelscanninger:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Den gode værdi bør være under 25 %. Undersøg MySQL langsomme forespørgselslogoutput for at finde ud af de suboptimale forespørgsler.
Vælg Fuld tilmelding
Status for select_full_join er antallet af joinforbindelser, der udfører tabelscanninger, fordi de ikke bruger indekser. Hvis denne værdi ikke er 0, bør du omhyggeligt kontrollere indekserne for dine tabeller.
Vælg Range Check
Status for select_range_check er antallet af joinforbindelser uden nøgler, der kontrollerer nøglebrug efter hver række. Hvis dette ikke er 0, bør du omhyggeligt tjekke indeksene for dine tabeller.
Sortér kort
Forholdet mellem fletninger, som sorteringsalgoritmen har skullet udføre. Hvis denne værdi er høj, bør du overveje at øge værdien af sort_buffer_size og read_rnd_buffer_size. En simpel forholdsberegning er:
Sort passes = sort_merge_passes / (sort_scan + sort_range)En forholdsværdi lavere end 3 bør være en god værdi. Hvis du vil øge sort_buffer_size eller read_rnd_buffer_size, så prøv at øge i små trin, indtil du når det acceptable forhold.
InnoDB-ydelse
InnoDB Buffer Pool Hit Rate
Forholdet mellem, hvor ofte dine sider hentes fra hukommelsen i stedet for disken. Hvis værdien er lav under tidlig opstart af MySQL, skal du give bufferpuljen lidt tid til at varme op. Brug SHOW ENGINE INNODB STATUS-sætningen for at få bufferpuljens hitrate:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Den bedste værdi er 1000/10000 hitrate. For en lavere værdi angiver hitraten på 986/1000 for eksempel, at ud af 1000 sidelæsninger var den i stand til at læse sider i RAM 986 gange. De resterende 14 gange måtte MySQL læse siderne fra disken. Simpelthen sagt, 1000 / 1000 er den bedste værdi, som vi forsøger at opnå her, hvilket betyder, at de ofte tilgåede data passer fuldt ud i RAM.
Forøgelse af variabelen innodb_buffer_pool_size vil hjælpe meget med at rumme mere plads til MySQL at arbejde på. Sørg dog for, at du har tilstrækkelige RAM-ressourcer på forhånd. Fjernelse af overflødige indekser kunne også hjælpe. Hvis du har flere bufferpuljeforekomster, skal du sørge for, at hitraten for hver forekomst når 1000/1000.
InnoDB Dirty Pages
Forholdet mellem, hvor ofte InnoDB skal skylles. Under den skrivetunge belastning er det normalt, at denne procentdel stiger.
En simpel beregning ville være:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100En god værdi bør være 75 % og derunder. Hvis procentdelen af snavsede sider forbliver høj i lang tid, vil du måske øge bufferpuljen eller få hurtigere diske for at undgå flaskehalse i ydeevnen.
InnoDB venter på kontrolpunkt
Forholdet mellem, hvor ofte InnoDB skal læse eller oprette en side, hvor ingen rene sider er tilgængelige. Normalt sker skrivninger til InnoDB Buffer Pool i baggrunden. Men hvis det er nødvendigt at læse eller oprette en side, og ingen rene sider er tilgængelige, er det også nødvendigt at vente på, at siderne skylles først. Innodb_buffer_pool_wait_free tælleren tæller, hvor mange gange dette er sket. For at beregne forholdet mellem InnoDB-venter til checkpointing kan vi bruge følgende beregning:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsHvis innodb_buffer_pool_wait_free er større end 0, er det en stærk indikator for, at InnoDB bufferpuljen er for lille, og operationer måtte vente på et kontrolpunkt. Forøgelse af innodb_buffer_pool_size vil normalt reducere innodb_buffer_pool_wait_free, såvel som dette forhold. En god forholdsværdi bør forblive under 1.
InnoDB venter på Redolog
Forholdet mellem gentag logpåstand. Tjek innodb_log_waits, og hvis den fortsætter med at stige, så øg innodb_log_buffer_size. Det kan også betyde, at diskene er for langsomme og ikke kan opretholde diskens IO, måske på grund af maksimal skrivebelastning. Brug følgende beregning til at beregne gentag-logventeforholdet:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesEn god forholdsværdi bør være under 1. Ellers skal du øge innodb_log_buffer_size.
Tabeller
Brug af tabelcache
Forholdet mellem brug af tabelcache for alle tråde. En simpel beregning ville være:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Den gode værdi bør være mindre end 80 %. Forøg table_open_cache-variablen, indtil procentdelen når en god værdi.
Tabelcache-hitforhold
Forholdet mellem brug af tabelcachehit. En simpel beregning ville være:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100En god hit ratio-værdi skal være 90 % og derover. Ellers skal du øge table_open_cache-variablen, indtil hitforholdet når en god værdi.
Metrics-overvågning med ClusterControl
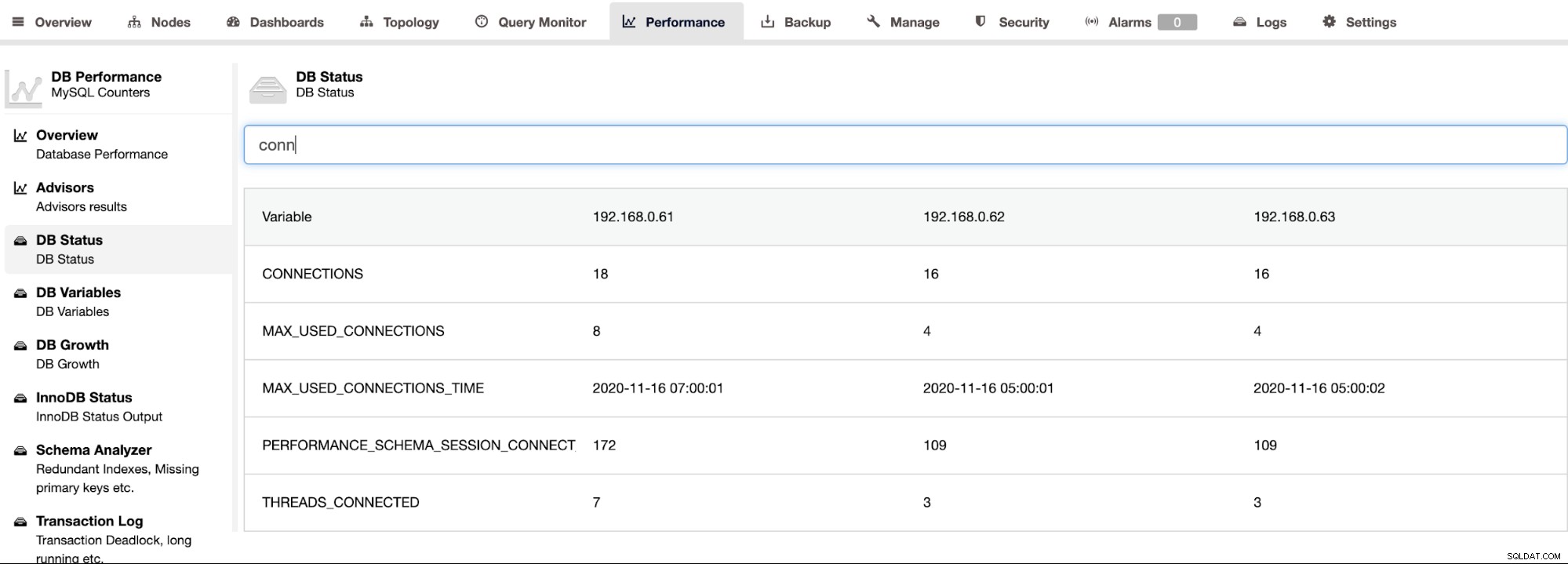
ClusterControl understøtter Percona Server til MySQL, og den giver en samlet visning af alle noder i en klynge på siden ClusterControl -> Ydelse -> DB Status. Dette giver en centraliseret tilgang til at slå op efter al status på alle værter med mulighed for at filtrere status, som vist på følgende skærmbillede:
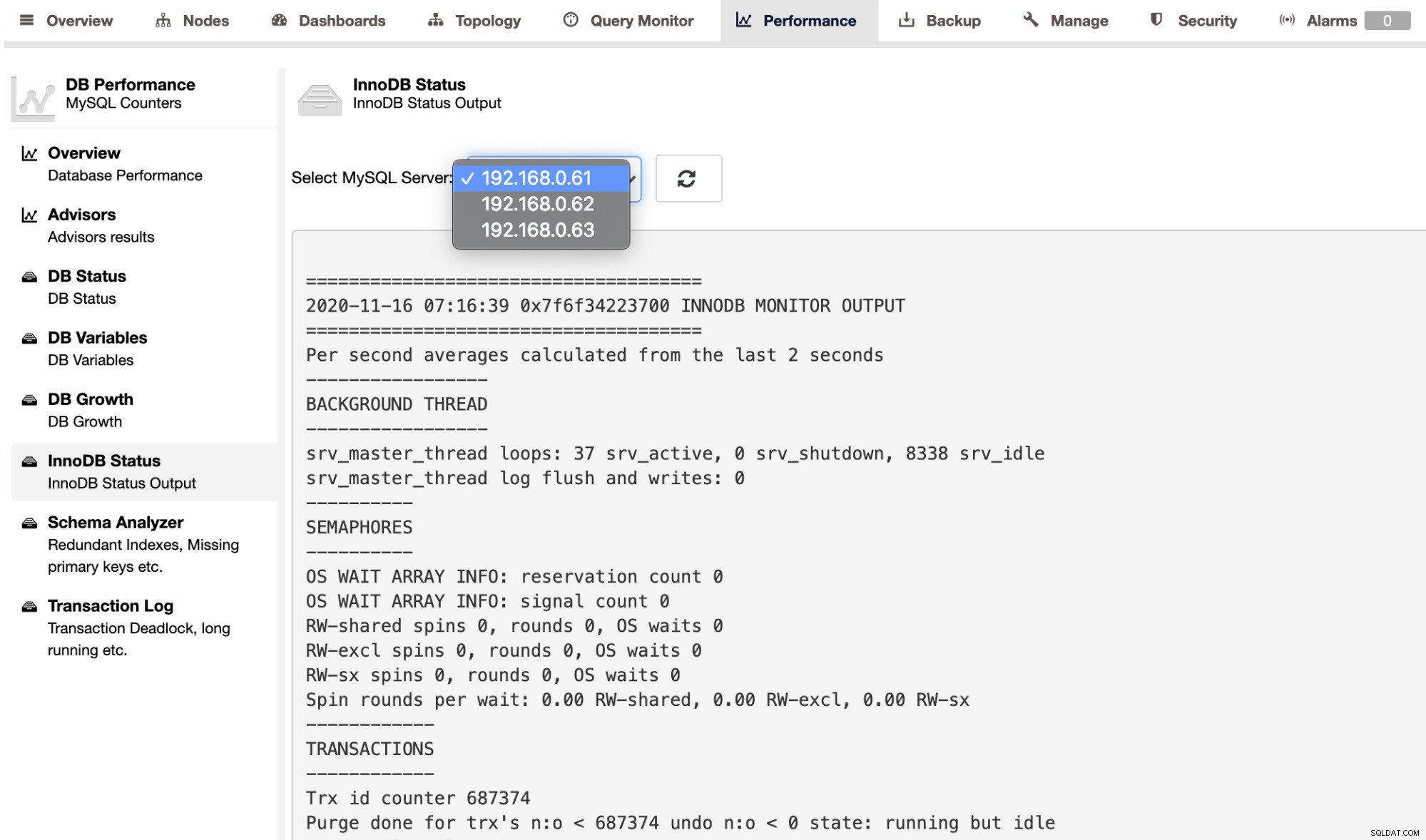
For at hente SHOW ENGINE INNODB STATUS-output for en individuel server, kan du evt. brug siden Ydelse -> InnoDB Status, som vist nedenfor:
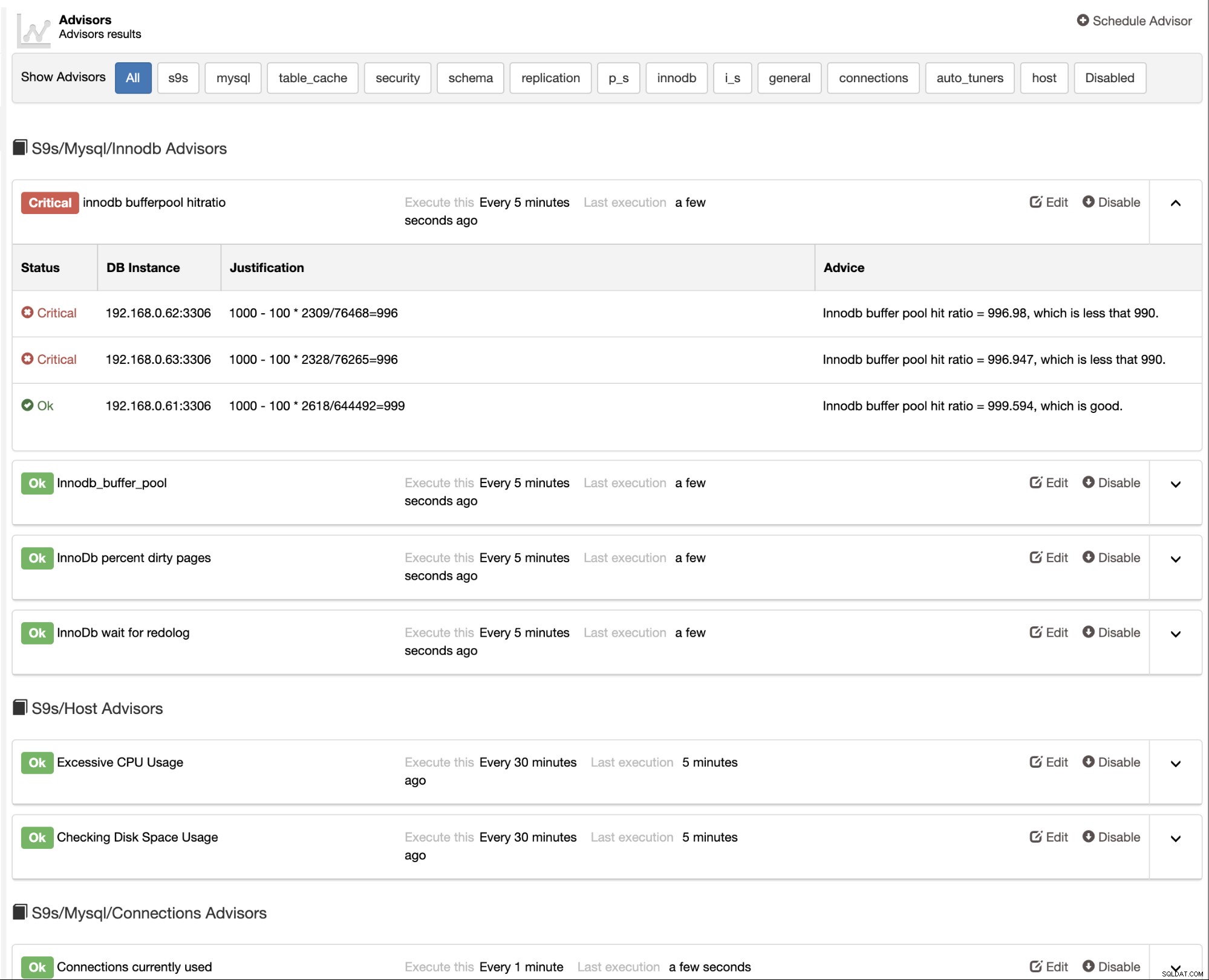
ClusterControl har også indbyggede rådgivere, som du kan bruge til at spore din database ydeevne. Denne funktion er tilgængelig under ClusterControl -> Ydelse -> Rådgivere:
Rådgivere er grundlæggende miniprogrammer, der udføres af ClusterControl i en planlagt timing som cron job. Du kan planlægge en rådgiver ved at klikke på knappen "Schedule Advisor" og vælge enhver eksisterende rådgiver fra Developer Studio objekttræet:
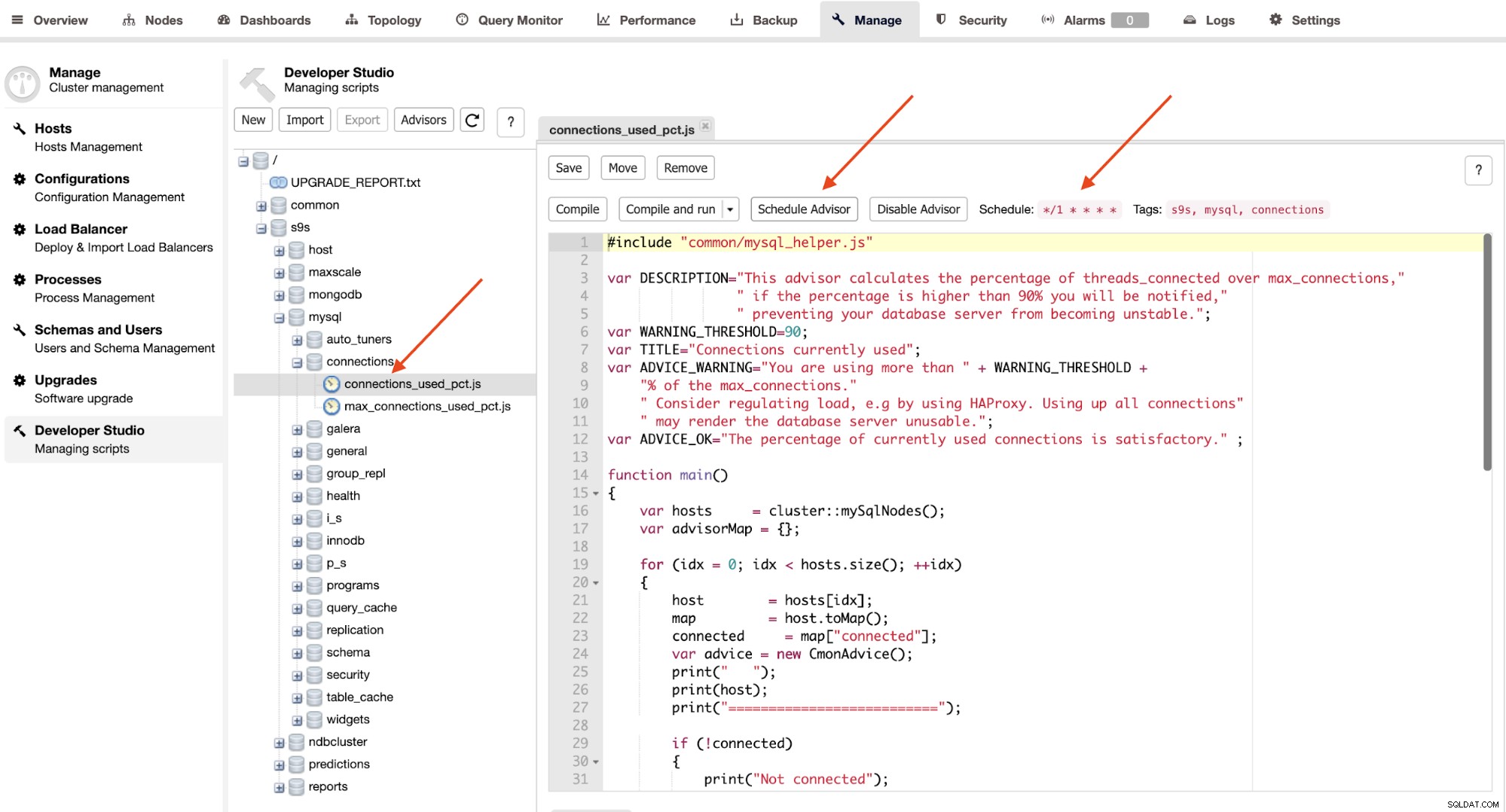
Klik på knappen "Schedule Advisor" for at indstille planlægningen, argument til pass og også rådgiverens tags. Du kan også kompilere rådgiveren for at se outputtet med det samme ved at klikke på knappen "Kompilér og kør", hvor du skal se følgende output under "Beskeder" nedenunder:

Du kan oprette din egen rådgiver ved at henvise til denne udviklervejledning, skrevet i ClusterControl Domain Specific Language (meget lig Javascript), eller tilpas en eksisterende rådgiver, så den passer til dine overvågningspolitikker. Kort sagt kan ClusterControls overvågningspligt udvides med ubegrænsede muligheder gennem ClusterControl Advisors.