I betragtning af den nuværende store use-case for en database til at hente data, bliver det meget vigtigt, at dens ydeevne er meget høj, og det kan kun opnås, hvis data hentes på den mest effektive måde fra lageret. Der har været mange succesrige opfindelser og implementeringer for at opnå det samme. En af de velkendte tilgange, der anvendes af de fleste databaser, er at have et indeks på bordet.
Hvad er et databaseindeks?
Database Index, som navnet antyder, vedligeholder et indeks til de faktiske data og forbedrer derved ydeevnen til at hente data fra den faktiske tabel. I en mere database-terminologi tillader indekset at hente side, der indeholder indekserede data i en meget minimal gennemgang, da data er sorteret i bestemt rækkefølge. Indeksfordele kommer på bekostning af yderligere lagerplads for at kunne skrive yderligere data. Indekser er specifikke for den underliggende tabel og består af en eller flere nøgler (dvs. en eller flere kolonner i den angivne tabel). Der er primært to typer indeksarkitektur
- Klynget indeks – Indeksdata gemmes sammen med andre dele af data, og data sorteres baseret på indeksnøgle. Der kan højst være et indeks i denne kategori for en specificeret tabel.
- Ikke-klynget indeks – Indeksdata gemmes separat, og det har en pegepind til det lager, hvor andre dele af data er gemt. Dette er også kendt som sekundært indeks. Der kan være så mange indekser af denne kategori, som du ønsker på en specificeret tabel.
Der er forskellige datastrukturer, der bruges til at implementere indekser, nogle af de almindeligt anvendte af de fleste databaser er B-Tree og Hash.
Hvad er et PostgreSQL-indeks?
PostgreSQL understøtter kun ikke-klyngede indeks. Det betyder indeksdata og komplette data (her og videre omtalt som heap-data ) opbevares i et separat lager. Ikke-klyngede indekser er som "Indholdsfortegnelse" i ethvert dokument, hvor vi først tjekker sidetallet og derefter tjekker disse sidetal for at læse hele indholdet. For at få de komplette data baseret på et indeks, vedligeholder den en pointer til tilsvarende heap-data. Det er det samme, som efter at have kendskab til sidenummeret, skal det gå til den side og få det faktiske indhold på siden.
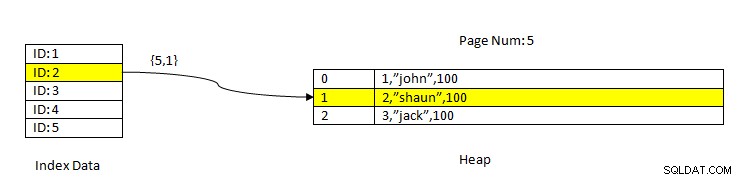 PostgreSQL:Data læst ved hjælp af Index
PostgreSQL:Data læst ved hjælp af Index Overvej f.eks. en tabel med tre kolonner og et indeks på kolonne ID . For at LÆSE data baseret på nøglen ID=2, søges først i de indekserede data med ID-værdien 2. Denne indeholder en pointer (kaldet som Item Pointer) i form af sidenummer (dvs. bloknummer) og forskydning af data på den side. I det aktuelle eksempel peger indekset på sidenummer 5 og den anden linjepost på siden, som igen forbliver offset til hele data(2,"Shaun",100). Bemærk, at hele data også indeholder de indekserede data, hvilket betyder, at de samme data gentages i to lagre.
Hvordan hjælper INDEX med at forbedre ydeevnen? Nå, for at vælge en hvilken som helst INDEX-post, scanner den ikke alle sider sekventielt, men skal blot delvist scanne nogle af siderne ved hjælp af den underliggende indeksdatastruktur. Men der er et twist, da hver post fundet fra indeksdata, skal den søge i Heap-data for hele data, hvilket forårsager en masse tilfældige I/O, og det anses for at fungere langsommere end sekventiel I/O. Så kun hvis en lille procentdel af poster bliver valgt (som afgøres baseret på PostgreSQL optimizer Cost), så er det kun PostgreSQL, der vælger Index Scan ellers selvom der er et indeks på bordet, fortsætter den med at bruge Sequence Scan.
Sammenfattende, selvom oprettelse af indeks fremskynder ydeevnen, bør den vælges omhyggeligt, da den har overhead med hensyn til lagring, forringet INSERT-ydeevne.
Nu kan vi undre os, hvis vi kun har brug for indeksdelen af data, kan vi kun hente fra indekslagersiden? Nå, svaret på dette er direkte relateret til, hvordan MVCC fungerer på indekslageret, som forklaret i det følgende.
Brug af MVCC til indeksering
Ligesom Heap-sider, vedligeholder indekssiden flere versioner af indekset, men den vedligeholder ikke synlighedsoplysninger. Som forklaret i min tidligere MVCC blog, for at beslutte passende synlig version af tuples, det kræver at sammenligne transaktion. Transaktionen, der indsatte/opdaterede/slettede tuple, opretholdes sammen med heap tuple, men det samme opretholdes ikke med indeks tuple. Dette er udelukkende gjort for at spare lagerplads, og det er en afvejning mellem plads og ydeevne.
For nu at komme tilbage til det oprindelige spørgsmål, da synlighedsoplysningerne i Index tuple ikke er der, skal den konsultere den tilsvarende heap tuple for at se, om de valgte data er synlige. Så selvom andre dele af dataene fra heap tuple ikke er påkrævet, skal du stadig have adgang til heap-siderne for at kontrollere synlighed. Men igen, der er et twist, hvis alle tuples på en given side (side peget med indeks, dvs. ItemPointer) er synlige, så behøver du ikke henvise hvert element på Heap-siden til "synlighedstjek", og dataene kan derfor kun returneres fra indekssiden. Dette specielle tilfælde kaldes "Kun indeksscanning". For at understøtte dette vedligeholder PostgreSQL et synlighedskort for hver side for at kontrollere sideniveauets synlighed.
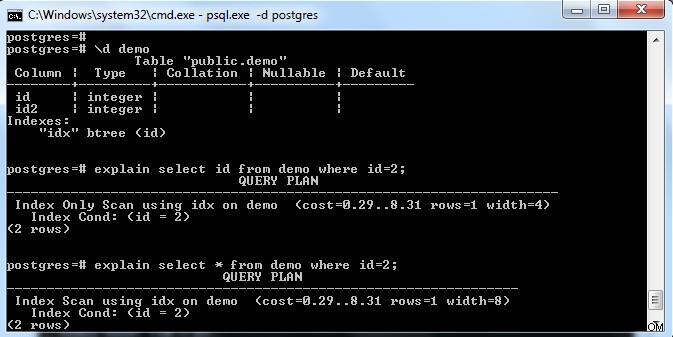
Som vist på ovenstående billede er der et indeks på tabellen "demo" med en tast på kolonnen "id". Hvis vi prøver kun at vælge indeksfelt (dvs. id), så valgte den "Kun indeksscanning" (i betragtning af at henvisningssiden er fuldt synlig).
Clustered Index
Der er ingen støtte til direkte clustered index i PostgreSQL, men der er en indirekte måde at delvist opnå det samme. Dette opnås ved hjælp af nedenstående SQL-kommandoer:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Den første kommando instruerer databasen til at gruppere en tabel (dvs. at sortere tabel) ved hjælp af det givne indeks. Dette indeks burde allerede være oprettet. Denne klyngedannelse er kun engangsoperation, og dens virkning forbliver ikke efter den efterfølgende operation på denne tabel, dvs. hvis flere poster indsættes/opdateres, forbliver tabellen muligvis ikke i orden. Hvis det er nødvendigt af brugeren for stadig at holde tabellen grupperet (ordnet), kan de bruge den første kommando uden at angive et indeksnavn.
Den anden kommando er kun nyttig til at re-cluster tabel (dvs. den tabel, der allerede var klynget ved hjælp af et eller andet indeks). Denne kommando omgrupperer alle tabeller i den aktuelle database, som er synlige for den aktuelle tilsluttede bruger.
For eksempel i nedenstående figur, returnerer den første SELECT poster i usorteret rækkefølge, da der ikke er noget klynget indeks. Selvom der allerede er et ikke-klynget indeks, men posterne bliver valgt fra heapområdet, hvor posterne ikke er sorteret.
Den anden SELECT returnerer posterne sorteret efter kolonne "id", som den er blevet grupperet ved hjælp af indeks indeholdende kolonne "id".
Den tredje SELECT returnerer delvise poster i sorteret rækkefølge, men nyligt indsatte poster sorteres ikke. Den fjerde SELECT returnerer igen alle poster i sorteret rækkefølge, efterhånden som tabellen er blevet grupperet igen
 PostgreSQL Cluster Command
PostgreSQL Cluster Command Indekstype
PostgreSQL giver flere typer indekser som nedenfor:
- B-træ
- Hash
- GiST
- GIN
- BRIN
Hver indekstype implementerer forskellige former for underliggende datastruktur, som er bedst egnet til forskellige typer forespørgsler. Som standard oprettes B-Tree indeks, som er meget udbredte indekser. Detaljer om hver indekstype vil blive dækket i en fremtidig blog.
Diverse:Delvis og udtryksindeks
Vi har kun diskuteret indekser på en eller flere kolonner i en tabel, men der er to andre måder at oprette indekser på PostgreSQL
- Delvis indeks: Delvis indeks er et indeks bygget ved hjælp af delmængden af en nøglekolonne for en bestemt tabel. Undersættet er defineret af det betingede udtryk givet under oprettelse af indeks. Så med det delvise indeks bliver lagerplads til lagring af indeksdata gemt. Så brugeren bør vælge betingelsen på en sådan måde, at disse ikke er meget almindelige værdier, da for hyppigere (fælles) værdier alligevel ikke vil indeksscanning blive valgt. Resten af funktionaliteten forbliver den samme som for et normalt indeks. Eksempel:Delvis indeks
- Udtryksindeks: Udtryksindekser giver en anden form for fleksibilitet i PostgreSQL. Alle indekser, der er diskuteret indtil nu, inklusive delvise indekser, er på et bestemt sæt kolonner. Men hvad hvis en forespørgsel involverer adgang til en tabel baseret på udtrykket (udtryk, der involverer en eller flere kolonner), uden et udtryksindeks vil den ikke vælge indeksscanning. Så for at få hurtig adgang til denne form for forespørgsler, tillader PostgreSQL at oprette et indeks på et udtryk. Resten af funktionaliteten forbliver den samme som for et normalt indeks.
 Eksempel:Udtryksindeks
Eksempel:Udtryksindeks
Indekslagring i InnoDB
Brugen og funktionaliteten af Index er stort set den samme som i PostgreSQL med en stor forskel med hensyn til Clustered Index.
InnoDB understøtter to kategorier af indekser:
- Klynget indeks
- Sekundært indeks
Clustered Index
Clustered Index er en speciel form for indeks i InnoDB. Her lagres de indekserede data ikke separat, men er en del af hele rækkedata. Med andre ord tvinger det klyngede indeks bare tabeldataene til at blive sorteret fysisk ved hjælp af nøglekolonnen i indekset. Det kan betragtes som "Ordbog", hvor data er sorteret ud fra alfabetet.
Da det klyngede indeks sorterer rækker ved hjælp af en indeksnøgle, kan der kun være ét klynget indeks. Der skal også være ét klynget indeks, da InnoDB bruger det samme til at manipulere data optimalt under forskellige dataoperationer.
Klyngede indeks oprettes automatisk (som en del af tabeloprettelse) ved hjælp af en af tabelkolonnerne i henhold til nedenstående prioritet:
- Brug af den primære nøgle, hvis den primære nøgle er nævnt som en del af tabeloprettelsen.
- Vælger enhver unik kolonne, hvor alle nøglekolonner IKKE er NULL.
- Ellers genererer internt et skjult klynget indeks på en systemkolonne, som indeholder række-id'et for hver række.
I modsætning til PostgreSQL ikke-klyngede indeks, får InnoDB hurtigere adgang til en række ved hjælp af klynget indeks, fordi indekssøgningen fører direkte til siden med alle rækkedata og dermed undgår tilfældig I/O.
Det er også meget hurtigt at få tabeldataene i sorteret rækkefølge ved hjælp af det klyngede indeks, da alle data allerede er sorteret, og også hele data er tilgængelige.
Sekundært indeks
Indekset, der er oprettet eksplicit i InnoDB, anses for at være et sekundært indeks, som ligner PostgreSQL ikke-klynget indeks. Hver post i det sekundære indekslager indeholder en primær nøglekolonner af rækkerne (som blev brugt til at skabe et Clustered Index) og også de kolonner, der er specificeret til at oprette et sekundært indeks.
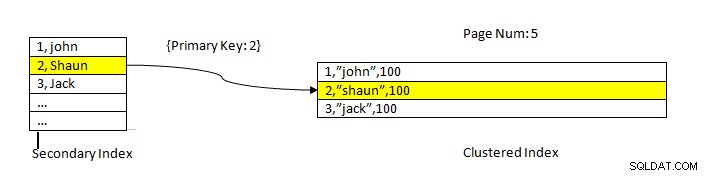 InnoDB:Data læst ved hjælp af indeks
InnoDB:Data læst ved hjælp af indeks Hentning af data ved hjælp af et sekundært indeks svarer til PostgreSQL's tilfælde, bortset fra at InnoDB sekundært indeksopslag giver en primær nøgle som en pointer til at hente de resterende data fra det klyngede indeks.
For eksempel, som vist på billedet ovenfor, er det klyngede indeks på kolonne ID, så tabeldata er sorteret efter det samme. Det sekundære indeks er i kolonnen "navn ”, så som vi kan se har det sekundære indeks både ID og navneværdi. Når vi slår op ved hjælp af det sekundære indeks, finder det den passende slot med den tilsvarende nøgleværdi. Derefter bruges den tilsvarende primærnøgle til at henvise til den resterende del af dataene fra det klyngede indeks.
MVCC for Index
Det klyngede indeks MVCC bruger den traditionelle InnoDB Fortryd-model (faktisk det samme som hele data MVCC, da det klyngede indeks ikke er andet end hele data).
Men det sekundære indeks MVCC bruger en lidt anden tilgang til at opretholde MVCC. Ved opdatering af det sekundære indeks slettes den gamle indeksindgang, og nye poster indsættes i samme lager, dvs. OPDATERING er ikke på plads. Endelig bliver gamle indeksposter slettet. På nuværende tidspunkt har du måske bemærket, at InnoDB sekundært indeks MVCC er næsten det samme som for PostgreSQL MVCC-modellen.
Indekstype
InnoDB understøtter kun B-Tree type indeks og kræves derfor ikke specificeret under oprettelse af indeks.
Diverse:Adaptive Hash Indexes
Som nævnt i det foregående afsnit understøttes kun B-Tree type indeks af InnoDB, men der er et twist. InnoDB har funktionaliteten til automatisk at registrere, om forespørgslen kan drage fordel af at bygge et hash-indeks, og også hele tabellens data kan passe ind i hukommelsen, så gør den det automatisk.
Hash-indekset er bygget ved hjælp af det eksisterende B-Tree-indeks afhængigt af forespørgslen. Hvis der er flere sekundære B-Tree-indekser, vil den vælge det, der kvalificerer sig i henhold til forespørgslen. Det opbyggede hash-indeks er ikke komplet, det bygger kun et delvist indeks i henhold til databrugsmønsteret.
Dette er en af de virkelig kraftfulde funktioner til dynamisk at forbedre forespørgselsydeevnen.
Konklusion
Brugen af ethvert indeks i enhver database er virkelig nyttig til at forbedre READ-ydeevnen, men samtidig forringer den INSERT/UPDATE-ydeevnen, da den skal skrive yderligere data. Så indekset bør vælges meget klogt og bør kun oprettes, hvis indeksnøglerne bliver brugt som et prædikat til at hente data.
InnoDB giver en meget god funktion med hensyn til det klyngede indeks, som kan være meget nyttigt afhængigt af use-cases. Dens adaptive hash-indeksering er også meget kraftfuld.
Hvorimod PostgreSQL tilbyder forskellige typer indekser, som virkelig kan give muligheder for rækkevidde af funktioner, og en eller alle kan bruges afhængigt af forretningsbrug. Også partial- og udtryksindekserne er ret nyttige afhængigt af brugssituationen.