Lagring af ~3,5 TB data og indsættelse af ca. 1K/sek 24x7, og også forespørgsel med en hastighed, der ikke er angivet, er det muligt med SQL Server, men der er flere spørgsmål:
- hvilket tilgængelighedskrav har du til dette? 99,999 % oppetid, eller er 95 % nok?
- hvilke pålidelighedskrav har du? Koster det dig 1 mio. USD at mangle en indsats?
- hvilket krav om inddrivelse har du? Hvis du mister en dags data, betyder det noget?
- hvilke konsistenskrav har du? Skal en skrivning garanteres for at være synlig ved næste læsning?
Hvis du har brug for alle disse krav, jeg fremhævede, vil den belastning, du foreslår, koste millioner i hardware og licensering på et relationssystem, et hvilket som helst system, uanset hvilke gimmicks du prøver (sharding, partitionering osv.). Et nosql-system ville ifølge deres definition ikke opfylde alle disse krav.
Så du har åbenbart allerede lempet nogle af disse krav. Der er en fin visuel guide, der sammenligner nosql-tilbuddene baseret på 'vælg 2 ud af 3'-paradigmet på Visual Guide to NoSQL Systems:
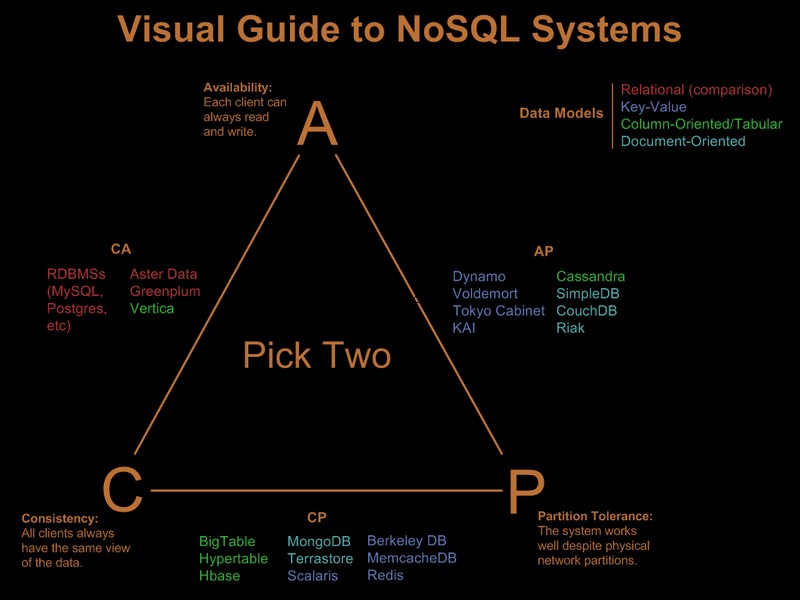
Efter OP-kommentaropdatering
Med SQL Server ville dette være en ligetil implementering:
- én enkelt tabel (GUID, tid) nøgle. Ja, vil blive fragmenteret, men er fragmentering påvirker read-aheads og read-aheads er kun nødvendige for betydelige rækkevidde scanninger. Da du kun forespørger efter specifik GUID og datointerval, betyder fragmentering ikke meget. Ja, er en bred nøgle, så sider uden blade vil have dårlig nøgletæthed. Ja, det vil føre til dårlig fyldningsfaktor. Og ja, sideopdelinger kan forekomme. På trods af disse problemer, givet kravene, er det stadig det bedste grupperede nøglevalg.
- opdel tabellen efter tid, så du kan implementere effektiv sletning af de udløbne poster via et automatisk glidende vindue. Udvid dette med en genopbygning af onlineindekspartitionen fra den sidste måned for at eliminere den dårlige udfyldningsfaktor og fragmentering introduceret af GUID-klyngningen.
- aktiver sidekomprimering. Da de klyngede nøglegrupper først efter GUID, vil alle registreringer af et GUID være ved siden af hinanden, hvilket giver sidekomprimering en god chance for at implementere ordbogskomprimering.
- du skal bruge en hurtig IO-sti til logfil. Du er interesseret i høj gennemstrømning, ikke med lav latenstid, for at en log skal kunne holde trit med 1K inserts/sek., så stripning er et must.
Partitionering og sidekomprimering kræver hver en Enterprise Edition SQL Server, de vil ikke fungere på Standard Edition, og begge er ret vigtige for at opfylde kravene.
Som en sidebemærkning, hvis posterne kommer fra en front-end webserverfarm, ville jeg sætte Express på hver webserver, og i stedet for INSERT på bagenden ville jeg SEND infoen til bagenden, ved hjælp af en lokal forbindelse/transaktion på Expressen, der er placeret sammen med webserveren. Dette giver en meget bedre tilgængelighedshistorie til løsningen.
Så det er sådan jeg ville gøre det i SQL Server. Den gode nyhed er, at de problemer, du står over for, er velforståede, og løsninger er kendte. det betyder ikke nødvendigvis, at dette er bedre end hvad du kunne opnå med Cassandra, BigTable eller Dynamo. Jeg vil lade nogen, der er mere vidende om ting, der ikke er sql-ish, til at argumentere for deres sag.
Bemærk, at jeg aldrig nævnte programmeringsmodellen, .Net support og sådan noget. Jeg tror helt ærligt, at de er irrelevante i store udrulninger. De gør en kæmpe forskel i udviklingsprocessen, men når de først er implementeret, er det lige meget hvor hurtigt udviklingen var, hvis ORM-overhead dræber ydeevnen :)