Dårlig forespørgselsydeevne er det mest almindelige problem, DBA'er skal håndtere. Der er adskillige måder at indsamle, behandle og analysere data relateret til forespørgselsydeevne på - vi har dækket et af de mest populære værktøjer, pt-query-digest, i nogle af vores tidligere blogindlæg:
Bliv en MySQL DBA-blogserie
- Analyse af din SQL-arbejdsbelastning ved hjælp af pt-query-digest
- Deep Dive SQL-arbejdsbelastningsanalyse ved hjælp af pt-query-digest
Når du bruger ClusterControl, er dette dog ikke altid nødvendigt. Du kan bruge de tilgængelige data i ClusterControl til at løse dit problem. I dette blogindlæg ser vi nærmere på, hvordan ClusterControl kan hjælpe dig med at løse problemer relateret til forespørgselsydeevne.
Det kan ske, at en forespørgsel ikke kan afsluttes rettidigt. Forespørgslen kan sidde fast på grund af nogle låseproblemer, den er muligvis ikke optimal eller ikke indekseret korrekt, eller den kan være for tung til at gennemføre inden for en rimelig tid. Husk, at et par ikke-indekserede joinforbindelser nemt kan scanne milliarder af rækker, hvis du har en stor produktionsdatabase. Uanset hvad der skete, bruger forespørgslen sandsynligvis nogle af ressourcerne - det være sig CPU eller I/O til en ikke-optimeret forespørgsel eller endda bare rækkelåse. Disse ressourcer er også nødvendige for andre forespørgsler, og det kan for alvor bremse tingene. En af de meget enkle, men vigtige opgaver ville være at lokalisere den stødende forespørgsel og stoppe den.
Det gøres ret nemt fra ClusterControl-grænsefladen. Gå til fanen Forespørgselsovervågning -> Kørende forespørgsler sektionen - du skulle se et output svarende til skærmbilledet nedenfor.
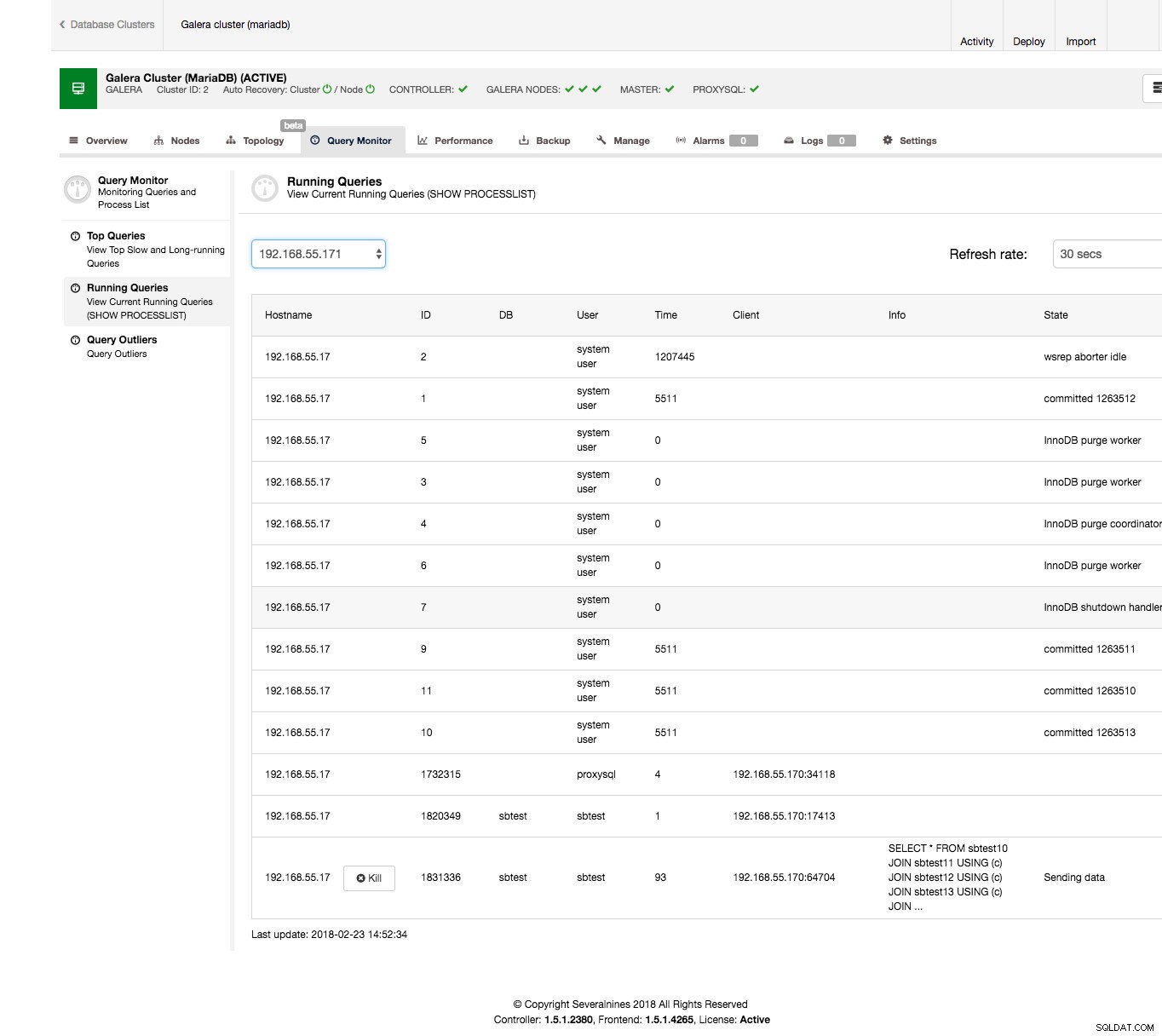
Som du kan se, har vi en bunke forespørgsler fast. Normalt er den stødende forespørgsel den, der tager lang tid, du vil måske slå den ihjel. Du vil måske også undersøge det nærmere for at sikre dig, at du vælger den rigtige. I vores tilfælde ser vi tydeligt et VÆLG ... TIL OPDATERING, som forbinder et par tabeller, og som er i tilstanden 'Sender data', hvilket betyder, at den behandler dataene i de sidste 90 sekunder.
En anden type spørgsmål, som en DBA kan have brug for at besvare er - hvilke forespørgsler tager mest tid at udføre? Dette er et almindeligt spørgsmål, da sådanne forespørgsler kan være en lavthængende frugt - de kan være optimerbare, og jo mere eksekveringstid en given forespørgsel er ansvarlig for i en hel forespørgselsmix, jo større er gevinsten ved dens optimering. Det er en simpel ligning - hvis en forespørgsel er ansvarlig for 50 % af den samlede eksekveringstid, vil det at gøre den 10 gange hurtigere give et meget bedre resultat end at optimere en forespørgsel, der kun er ansvarlig for 1 % af den samlede eksekveringstid.
ClusterControl kan hjælpe dig med at besvare sådanne spørgsmål, men først skal vi sikre, at Query Monitor er aktiveret. Du kan slå Query Monitor til TIL under Query Monitor-siden. Desuden kan du konfigurere "Lang forespørgselstid" og "Log forespørgsler, der ikke bruger indekser" under Indstillinger, så de passer til din arbejdsbyrde:
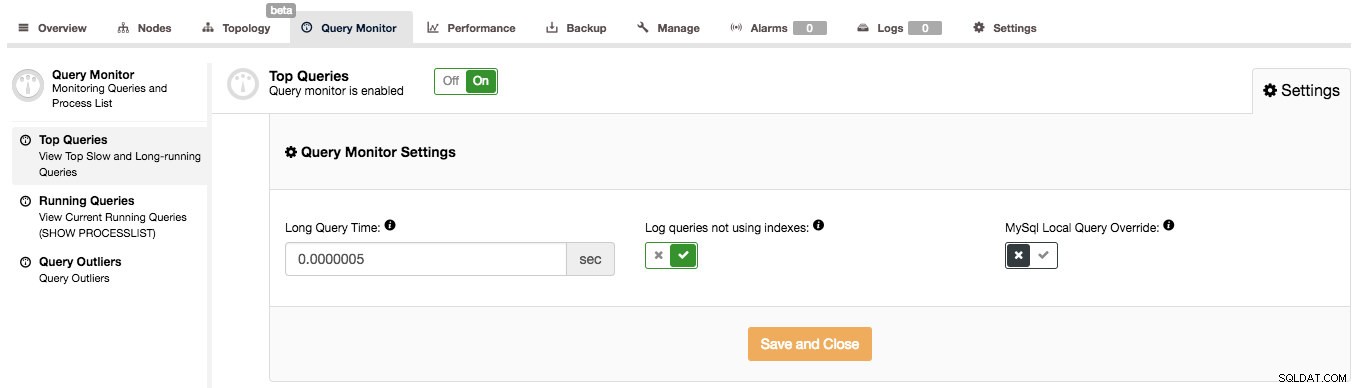
Forespørgselsmonitoren i ClusterControl fungerer i to tilstande, afhængigt af om du har Performance Schema tilgængeligt med de nødvendige data om de kørende forespørgsler eller ej. Hvis det er tilgængeligt (og dette er sandt som standard i MySQL 5.6 og nyere), vil Performance Schema blive brugt til at indsamle forespørgselsdata, hvilket minimerer indvirkningen på systemet. Ellers vil den langsomme forespørgselslog blive brugt, og alle de indstillinger, der er synlige i ovenstående skærmbillede, bruges. Disse er ret godt forklaret i brugergrænsefladen, så der er ingen grund til at gøre det her. Når Query Monitor bruger Performance Schema, bruges disse indstillinger ikke (bortset fra at slå Query Monitor TIL/FRA for at aktivere/deaktivere dataindsamling).
Når du har bekræftet, at Query Monitor er aktiveret i ClusterControl, kan du gå til Query Monitor -> Top Queries, hvor du vil blive præsenteret for en skærm, der ligner nedenstående:
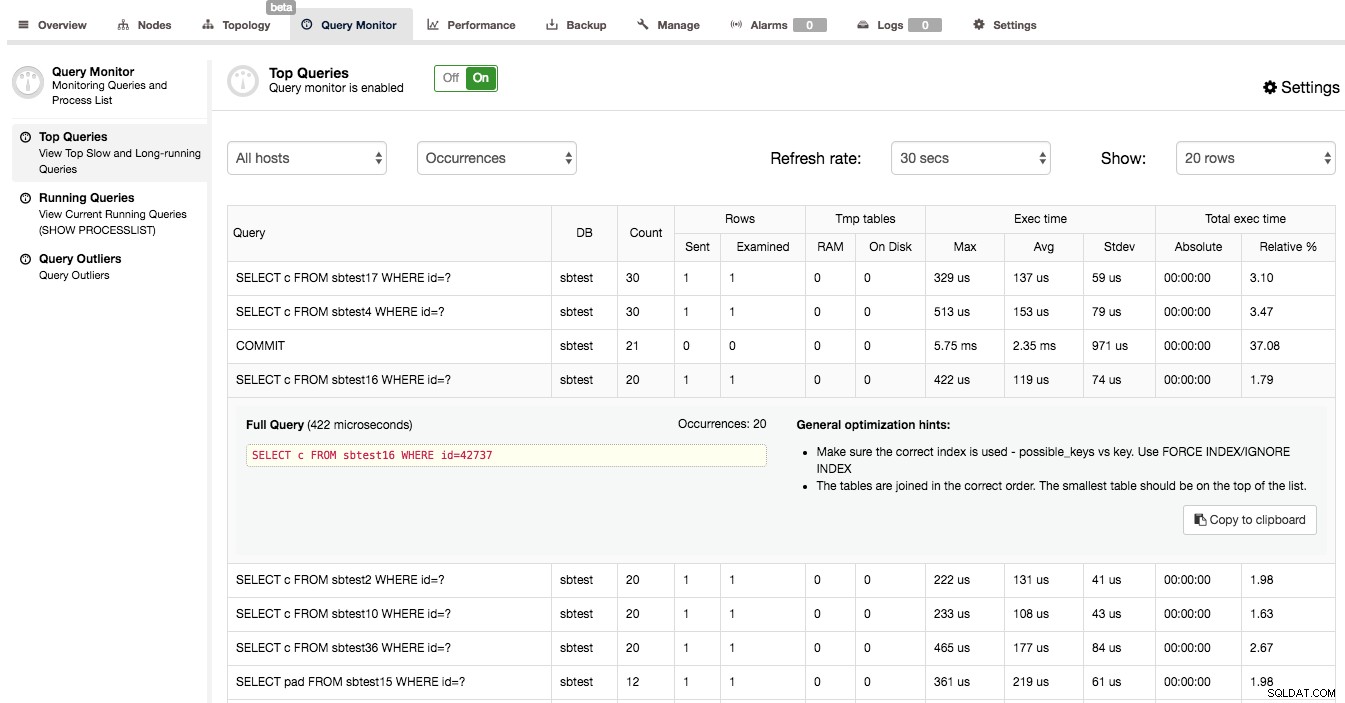
Det, du kan se her, er en liste over de dyreste forespørgsler (i form af eksekveringstid), der ramte vores klynge. Hver af dem har nogle yderligere detaljer - hvor mange gange den blev udført, hvor mange rækker der blev undersøgt eller sendt til klienten, hvordan eksekveringstiden varierede, hvor meget tid klyngen brugte på at udføre en given type forespørgsel. Forespørgsler er grupperet efter forespørgselstype og skema.
Du kan blive overrasket over at finde ud af, at det primære sted, hvor eksekveringstiden bruges, er en 'COMMIT'-forespørgsel. Faktisk er dette ret typisk for hurtige OLTP-forespørgsler udført på Galera-klyngen. At begå en transaktion er en dyr proces, fordi certificering skal ske. Dette fører til, at COMMIT er en af de mest tidskrævende forespørgsler i forespørgselsmixet.
Når du klikker på en forespørgsel, kan du se den fulde forespørgsel, maksimal udførelsestid, antal forekomster, nogle generelle optimeringstip og et FORKLAR-output for det - ret nyttigt til at identificere, om der er noget galt med det. I vores eksempel har vi markeret et VÆLG … FOR OPDATERING med et højt antal undersøgte rækker. Som forventet er denne forespørgsel et eksempel på frygtelig SQL - en JOIN, som ikke bruger noget indeks. Du kan se på EXPLAIN-outputtet, at der ikke bruges noget indeks, ikke et eneste blev endda anset for muligt at bruge. Ikke underligt, at denne forespørgsel alvorligt påvirkede vores klynges ydeevne.
En anden måde at få lidt indsigt i forespørgselsydeevne på er at se på Query Monitor -> Query Outliers. Dette er grundlæggende en liste over forespørgsler, hvis ydeevne afviger væsentligt fra deres gennemsnit.
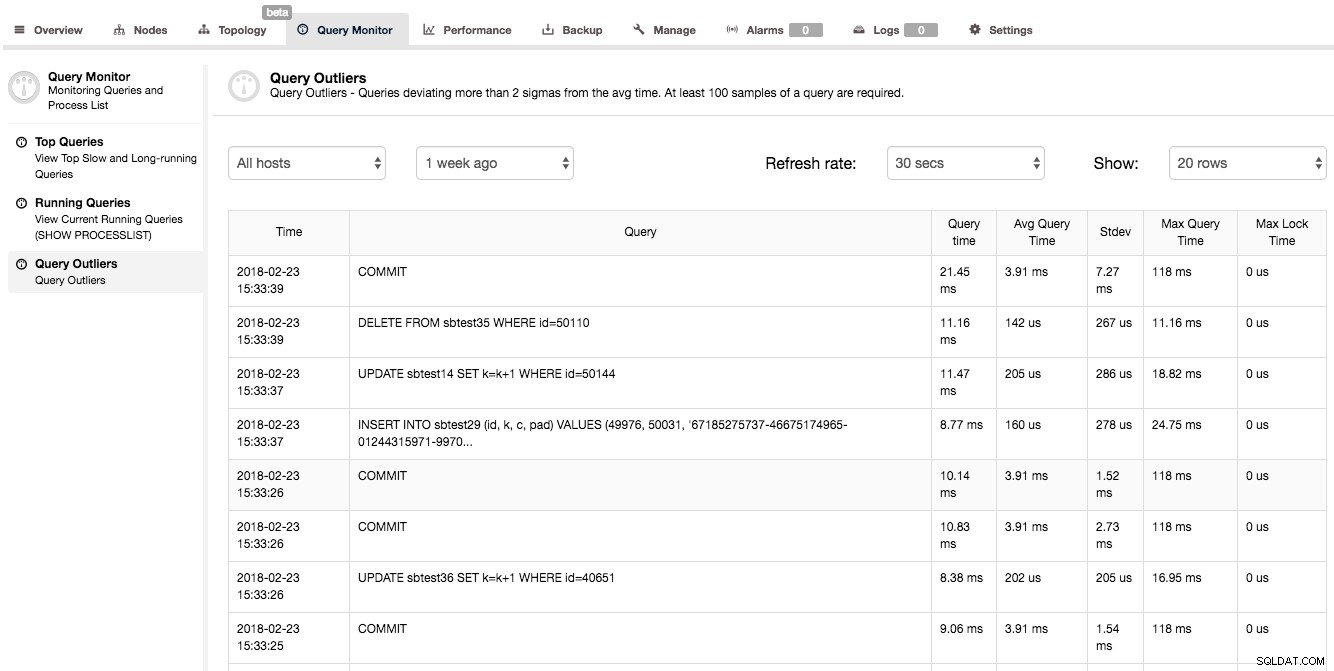
Som du kan se på ovenstående skærmbillede, tog den anden forespørgsel 0,01116s (tiden vises i millisekunder), hvor den gennemsnitlige udførelsestid for den forespørgsel er meget lavere (0,000142s). Vi har også nogle yderligere statistiske oplysninger om standardafvigelse og maksimal udførelsestid for forespørgsler. En sådan liste over forespørgsler ser måske ikke ud til at være særlig nyttig - det er ikke rigtigt. Når du ser en forespørgsel på denne liste, betyder det, at noget var anderledes end det sædvanlige - forespørgslen blev ikke fuldført inden for normal tid. Det kan være en indikation af nogle ydelsesproblemer på dit system og et signal om, at du bør undersøge andre målinger og tjekke, om der skete noget andet på det tidspunkt.
Folk har en tendens til at fokusere på at opnå maksimal ydeevne og glemmer, at det ikke er nok at have høj gennemstrømning - det skal også være konsekvent. Brugere kan lide, at ydeevnen er stabil - du kan muligvis presse flere transaktioner pr. sekund fra dit system, men hvis det betyder, at nogle transaktioner begynder at gå i stå i sekunder, er det ikke det værd. At se på forespørgselshistogrammet i ClusterControl hjælper dig med at identificere sådanne konsistensproblemer i dit forespørgselsmix.
Glad forespørgselsovervågning!
PS.:Klik her for at komme i gang med ClusterControl!