MySQL-replikering har været den mest almindelige og udbredte løsning til høj tilgængelighed af store organisationer som Github, Twitter og Facebook. Selvom det er let at konfigurere, er der udfordringer ved brug af denne løsning fra vedligeholdelse, herunder softwareopgraderinger, datadrift eller datainkonsistens på tværs af replikaknuderne, topologiændringer, failover og gendannelse. Da MySQL udgav version 5.6, bragte det en række væsentlige forbedringer, især til replikering, som inkluderer Global Transaction ID'er (GTID'er), hændelseskontrolsummer, multi-threaded slaves og crash-sikre slaves/masters. Replikering blev endnu bedre med MySQL 5.7 og MySQL 8.0.
Replikering gør det muligt at replikere data fra én MySQL-server (den primære/master) til en eller flere MySQL-servere (replikaen/slaverne). MySQL-replikering er meget nem at konfigurere og bruges til at udskalere læsearbejdsbelastninger, give høj tilgængelighed og geografisk redundans og aflaste sikkerhedskopier og analysejob.
MySQL-replikering i naturen
Lad os få et hurtigt overblik over, hvordan MySQL-replikering fungerer i naturen. MySQL-replikering er bredt, og der er flere måder at konfigurere det på, og hvordan det kan bruges. Som standard bruger den asynkron replikering, som fungerer efterhånden som transaktionen gennemføres i det lokale miljø. Der er ingen garanti for, at nogen begivenhed nogensinde vil nå nogen slave. Det er et løst koblet herre-slave forhold, hvor:
-
Primær venter ikke på en replika.
-
Replika bestemmer, hvor meget der skal læses og fra hvilket punkt i den binære log.
-
Replika kan være vilkårligt bagud for mester i at læse eller anvende ændringer.
Hvis det primære går ned, er transaktioner, som det har begået, muligvis ikke blevet overført til nogen replika. Følgelig kan failover fra primær til den mest avancerede replika i dette tilfælde resultere i en failover til den ønskede primære, som faktisk mangler transaktioner i forhold til den tidligere server.
Asynkron replikering giver lavere skriveforsinkelse, da en skrivning godkendes lokalt af en master, før den skrives til slaver. Det er fantastisk til læseskalering, da tilføjelse af flere replikaer ikke påvirker replikeringsforsinkelsen. Gode anvendelsesmuligheder for asynkron replikering omfatter udrulning af læsereplikaer til læseskalering, live backup-kopi til katastrofegendannelse og analyser/rapportering.
MySQL semi-synkron replikering
MySQL understøtter også semi-synkron replikering, hvor masteren ikke bekræfter transaktioner til klienten, før mindst én slave har kopieret ændringen til sin relælog og tømt den til disken. For at aktivere semi-synkron replikering kræves der ekstra trin til plugin-installation, og de skal være aktiveret på de udpegede MySQL-master- og slaveknuder.
Halvsynkron ser ud til at være en god og praktisk løsning i mange tilfælde, hvor høj tilgængelighed og intet datatab er vigtigt. Men du bør overveje, at semi-synkron har en ydeevnepåvirkning på grund af den ekstra rundtur og ikke giver stærke garantier mod tab af data. Når en commit vender tilbage med succes, er det kendt, at dataene findes på mindst to steder (på masteren og mindst én slave). Hvis masteren begår, men der opstår et nedbrud, mens masteren venter på en bekræftelse fra en slave, er det muligt, at transaktionen ikke er nået til nogen slave. Dette er ikke så stort et problem, da forpligtelsen ikke vil blive returneret til ansøgningen i dette tilfælde. Det er applikationens opgave at prøve transaktionen igen i fremtiden. Det, der er vigtigt at huske på, er, at når masteren fejler, og en slave er blevet forfremmet, kan den gamle master ikke slutte sig til replikationskæden. Under nogle omstændigheder kan dette føre til konflikter med data på slaverne, dvs. når masteren styrtede ned efter slaven modtog den binære loghændelse, men før masteren fik bekræftelsen fra slaven). Den eneste sikre måde er således at kassere dataene på den gamle master og levere dem fra bunden ved hjælp af dataene fra den nyligt forfremmede master.
Brug af replikeringsformatet forkert
Siden MySQL 5.7.7 bruger standard binær logformat eller binlog_format variabel ROW, som var STATEMENT før 5.7.7. De forskellige replikeringsformater svarer til den metode, der bruges til at registrere kildens binære loghændelser. Replikering fungerer, fordi hændelser skrevet til den binære log læses fra kilden og derefter behandles på replikaen. Hændelserne registreres i den binære log i forskellige replikeringsformater afhængigt af typen af hændelse. Ikke at vide med sikkerhed, hvad man skal bruge, kan være et problem. MySQL har tre formater af replikeringsmetoder:STATEMENT, ROW og MIXED.
-
Det STATEMENT-baserede replikeringsformat (SBR) er præcis, hvad det er – en replikeringsstrøm af hver sætning, der køres på masteren, der vil blive afspillet på slaveknuden. Som standard udfører MySQL traditionel (asynkron) replikering ikke de replikerede transaktioner til slaverne parallelt. Dermed betyder det, at rækkefølgen af udsagn i replikeringsstrømmen muligvis ikke er 100 % den samme. Afspilning af en sætning kan også give forskellige resultater, når den ikke udføres på samme tid, som når den udføres fra kilden. Dette fører til en inkonsistent tilstand i forhold til den primære og dens replika(er). Dette var ikke et problem i mange år, da ikke mange kørte MySQL med mange samtidige tråde. Men med moderne multi-CPU-arkitekturer er dette faktisk blevet højst sandsynligt på en normal daglig arbejdsbyrde.
-
ROW-replikeringsformatet giver løsninger, som SBR'en mangler. Når du bruger rækkebaseret replikering (RBR) logningsformat, skriver kilden hændelser til den binære log, der angiver, hvordan individuelle tabelrækker ændres. Replikering fra kilde til replika fungerer ved at kopiere hændelser, der repræsenterer ændringerne i tabelrækkerne til replikaen. Det betyder, at flere data kan genereres, hvilket påvirker diskpladsen i replikaen og påvirker netværkstrafikken og disk I/O. Overvej, om en sætning ændrer mange rækker, lad os sige med en UPDATE-sætning, RBR skriver flere data til den binære log, selv for sætninger, der rulles tilbage. Det kan også tage længere tid at køre øjebliksbilleder. Samtidighedsproblemer kan komme i spil på grund af de låsetider, der er nødvendige for at skrive store bidder af data ind i den binære log.
-
Så er der en metode imellem disse to; mixed-mode replikering. Denne type replikering vil altid replikere sætninger, undtagen når forespørgslen indeholder UUID()-funktionen, triggere, lagrede procedurer, UDF'er og et par andre undtagelser. Mixed-mode løser ikke problemet med datadrift og bør sammen med sætningsbaseret replikering undgås.
Planlægger du en Multi-Master-opsætning?
Cirkulær replikering (også kendt som ringtopologi) er en kendt og almindelig opsætning til MySQL-replikering. Det bruges til at køre en multi-master opsætning (se billedet nedenfor) og er ofte nødvendig, hvis du har et multi-datacenter miljø. Da applikationen ikke kan vente på, at masteren i det andet datacenter anerkender skrivningerne, foretrækkes en lokal master. Normalt bruges den automatiske inkrementoffset til at forhindre datasammenstød mellem masterne. At lade to mestre udføre skrivninger til hinanden på denne måde er en bredt accepteret løsning.
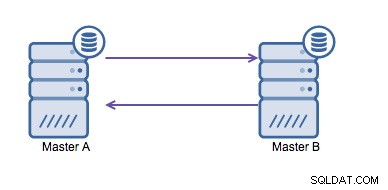
Men hvis du har brug for at skrive i flere datacentre ind i den samme database , ender du med flere mastere, der skal skrive deres data til hinanden. Før MySQL 5.7.6 var der ingen metode til at lave en mesh-type replikering, så alternativet ville være at bruge en cirkulær ringreplikation i stedet for.
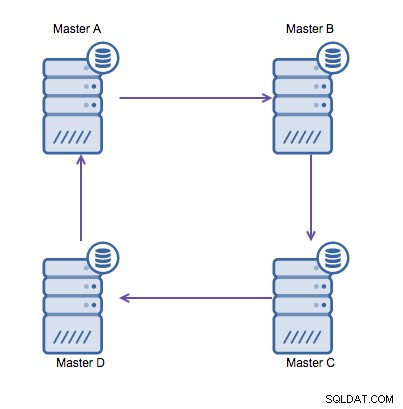
Ringeplikering i MySQL er problematisk af følgende årsager:latency, høj tilgængelighed , og datadrift. At skrive nogle data til server A ville tage tre hop at ende på server D (via server B og C). Da (traditionel) MySQL-replikering er enkelt-trådet, kan enhver langvarig forespørgsel i replikationen stoppe hele ringen. Desuden, hvis nogen af serverne ville gå ned, ville ringen blive brudt, og i øjeblikket kan ingen failover-software reparere ringstrukturer. Så kan datadrift forekomme, når data skrives til server A og ændres samtidigt på server C eller D.
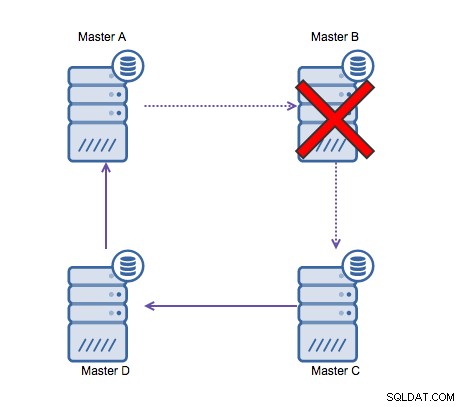
Generelt passer cirkulær replikering ikke godt til MySQL og bør undgås for enhver pris. Da det blev designet med det i tankerne, ville Galera Cluster være et godt alternativ til multi-datacenterskrivninger.
Standsering af din replikering med store opdateringer
Forskellige husholdnings-batchjobs udfører ofte forskellige opgaver, lige fra at rydde op i gamle data til at beregne gennemsnit af 'likes' hentet fra en anden kilde. Dette betyder, at et job vil skabe en masse databaseaktivitet med faste intervaller og højst sandsynligt skrive en masse data tilbage til databasen. Dette betyder naturligvis, at aktiviteten i replikationsstrømmen vil stige lige meget.
Udsagnsbaseret replikering vil replikere de nøjagtige forespørgsler, der bruges i batch-jobbene, så hvis forespørgslen tog en halv time at behandle på masteren, ville slavetråden blive stoppet i mindst den samme mængde tid. Dette betyder, at ingen andre data kan replikere, og slaveknuderne vil begynde at halte bagefter masteren. Hvis dette overskrider tærsklen for dit failover-værktøj eller proxy, kan det tabe disse slaveknuder fra de tilgængelige servere i klyngen. Hvis du bruger sætningsbaseret replikering, kan du forhindre dette ved at knuse dataene til dit job i mindre batches.
Nu tror du måske, at rækkebaseret replikering ikke er påvirket af dette, da det vil replikere rækkeoplysningerne i stedet for forespørgslen. Dette er delvist sandt, da replikeringen for DDL-ændringer vender tilbage til et sætningsbaseret format. Også et stort antal CRUD-operationer (Create, Read, Update, Delete) vil påvirke replikeringsstrømmen. I de fleste tilfælde er dette stadig en enkelt-trådsoperation, og derfor vil hver transaktion vente på, at den forrige afspilles igen via replikering. Dette betyder, at hvis du har høj samtidighed på masteren, kan slaven gå i stå på grund af overbelastning af transaktioner under replikering.
For at omgå dette tilbyder både MariaDB og MySQL parallel replikering. Implementeringen kan variere fra leverandør og version. MySQL 5.6 tilbyder parallel replikering, så længe forespørgslerne er adskilt af skemaet. MariaDB 10.0 og MySQL 5.7 kan begge håndtere parallel replikering på tværs af skemaer, men har andre grænser. Udførelse af forespørgsler via parallelle slavetråde kan fremskynde din replikeringsstrøm, hvis du skriver tungt. Ellers ville det være bedre at holde sig til den traditionelle enkelttrådsreplikering.
Håndtering af dine skemaændringer eller DDL'er
Siden udgivelsen af 5.7 er administrationen af skemaændringen eller DDL-ændringen (Data Definition Language) i MySQL blevet forbedret meget. Indtil MySQL 8.0 er de understøttede DDL-ændringsalgoritmer COPY og INPLACE.
-
KOPI:Denne algoritme opretter en ny midlertidig tabel med det ændrede skema. Når den har migreret dataene fuldstændigt til den nye midlertidige tabel, skifter den og dropper den gamle tabel.
-
INPLACE:Denne algoritme udfører operationer på plads til den originale tabel og undgår tabelkopiering og genopbygning, når det er muligt.
-
ØJEBLIKKELIG:Denne algoritme er blevet introduceret siden MySQL 8.0, men har stadig begrænsninger.
I MySQL 8.0 blev algoritmen INSTANT introduceret, der foretager øjeblikkelige og på stedet tabelændringer til kolonnetilføjelse og tillader samtidig DML med forbedret reaktionsevne og tilgængelighed i travle produktionsmiljøer. Dette hjælper med at undgå store forsinkelser og stall i replikaen, som normalt var store problemer i applikationsperspektivet, hvilket medførte, at forældede data blev hentet, da læsningerne i slaven endnu ikke er blevet opdateret på grund af forsinkelse.
Selv om det er en lovende forbedring, er der stadig begrænsninger med dem, og nogle gange er det ikke muligt at anvende disse INSTANT- og INPLACE-algoritmer. For eksempel, for INSTANT og INPLACE algoritmer, er ændring af en kolonnes datatype også en sædvanlig DBA-opgave, især i applikationsudviklingsperspektivet på grund af dataændring. Disse lejligheder er uundgåelige; Derfor kan du ikke fortsætte med COPY-algoritmen, da denne låser tabellen og forårsager forsinkelser i slaven. Det påvirker også den primære/master-server under denne udførelse, da det hober sig op af indgående transaktioner, der også refererer til den berørte tabel. Du kan ikke udføre en direkte ALTER eller skemaændring på en travl server, da dette ledsager nedetid eller muligvis ødelægger din database, hvis du mister tålmodigheden, især hvis måltabellen er enorm.
Det er rigtigt, at det altid er en udfordrende opgave at udføre skemaændringer på en kørende produktionsopsætning. En ofte brugt løsning er først at anvende skemaændringen på slaveknuderne. Dette fungerer fint til sætningsbaseret replikering, men dette kan kun fungere op til en vis grad for rækkebaseret replikering. Rækkebaseret replikering tillader ekstra kolonner at eksistere i slutningen af tabellen, så så længe den kan skrive de første kolonner, vil det være fint. Først skal du anvende ændringen på alle slaver, derefter failover på en af slaverne og derefter anvende ændringen på masteren og vedhæfte den som en slave. Hvis din ændring involverer indsættelse af en kolonne i midten eller fjernelse af en kolonne, vil dette fungere med rækkebaseret replikering.
Der er tilgængelige værktøjer, der kan udføre online skemaændringer mere pålideligt. Percona Online Schema Change (så kendt som pt-osc) og gh-ost af Schlomi Noach bruges almindeligvis af DBA'er. Disse værktøjer håndterer skemaændringer effektivt ved at gruppere de berørte rækker i bidder, og disse bidder kan konfigureres i overensstemmelse hermed afhængigt af, hvor mange du vil gruppere.
Hvis du skal hoppe med pt-osc, vil dette værktøj skabe en skyggetabel med den nye tabelstruktur, indsætte nye data via triggere og udfylde data i baggrunden. Når den er færdig med at oprette den nye tabel, vil den simpelthen bytte den gamle ud med den nye tabel i en transaktion. Dette virker ikke i alle tilfælde, især hvis din eksisterende tabel allerede har triggere.
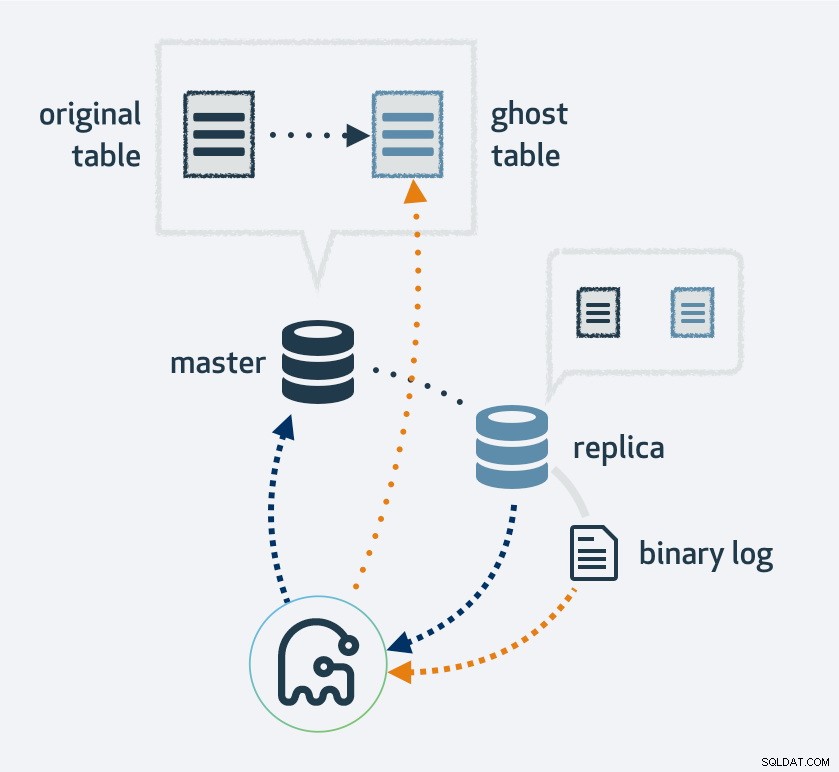
Brug af gh-ost vil først lave en kopi af dit eksisterende tabellayout, ændre tabellen til det nye layout, og tilslut derefter processen som en MySQL-replika. Den vil bruge replikeringsstrømmen til at finde nye rækker, der er blevet indsat i den originale tabel, og udfylder samtidig tabellen. Når den er færdig med at udfylde, skifter den originale og den nye tabel. Naturligvis vil alle operationer til den nye tabel ende i replikeringsstrømmen; således, på hver replika, sker migreringen samtidigt.
Hukommelsestabeller og replikering
Mens vi er om emnet DDL'er, er et almindeligt problem oprettelsen af hukommelsestabeller. Hukommelsestabeller er ikke-vedvarende tabeller, deres tabelstruktur forbliver, men de mister deres data efter en genstart af MySQL. Når du opretter en ny hukommelsestabel på både en master og en slave, vil de have en tom tabel, hvilket vil fungere helt fint. Når en af dem er genstartet, vil tabellen blive tømt, og der vil opstå replikeringsfejl.
Rækkebaseret replikering vil bryde, når dataene i slavenoden returnerer forskellige resultater, og sætningsbaseret replikering vil bryde, når den forsøger at indsætte data, der allerede eksisterer. For hukommelsestabeller er dette en hyppig replikeringsafbryder. Rettelsen er nem:Lav en ny kopi af dataene, skift motoren til InnoDB, og den skulle nu være replikeringssikker.
Indstilling af read_only={True|1}
Dette er selvfølgelig et muligt tilfælde, når du bruger en ringtopologi, og vi fraråder brugen af ringtopologi, hvis det er muligt. Vi har tidligere beskrevet, at ikke at have de samme data i slaveknuderne kan bryde replikering. Ofte er dette forårsaget af, at noget (eller nogen) ændrer dataene på slaveknuden, men ikke på masternoden. Når masternodens data bliver ændret, vil dette blive replikeret til slaven, hvor den ikke kan anvende ændringen, og dette får replikationen til at bryde. Dette kan også føre til datakorruption på klyngeniveau, især hvis slaven er blevet forfremmet eller har fejlet på grund af et nedbrud. Det kan være en katastrofe.
Nem forebyggelse af dette er at sørge for, at read_only og super_read_only (kun på> 5.6) er indstillet til ON eller 1. Du har måske forstået, hvordan disse to variabler adskiller sig, og hvordan det påvirker, hvis du deaktiverer eller aktiverer dem. Med super_read_only (siden MySQL 5.7.8) deaktiveret, kan root-brugeren forhindre ændringer i målet eller replikaen. Så når begge er deaktiveret, vil dette ikke tillade nogen at foretage ændringer i dataene, undtagen replikeringen. De fleste failover-administratorer, såsom ClusterControl, indstiller dette flag automatisk for at forhindre brugere i at skrive til den brugte master under failover. Nogle af dem beholder endda dette efter failover.
Aktivering af GTID
I MySQL-replikering er det vigtigt at starte slaven fra den korrekte position i de binære logfiler. At opnå denne position kan gøres, når du laver en sikkerhedskopi (xtrabackup og mysqldump understøtter dette), eller når du er stoppet med at slave på en node, som du laver en kopi af. At starte replikering med kommandoen CHANGE MASTER TO ville se sådan ud:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Start af replikering på det forkerte sted kan have katastrofale konsekvenser:data kan være dobbeltskrevet eller ikke opdateret. Dette forårsager datadrift mellem master- og slaveknuden.
Også, at mislykkes over en master til en slave involverer at finde den korrekte position og ændre masteren til den passende vært. MySQL beholder ikke de binære logfiler og positioner fra sin master, men opretter i stedet sine egne binære logfiler og positioner. Dette kan blive et alvorligt problem for at genjustere en slaveknude til den nye master. Den nøjagtige position af masteren ved failover skal findes på den nye master, og så kan alle slaver justeres igen.
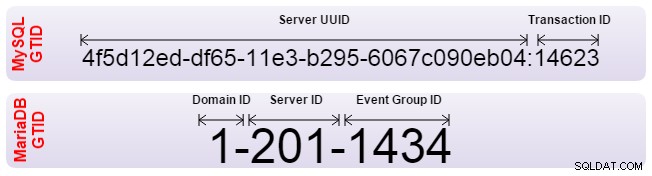
Både Oracle MySQL og MariaDB har implementeret Global Transaction Identifier (GTID) til at løse dette problem. GTID'er tillader automatisk justering af slaver, og serveren finder selv ud af, hvad den korrekte position er. Begge har dog implementeret GTID forskelligt og er derfor inkompatible. Hvis du har brug for at konfigurere replikering fra den ene til den anden, skal replikeringen konfigureres med traditionel binær logpositionering. Din failover-software skal også gøres opmærksom på ikke at bruge GTID'er.
Crash-Safe Slave
Crash sikker betyder, at selvom en slave MySQL/OS går ned, kan du gendanne slaven og fortsætte replikering uden at gendanne MySQL-databaser på slaven. For at få nedbrudssikkert slave til at fungere, skal du kun bruge InnoDB-lagermotoren, og i 5.6 skal du indstille relay_log_info_repository=TABLE og relay_log_recovery=1.
Konklusion
Øvelse gør virkelig mester, men uden ordentlig træning og viden om disse vitale teknikker kan det være besværligt eller føre til en katastrofe. Disse fremgangsmåder overholdes almindeligvis af eksperter i MySQL og tilpasses af store industrier som en del af deres daglige rutinearbejde, når de administrerer MySQL-replikeringen i produktionsdatabaseserverne.
Hvis du gerne vil læse mere om MySQL-replikering, så tjek denne vejledning om MySQL-replikering for høj tilgængelighed.
For flere opdateringer om databasestyringsløsninger og bedste praksis for dine open source-baserede databaser, følg os på Twitter og LinkedIn og abonner på vores nyhedsbrev.