Python og SQL er to af de vigtigste sprog for dataanalytikere.
I denne artikel vil jeg lede dig gennem alt, hvad du behøver at vide for at forbinde Python og SQL.
Du lærer, hvordan du trækker data fra relationelle databaser direkte ind i dine maskinlæringspipelines, gemmer data fra din Python-applikation i din egen database eller hvilken som helst anden use case, du måtte finde på.
Sammen dækker vi:
- Hvorfor lære at bruge Python og SQL sammen?
- Sådan opsætter du dit Python-miljø og MySQL-server
- Opretter forbindelse til MySQL Server i Python
- Oprettelse af en ny database
- Oprettelse af tabeller og tabelrelationer
- Population af tabeller med data
- Læser data
- Opdatering af poster
- Sletning af poster
- Oprettelse af poster fra Python-lister
- Oprettelse af genbrugelige funktioner for at gøre alt dette for os i fremtiden
Det er en masse meget nyttige og meget seje ting. Lad os komme ind i det!
En hurtig note før vi starter:Der er en Jupyter Notebook, der indeholder al koden, der bruges i denne tutorial, tilgængelig i dette GitHub-lager. Det anbefales stærkt at kode sammen!
Databasen og SQL-koden, der bruges her, er alt sammen fra min tidligere Introduktion til SQL-serie, som blev lagt ud på Towards Data Science (kontakt mig, hvis du har problemer med at se artiklerne, og jeg kan sende dig et link for at se dem gratis).
Hvis du ikke er bekendt med SQL og koncepterne bag relationelle databaser, vil jeg henvise dig til den serie (plus der selvfølgelig er en enorm mængde af gode ting tilgængeligt her på freeCodeCamp!)
Hvorfor Python med SQL?
For dataanalytikere og dataforskere har Python mange fordele. Et stort udvalg af open source-biblioteker gør det til et utroligt nyttigt værktøj for enhver dataanalytiker.
Vi har pandaer, NumPy og Vaex til dataanalyse, Matplotlib, seaborn og Bokeh til visualisering og TensorFlow, scikit-learn og PyTorch til maskinlæringsapplikationer (plus mange, mange flere).
Med sin (relativt) nemme indlæringskurve og alsidighed er det ikke underligt, at Python er et af de hurtigst voksende programmeringssprog derude.
Så hvis vi bruger Python til dataanalyse, er det værd at spørge - hvor kommer alle disse data fra?
Selvom der er et stort udvalg af kilder til datasæt, vil data i mange tilfælde - især i virksomhedsvirksomheder - blive lagret i en relationel database. Relationelle databaser er en ekstremt effektiv, kraftfuld og udbredt måde at oprette, læse, opdatere og slette data af enhver art.
De mest udbredte relationelle databasestyringssystemer (RDBMS'er) - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - bruger alle Structured Query Language (SQL) til at få adgang til og foretage ændringer i dataene.
Bemærk, at hver RDBMS bruger en lidt anderledes smag af SQL, så SQL-kode, der er skrevet til en, vil normalt ikke fungere i en anden uden (normalt forholdsvis små) ændringer. Men koncepterne, strukturerne og operationerne er stort set identiske.
Dette betyder for en arbejdende dataanalytiker, at en stærk forståelse af SQL er enormt vigtig. At vide, hvordan du bruger Python og SQL sammen, vil give dig endnu flere fordele, når det kommer til at arbejde med dine data.
Resten af denne artikel vil blive viet til at vise dig præcis, hvordan vi kan gøre det.
Kom godt i gang
Krav og installation
For at kode sammen med denne tutorial skal du have dit eget Python-miljø opsat.
Jeg bruger Anaconda, men der er mange måder at gøre dette på. Bare google "hvordan du installerer Python", hvis du har brug for yderligere hjælp. Du kan også bruge Binder til at kode sammen med den tilhørende Jupyter Notebook.
Vi vil bruge MySQL Community Server, da den er gratis og meget brugt i branchen. Hvis du bruger Windows, hjælper denne vejledning dig med opsætningen. Her er også vejledninger til Mac- og Linux-brugere (selvom det kan variere alt efter Linux-distribution).
Når du har sat dem op, bliver vi nødt til at få dem til at kommunikere med hinanden.
Til det skal vi installere MySQL Connector Python-biblioteket. For at gøre dette, følg instruktionerne, eller brug bare pip:
pip install mysql-connector-pythonVi kommer også til at bruge pandaer, så sørg for at du også har det installeret.
pip install pandasImport af biblioteker
Som med ethvert projekt i Python er det allerførste, vi vil gøre, at importere vores biblioteker.
Det er bedste praksis at importere alle de biblioteker, vi skal bruge i begyndelsen af projektet, så folk, der læser eller gennemgår vores kode, ved nogenlunde, hvad der kommer op, så der ikke er nogen overraskelser.
Til denne vejledning skal vi kun bruge to biblioteker - MySQL Connector og pandaer.
import mysql.connector
from mysql.connector import Error
import pandas as pdVi importerer fejlfunktionen separat, så vi har nem adgang til den for vores funktioner.
Opretter forbindelse til MySQL-server
På dette tidspunkt skulle vi have MySQL Community Server sat op på vores system. Nu skal vi skrive noget kode i Python, der lader os etablere en forbindelse til den server.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionAt oprette en genbrugelig funktion til kode som denne er bedste praksis, så vi kan bruge denne igen og igen med minimal indsats. Når dette er skrevet, kan du også genbruge det i alle dine projekter i fremtiden, så i fremtiden vil du være taknemmelig!
Lad os gennemgå dette linje for linje, så vi forstår, hvad der sker her:
Den første linje er, at vi navngiver funktionen (create_server_connection) og navngiver de argumenter, som den funktion vil tage (værtsnavn, brugernavn og brugeradgangskode).
Den næste linje lukker alle eksisterende forbindelser, så serveren ikke bliver forvekslet med flere åbne forbindelser.
Dernæst bruger vi en Python try-except-blok til at håndtere eventuelle fejl. Den første del forsøger at oprette en forbindelse til serveren ved hjælp af mysql.connector.connect() metoden ved at bruge de detaljer, der er angivet af brugeren i argumenterne. Hvis dette virker, udskriver funktionen en glad lille succesbesked.
Den undtagen del af blokken udskriver den fejl, som MySQL Server returnerer, i det uheldige tilfælde, at der er en fejl.
Til sidst, hvis forbindelsen lykkes, returnerer funktionen et forbindelsesobjekt.
Det bruger vi i praksis ved at tildele funktionen output til en variabel, som så bliver vores forbindelsesobjekt. Vi kan derefter anvende andre metoder (såsom markør) på det og skabe andre nyttige objekter.
connection = create_server_connection("localhost", "root", pw)Dette skulle give en succesmeddelelse:

Oprettelse af en ny database
Nu hvor vi har etableret en forbindelse, er vores næste skridt at oprette en ny database på vores server.
I denne tutorial vil vi kun gøre dette én gang, men igen vil vi skrive dette som en genanvendelig funktion, så vi har en dejlig nyttig funktion, vi kan genbruge til fremtidige projekter.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Denne funktion tager to argumenter, forbindelse (vores forbindelsesobjekt) og forespørgsel (en SQL-forespørgsel, som vi vil skrive i næste trin). Den udfører forespørgslen på serveren via forbindelsen.
Vi bruger markørmetoden på vores forbindelsesobjekt til at skabe et markørobjekt (MySQL Connector bruger et objektorienteret programmeringsparadigme, så der er masser af objekter, der arver egenskaber fra overordnede objekter).
Dette markørobjekt har metoder såsom execute, executemany (som vi vil bruge i denne tutorial) sammen med flere andre nyttige metoder.
Hvis det hjælper, kan vi tænke på, at markørobjektet giver os adgang til den blinkende markør i et MySQL Server-terminalvindue.
Dernæst definerer vi en forespørgsel for at oprette databasen og kalder funktionen:

Alle SQL-forespørgsler, der bruges i denne øvelse, er forklaret i min Introduktion til SQL tutorial-serie, og den fulde kode kan findes i den tilknyttede Jupyter Notebook i dette GitHub-lager, så jeg vil ikke give forklaringer på, hvad SQL-koden gør i dette tutorial.
Dette er dog måske den enkleste SQL-forespørgsel. Hvis du kan læse engelsk, kan du sikkert finde ud af, hvad det gør!
At køre create_database-funktionen med argumenterne som ovenfor resulterer i, at en database kaldet 'school' bliver oprettet på vores server.
Hvorfor hedder vores database 'skole'? Måske ville det nu være et godt tidspunkt at se mere detaljeret på præcis, hvad vi skal implementere i denne øvelse.
Vores database
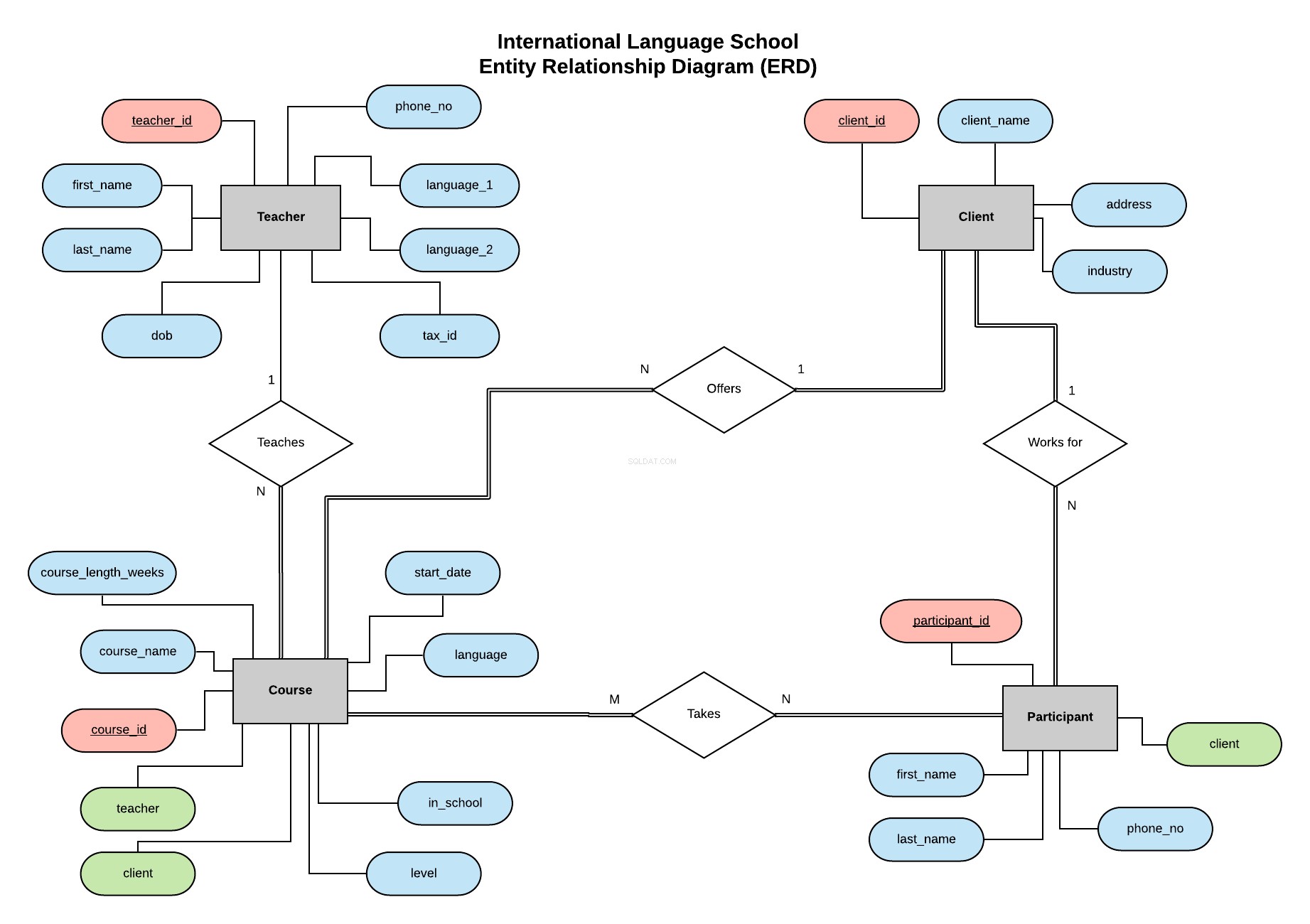
Efter eksemplet i min tidligere serie skal vi implementere databasen for International Language School - en fiktiv sprogtræningsskole, som tilbyder professionelle sprogundervisning til erhvervskunder.
Dette Entity Relationship Diagram (ERD) opstiller vores enheder (lærer, klient, kursus og deltager) og definerer relationerne mellem dem.
Alle oplysninger om, hvad en ERD er, og hvad du skal overveje, når du opretter en og designer en database, kan findes i denne artikel.
Den rå SQL-kode, databasekrav og data, der skal ind i databasen, er alle indeholdt i dette GitHub-lager, men du vil også se det hele, mens vi også gennemgår denne tutorial.
Opretter forbindelse til databasen
Nu hvor vi har oprettet en database i MySQL Server, kan vi ændre vores create_server_connection funktion til at oprette forbindelse direkte til denne database.
Bemærk, at det er muligt - faktisk almindeligt - at have flere databaser på én MySQL-server, så vi vil altid og automatisk oprette forbindelse til den database, vi er interesserede i.
Vi kan gøre det sådan:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionDette er nøjagtig den samme funktion, men nu tager vi endnu et argument - databasenavnet - og sender det som et argument til connect()-metoden.
Oprettelse af en forespørgselsudførelsesfunktion
Den sidste funktion, vi skal oprette (indtil videre), er en ekstremt vigtig - en forespørgselseksekveringsfunktion. Dette vil tage vores SQL-forespørgsler, gemt i Python som strenge, og sende dem til cursor.execute()-metoden for at udføre dem på serveren.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Denne funktion er nøjagtig den samme som vores create_database-funktion fra tidligere, bortset fra at den bruger metoden connection.commit() for at sikre, at kommandoerne, der er beskrevet i vores SQL-forespørgsler, er implementeret.
Dette bliver vores arbejdshestfunktion, som vi vil bruge (sammen med create_db_connection) til at oprette tabeller, etablere relationer mellem disse tabeller, udfylde tabellerne med data og opdatere og slette poster i vores database.
Hvis du er en SQL-ekspert, vil denne funktion lade dig udføre alle de komplekse kommandoer og forespørgsler, du måtte have liggende, direkte fra et Python-script. Dette kan være et meget effektivt værktøj til at administrere dine data.
Oprettelse af tabeller
Nu er vi klar til at begynde at køre SQL-kommandoer ind i vores server og begynde at bygge vores database. Det første, vi vil gøre, er at lave de nødvendige tabeller.
Lad os starte med vores lærertabel:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryFørst og fremmest tildeler vi vores SQL-kommando (forklaret i detaljer her) til en variabel med et passende navn.
I dette tilfælde bruger vi Pythons tredobbelte anførselstegn for strenge med flere linjer til at gemme vores SQL-forespørgsel, derefter fører vi den ind i vores execute_query-funktion for at implementere den.
Bemærk, at denne multi-line formatering udelukkende er til gavn for mennesker, der læser vores kode. Hverken SQL eller Python er ligeglade med, om SQL-kommandoen er spredt sådan ud. Så længe syntaksen er korrekt, vil begge sprog acceptere den.
Til gavn for mennesker, der vil læse din kode, (selvom det kun vil være fremtiden-dig!) er det meget nyttigt at gøre dette for at gøre koden mere læsbar og forståelig.
Det samme er tilfældet for KAPITALISERING af operatorer i SQL. Dette er en meget udbredt konvention, der anbefales kraftigt, men den faktiske software, der kører koden, er ufølsom over for store og små bogstaver og vil behandle 'CREATE TABLE teacher' og 'create table teacher' som identiske kommandoer.

At køre denne kode giver os vores succesbeskeder. Vi kan også bekræfte dette i MySQL Server Command Line Client:
Store! Lad os nu oprette de resterende tabeller.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Dette skaber de fire tabeller, der er nødvendige for vores fire enheder.
Nu vil vi definere relationerne mellem dem og oprette en tabel mere for at håndtere mange-til-mange forholdet mellem deltager- og kursustabellerne (se her for flere detaljer).
Det gør vi på nøjagtig samme måde:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Nu er vores tabeller oprettet sammen med de relevante begrænsninger, primærnøgle og fremmednøglerelationer.
Befolkning af tabellerne
Det næste trin er at tilføje nogle poster til tabellerne. Igen bruger vi execute_query til at føre vores eksisterende SQL-kommandoer ind i serveren. Lad os igen starte med lærertabellen.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Virker det? Vi kan tjekke igen i vores MySQL Command Line Client:
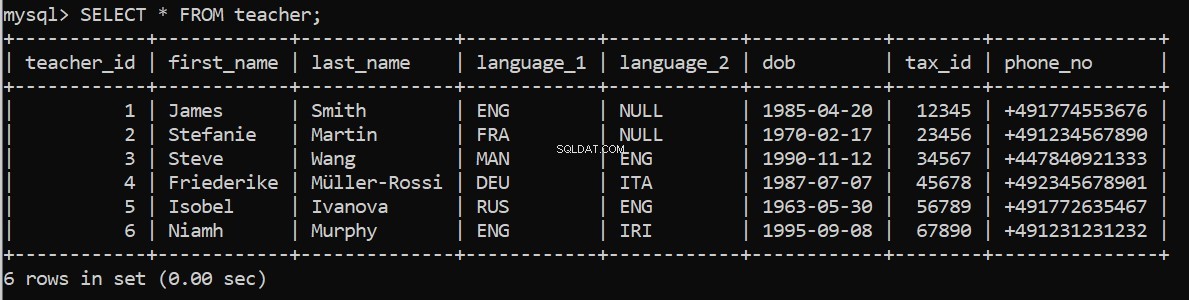
Nu for at udfylde de resterende tabeller.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Fantastiske! Nu har vi lavet en database komplet med relationer, begrænsninger og poster i MySQL, uden at bruge andet end Python-kommandoer.
Vi har gennemgået dette trin for trin for at holde det forståeligt. Men på dette tidspunkt kan du se, at det hele meget nemt kunne skrives ind i et Python-script og udføres i én kommando i terminalen. Kraftige ting.
Læse data
Nu har vi en funktionel database at arbejde med. Som dataanalytiker vil du sandsynligvis komme i kontakt med eksisterende databaser i de organisationer, hvor du arbejder. Det vil være meget nyttigt at vide, hvordan man trækker data ud af disse databaser, så det derefter kan føres ind i din python-datapipeline. Det er det, vi skal arbejde på næste gang.
Til dette har vi brug for en funktion mere, denne gang ved at bruge cursor.fetchall() i stedet for cursor.commit(). Med denne funktion læser vi data fra databasen og vil ikke foretage nogen ændringer.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Igen vil vi implementere dette på en meget lignende måde som execute_query. Lad os prøve det med en simpel forespørgsel for at se, hvordan det virker.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)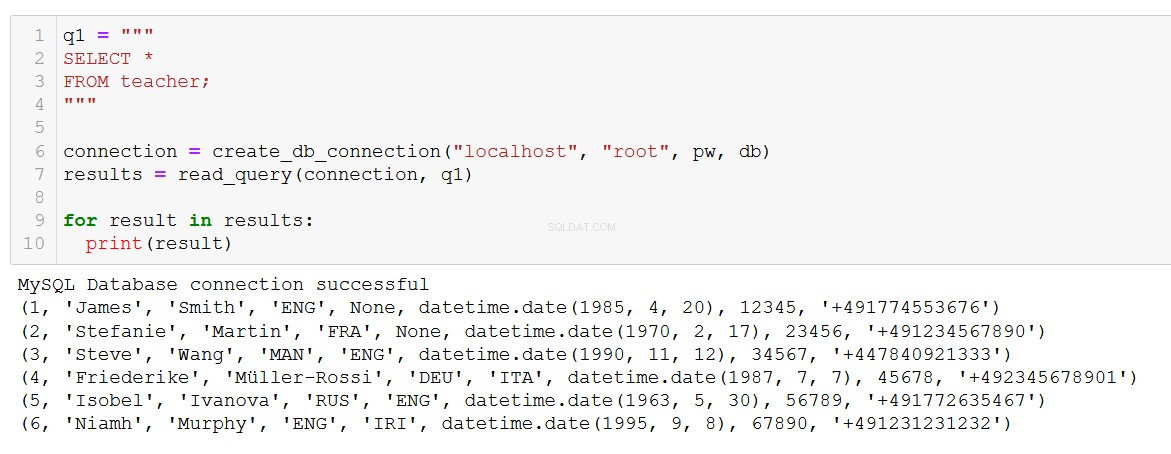
Præcis hvad vi forventer. Funktionen fungerer også med mere komplekse forespørgsler, såsom denne, der involverer et JOIN på kursus- og klienttabellerne.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)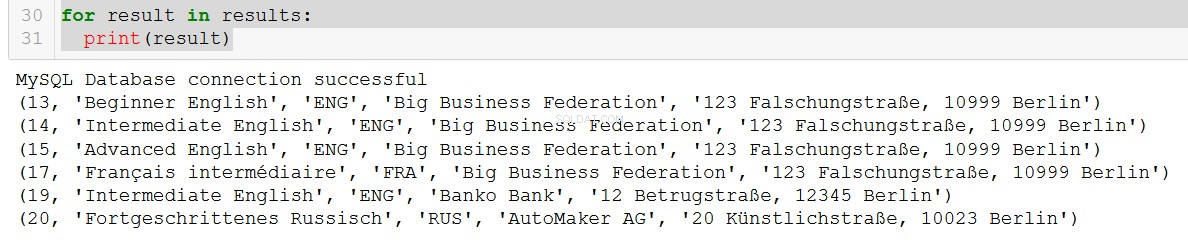
Meget fint.
For vores datapipelines og arbejdsgange i Python ønsker vi måske at få disse resultater i forskellige formater for at gøre dem mere nyttige eller klar til at vi kan manipulere.
Lad os gennemgå et par eksempler for at se, hvordan vi kan gøre det.
Formatere output til en liste
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formatere output til en liste over lister
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatering af output til en pandas DataFrame
For dataanalytikere, der bruger Python, er pandas vores smukke og betroede gamle ven. Det er meget enkelt at konvertere output fra vores database til en DataFrame, og derfra er mulighederne uendelige!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)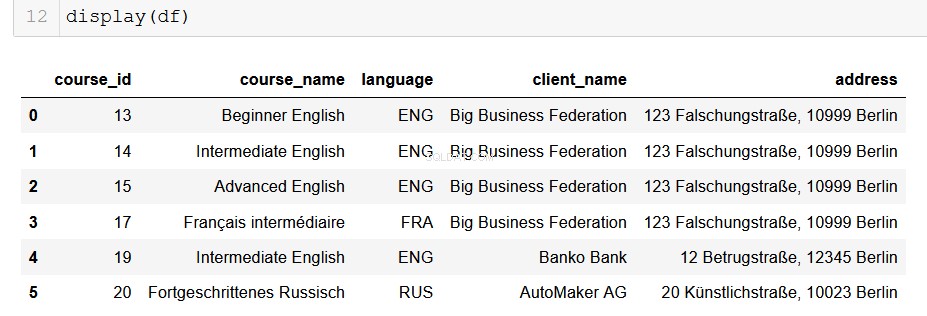
Forhåbentlig kan du se mulighederne udfolde sig foran dig her. Med blot et par linjer kode kan vi nemt udtrække alle de data, vi kan håndtere, fra de relationelle databaser, hvor den bor, og trække dem ind i vores avancerede dataanalysepipelines. Dette er virkelig nyttige ting.
Opdatering af poster
Når vi vedligeholder en database, bliver vi nogle gange nødt til at foretage ændringer i eksisterende poster. I dette afsnit skal vi se på, hvordan man gør det.
Lad os sige, at ILS er underrettet om, at en af dens eksisterende kunder, Big Business Federation, flytter kontorer til 23 Fingiertweg, 14534 Berlin. I dette tilfælde skal databaseadministratoren (det er os!) foretage nogle ændringer.
Heldigvis kan vi gøre dette med vores execute_query-funktion sammen med SQL UPDATE-sætningen.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Bemærk, at WHERE-sætningen er meget vigtig her. Hvis vi kører denne forespørgsel uden WHERE-klausulen, vil alle adresser for alle poster i vores klienttabel blive opdateret til 23 Fingiertweg. Det er meget ikke det, vi ønsker at gøre.
Bemærk også, at vi brugte "WHERE client_id =101" i UPDATE-forespørgslen. Det ville også have været muligt at bruge "WHERE client_name ='Big Business Federation'" eller "WHERE address ='123 Falschungstraße, 10999 Berlin'" eller endda "WHERE address LIKE '%Falschung%'".
Det vigtige er, at WHERE-sætningen giver os mulighed for entydigt at identificere den post (eller de poster), vi ønsker at opdatere.
Sletning af poster
Det er også muligt at bruge vores execute_query funktion til at slette poster ved at bruge DELETE.
Når du bruger SQL med relationelle databaser, skal vi være forsigtige med at bruge DELETE-operatoren. Dette er ikke Windows, der er ingen 'Er du sikker på, at du vil slette dette?' advarsel pop-up, og der er ingen genbrugsspand. Når vi har slettet noget, er det virkelig væk.
Når det er sagt, har vi virkelig brug for at slette ting nogle gange. Så lad os tage et kig på det ved at slette et kursus fra vores kursustabel.
Lad os først og fremmest minde os selv om, hvilke kurser vi har.
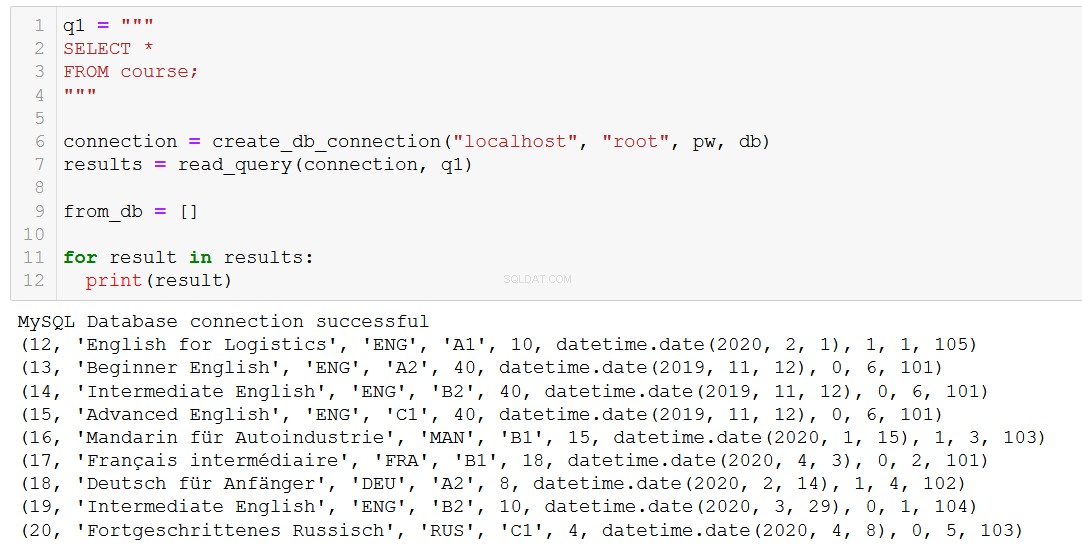
Lad os sige, at kursus 20, 'Fortgeschrittenes Russisch' (det er 'Avanceret russisk' for dig og mig), er ved at være slut, så vi er nødt til at fjerne det fra vores database.
På dette stadium vil du slet ikke blive overrasket over, hvordan vi gør dette - gem SQL-kommandoen som en streng, og indfør den derefter i vores workhorse execute_query-funktion.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Lad os tjekke for at bekræfte, at det havde den tilsigtede effekt:
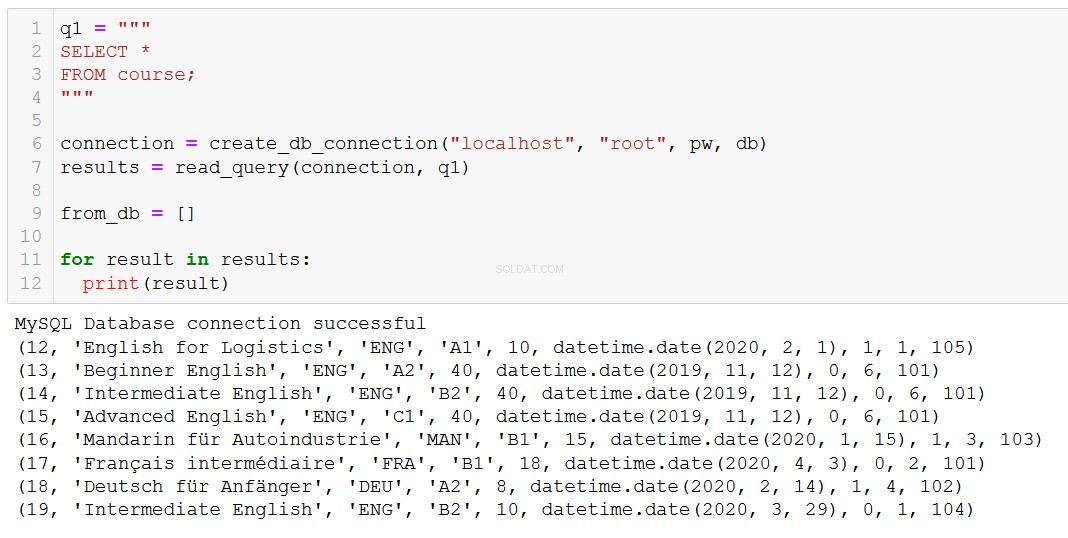
'Advanced Russian' er væk, som vi forventede.
Dette fungerer også med at slette hele kolonner ved hjælp af DROP COLUMN og hele tabeller ved hjælp af DROP TABLE-kommandoer, men vi vil ikke dække dem i denne øvelse.
Gå videre og eksperimenter med dem - det er lige meget, om du sletter en kolonne eller tabel fra en database for en fiktiv skole, og det er en god idé at blive fortrolig med disse kommandoer, før du går ind i et produktionsmiljø.
Åh CRUD
På dette tidspunkt er vi nu i stand til at fuldføre de fire store operationer for vedvarende datalagring.
Vi har lært, hvordan man:
- Opret - helt nye databaser, tabeller og poster
- Læs - udtræk data fra en database, og gem disse data i flere formater
- Opdater - foretag ændringer til eksisterende poster i databasen
- Slet - fjern poster, der ikke længere er nødvendige
Det er fantastisk nyttige ting at kunne gøre.
Inden vi afslutter tingene her, har vi endnu en meget praktisk færdighed at lære.
Oprettelse af poster fra lister
Vi så, da vi udfyldte vores tabeller, at vi kan bruge SQL INSERT-kommandoen i vores execute_query-funktion til at indsætte poster i vores database.
Da vi bruger Python til at manipulere vores SQL-database, ville det være nyttigt at kunne tage en Python-datastruktur (såsom en liste) og indsætte den direkte i vores database.
Dette kan være nyttigt, når vi for eksempel vil gemme logs over brugeraktivitet på en social medie-app, vi har skrevet i Python, eller input fra brugere til en Wiki, vi har bygget. Der er så mange anvendelsesmuligheder for dette, som du kan tænke dig.
Denne metode er også mere sikker, hvis vores database er åben for vores brugere på et hvilket som helst tidspunkt, da den hjælper med at forhindre SQL Injection-angreb, som kan beskadige eller endda ødelægge hele vores database.
For at gøre dette vil vi skrive en funktion ved hjælp af executemany()-metoden i stedet for den simplere execute()-metode, vi har brugt hidtil.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Nu har vi funktionen, vi skal definere en SQL-kommando ('sql') og en liste, der indeholder de værdier, vi ønsker at indtaste i databasen ('val'). Værdierne skal gemmes som en liste over tupler, hvilket er en ret almindelig måde at gemme data på i Python.
For at tilføje to nye lærere til databasen kan vi skrive noget kode som denne:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Bemærk her, at vi i 'sql'-koden bruger '%s' som pladsholder for vores værdi. Ligheden med '%s' pladsholderen for en streng i python er bare tilfældig (og ærlig talt meget forvirrende), vi ønsker at bruge '%s' til alle datatyper (strenge, ints, datoer osv.) med MySQL Python Stik.
Du kan se en række spørgsmål på Stackoverflow, hvor nogen er blevet forvirret og forsøgt at bruge '%d' pladsholdere til heltal, fordi de er vant til at gøre dette i Python. Dette virker ikke her - vi skal bruge en '%s' for hver kolonne, vi vil tilføje en værdi til.
Funktionen executemany tager derefter hver tuple i vores 'val'-liste og indsætter den relevante værdi for den kolonne i stedet for pladsholderen og udfører SQL-kommandoen for hver tuple indeholdt i listen.
Dette kan udføres for flere rækker af data, så længe de er formateret korrekt. I vores eksempel vil vi blot tilføje to nye lærere, til illustrative formål, men i princippet kan vi tilføje så mange, vi vil.
Lad os gå videre og udføre denne forespørgsel og tilføje lærerne til vores database.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)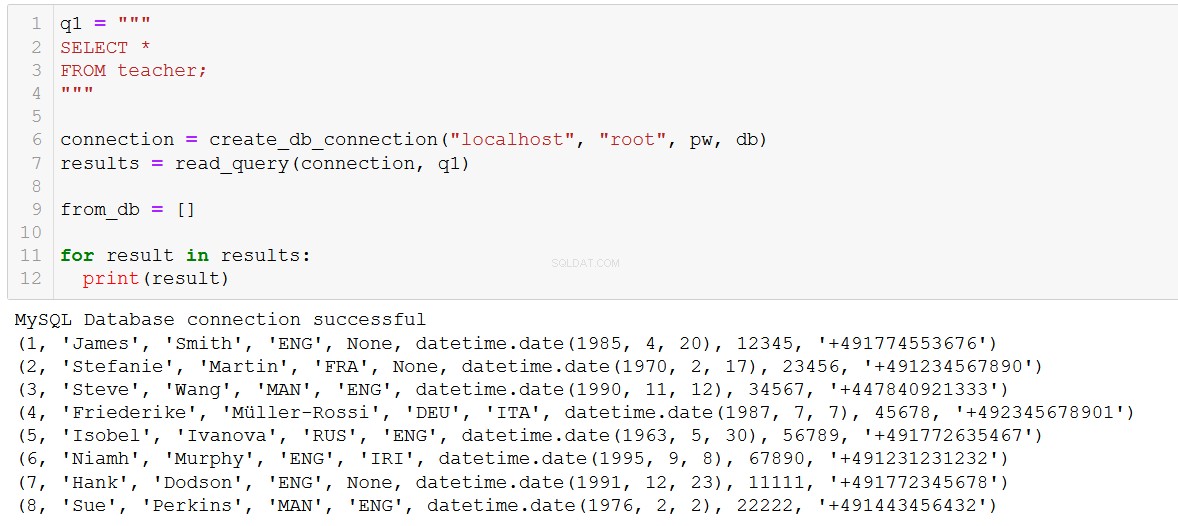
Velkommen til ILS, Hank og Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Konklusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!
