Opgraderinger er altid en hård og tidskrævende opgave. Først bør du teste din applikation i et testmiljø, så ideelt set bliver du nødt til at klone dit nuværende produktionsmiljø til dette. Derefter skal du lave en plan for at udføre opgraderingen, der afhængigt af virksomheden kan være med nul nedetid (eller næsten nul), eller endda planlægge et vedligeholdelsesvindue for at sikre, at hvis noget går galt, vil det påvirke så lidt som muligt.
Hvis du vil gøre alle disse ting manuelt, er der en stor chance for menneskelige fejl, og processen vil være langsom. I denne blog vil vi se, hvordan du automatiserer test til opgradering af dine MySQL-, MariaDB- eller Percona Server-databaser ved hjælp af ClusterControl.
Opgraderingstype
Der er to typer opgraderinger:Mindre opgraderinger og større opgraderinger.
Mindre opgraderinger
Den første, Mindre opgradering, er den mest almindelige og sikre opgradering, og i de fleste tilfælde udføres denne på plads. Da intet er 100 % sikkert, skal du altid have backups og replikeringsslaveknudepunkter, så i tilfælde af at noget går galt med opgraderingen, og du af en eller anden grund ikke kan rulle tilbage/nedgradere, kan du promovere en slaveknude, og dine systemer kan stadig arbejde uden afbrydelse.
Du kan udføre denne form for opgradering ved hjælp af ClusterControl. For dette skal du gå til ClusterControl -> Vælg Cluster -> Administrer -> Opgraderinger.
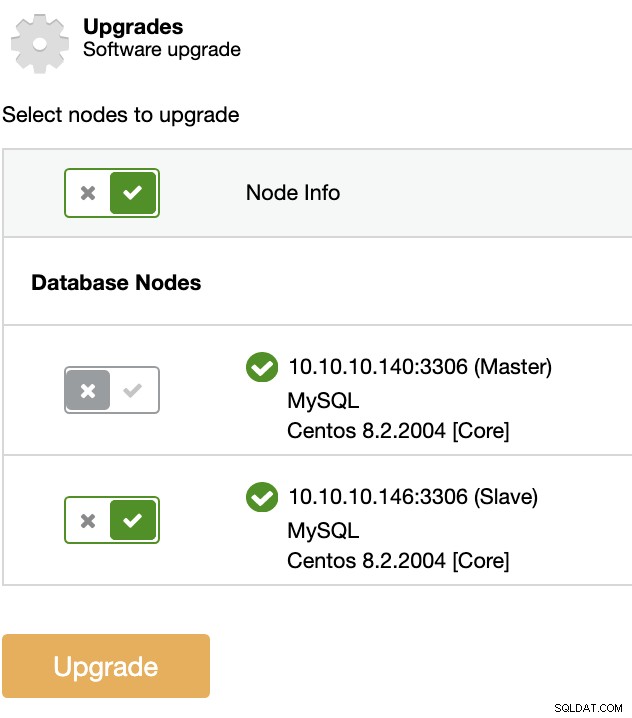
På hver valgt node vil opgraderingsproceduren:
-
Stopknude
-
Opgrader node
-
Startknude
Masternoden i en replikeringstopologi vil ikke blive opgraderet. For at opgradere Master skal en anden node forfremmes til at blive den nye Master først.
Større opgraderinger
For større opgraderinger anbefales det ikke at opgradere på stedet, da risikoen for, at noget går galt, er for høj til et produktionsmiljø. I stedet for dette kan du klone din nuværende databaseklynge og teste din applikation der, og når du er færdig, kan du genskabe den eller endda oprette en ny klynge i den nye version og skifte trafikken, når den er klar. Der er forskellige tilgange til disse opgraderinger. Du kan opgradere noderne en efter en eller oprette en anden klynge, der replikerer trafikken fra den nuværende, du kan også bruge belastningsbalancere til at forbedre High Availability og flere muligheder. Den bedste tilgang afhænger af nedetidstolerancen og Recovery Time Objective (RTO).
Du kan ikke udføre større opgraderinger med ClusterControl direkte, fordi, som vi nævnte, skal du teste alt først for at sikre dig, at opgraderingen er sikker, men du kan bruge forskellige ClusterControl-funktioner til at lave denne opgave lettere. Så lad os se nogle af disse funktioner.
Sikkerhedskopier
Sikkerhedskopier er et must før enhver opgradering. En god backuppolitik kan undgå store problemer for virksomheden. Så lad os se, hvordan ClusterControl kan automatisere dette.
Oprettelse af en sikkerhedskopi
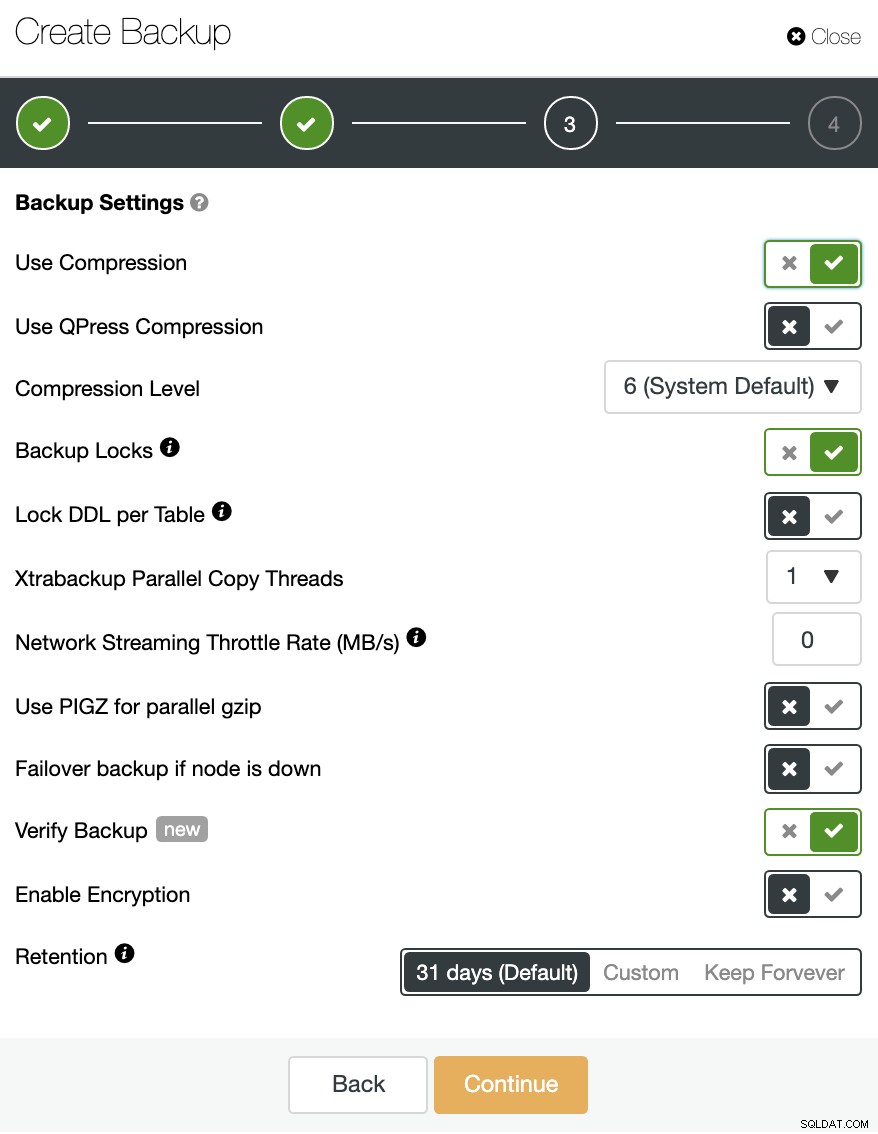
Gå til ClusterControl -> Vælg Cluster -> Backup -> Create Backup.
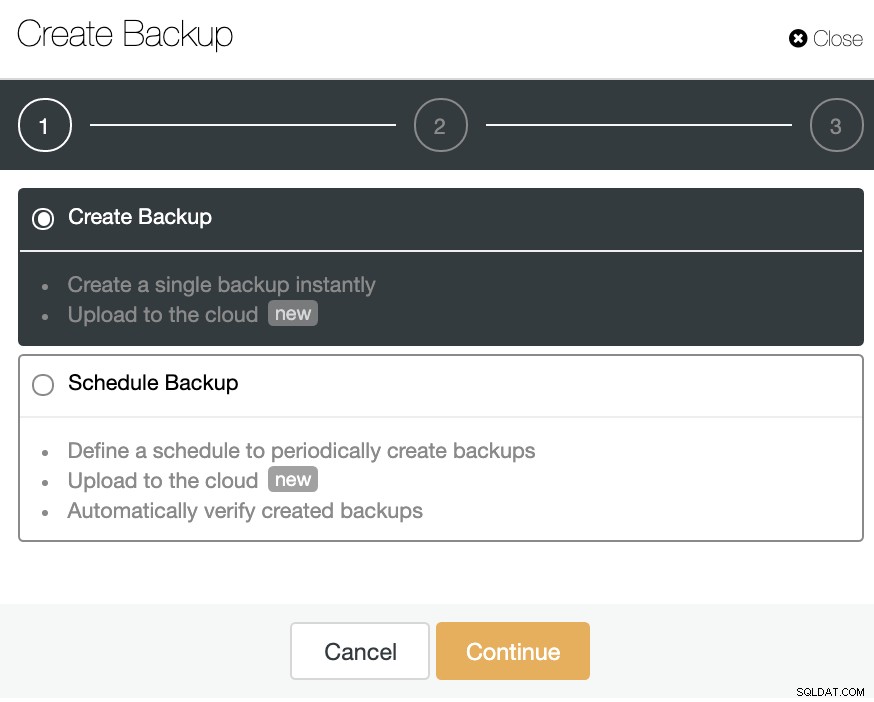
Du kan oprette en ny sikkerhedskopi eller konfigurere en planlagt.
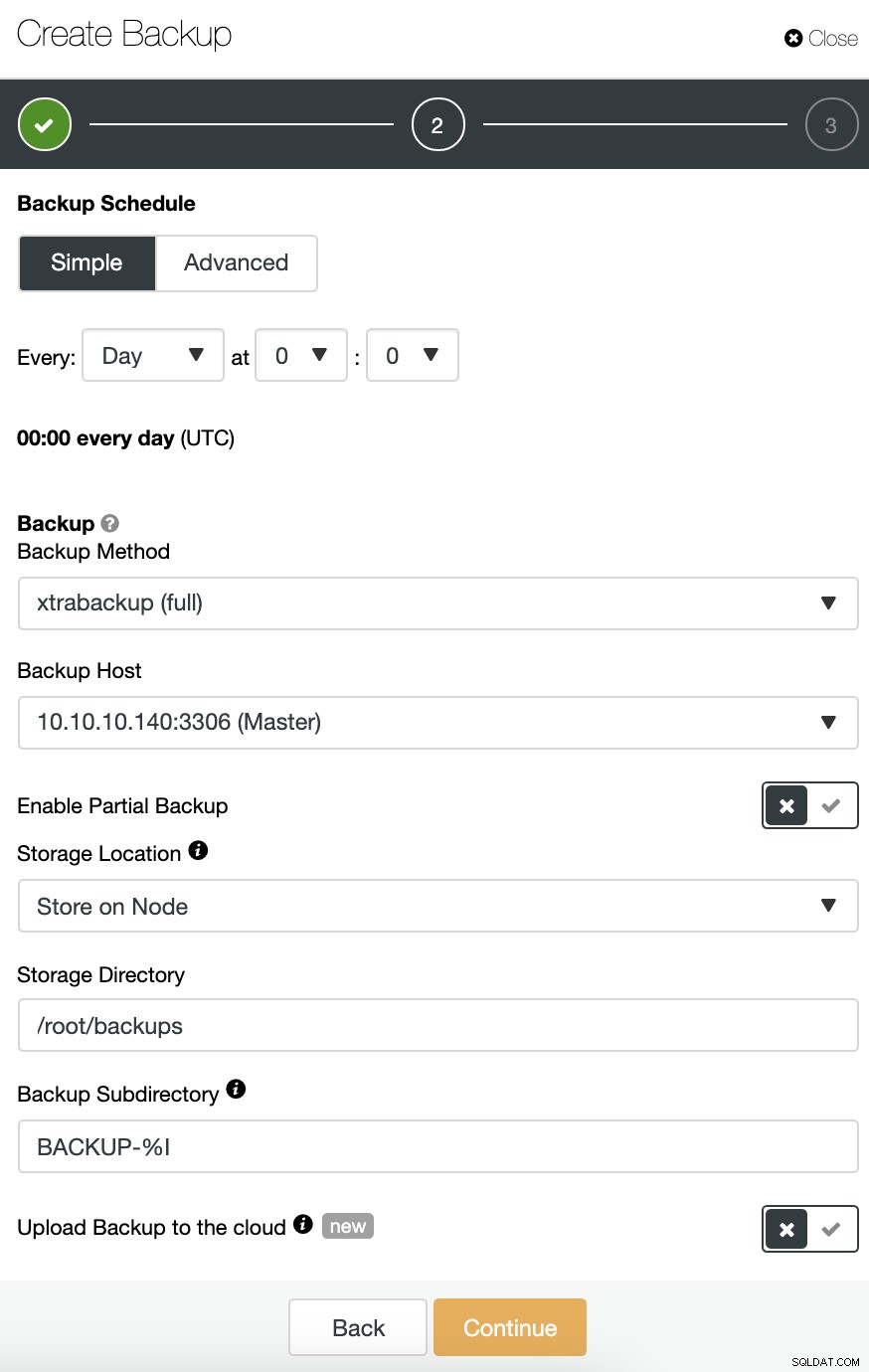
Du kan vælge forskellige sikkerhedskopieringsmetoder afhængigt af databaseteknologien, og i samme afsnit kan du vælge den server, som du vil tage backup fra, hvor du vil gemme sikkerhedskopien, og hvis du vil uploade sikkerhedskopien til skyen (AWS, Azure eller Google Cloud) i samme job.
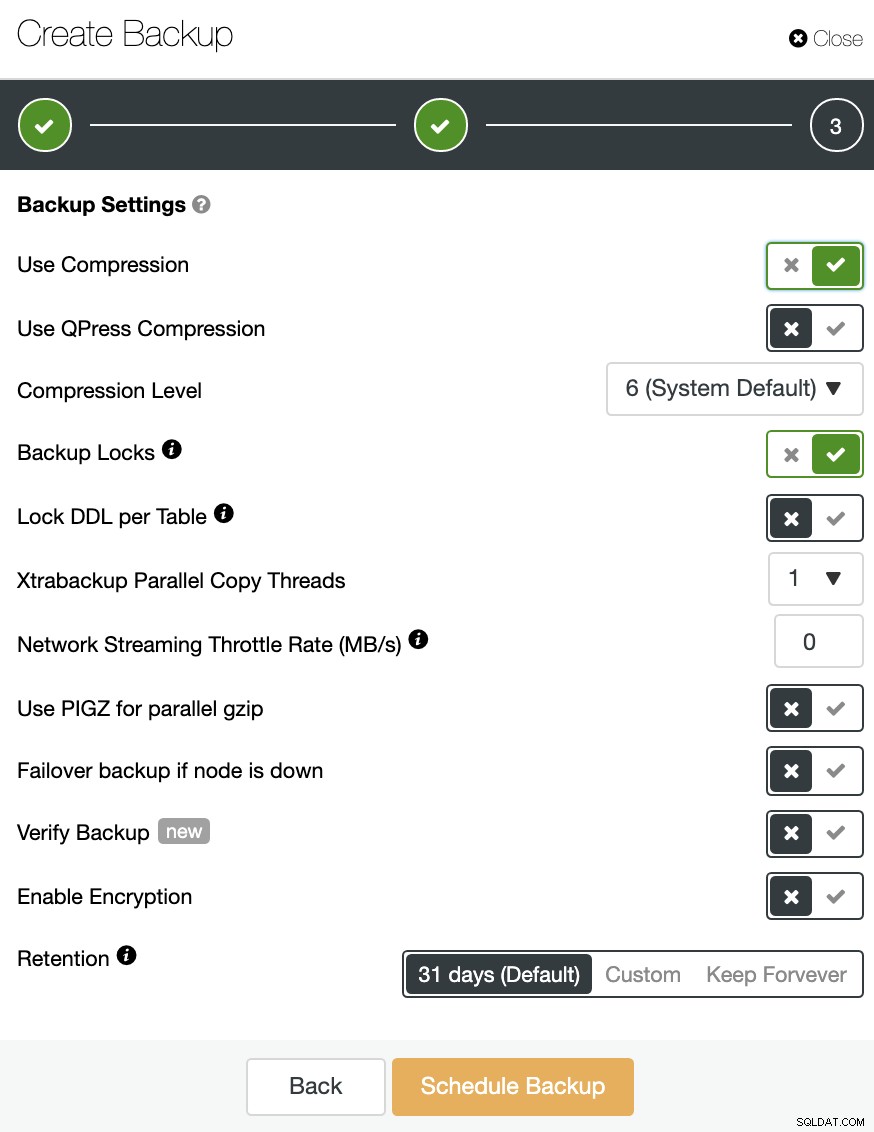
Du kan også komprimere og kryptere din sikkerhedskopi og angive opbevaringsperioden blandt andre muligheder.
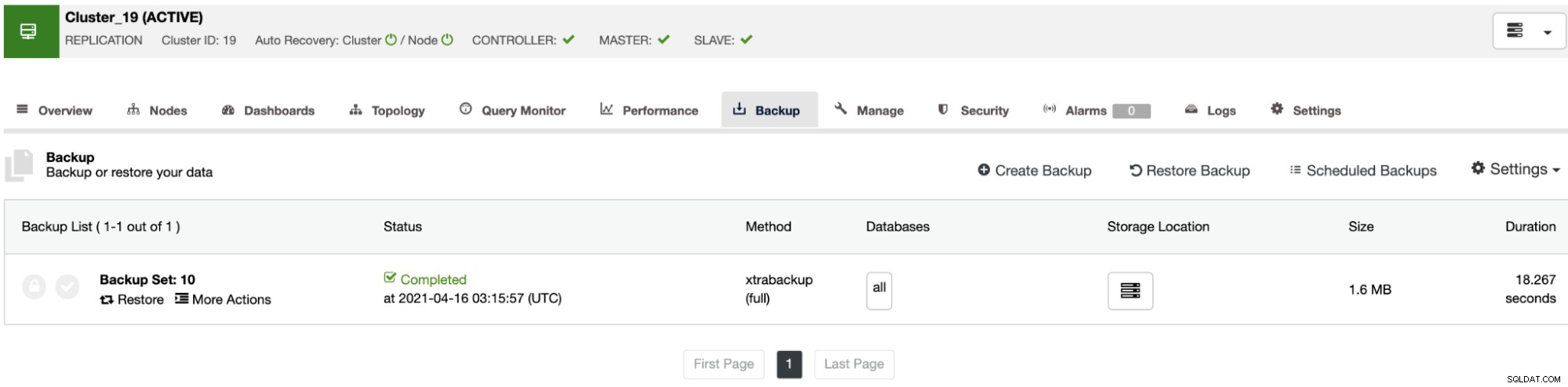
I sikkerhedskopieringssektionen kan du se sikkerhedskopieringens fremskridt og oplysninger som metode, størrelse, placering og mere.
Implementering af et testmiljø
For dette behøver du ikke at oprette alt fra bunden. I stedet for dette kan du bruge ClusterControl til at gøre dette på en manuel eller automatiseret måde.
Gendan sikkerhedskopiering på Standalone Host
I sektionen Sikkerhedskopiering kan du vælge muligheden "Gendan og verificere på selvstændig vært" for at gendanne en sikkerhedskopi i en separat node.
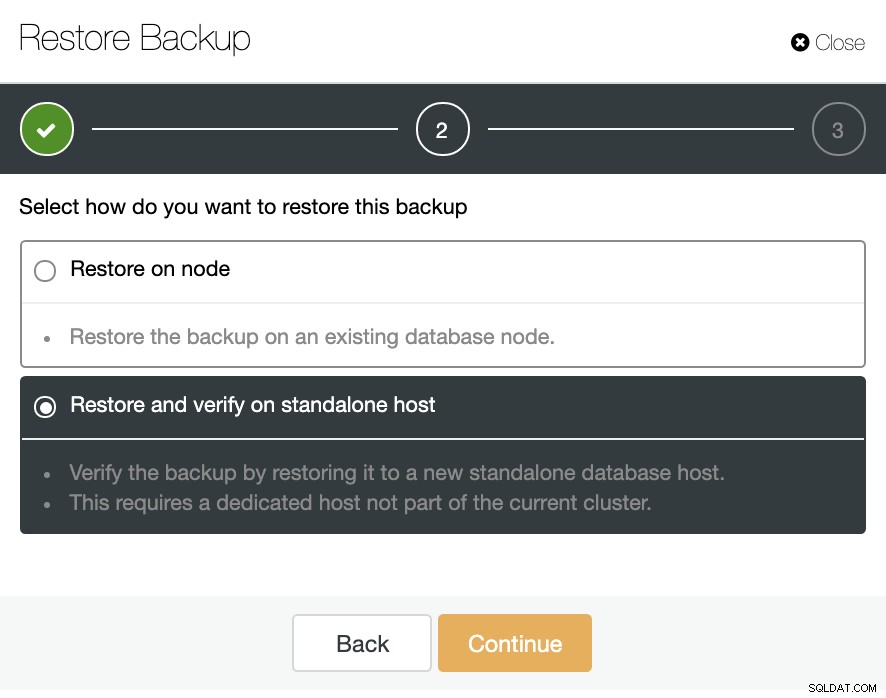
Her kan du angive, om du vil have ClusterControl til at installere softwaren i den nye node, og deaktivere firewallen eller AppArmor/SELinux (afhængigt af OS). Til dette har du brug for en dedikeret vært (eller VM), der ikke er en del af klyngen.
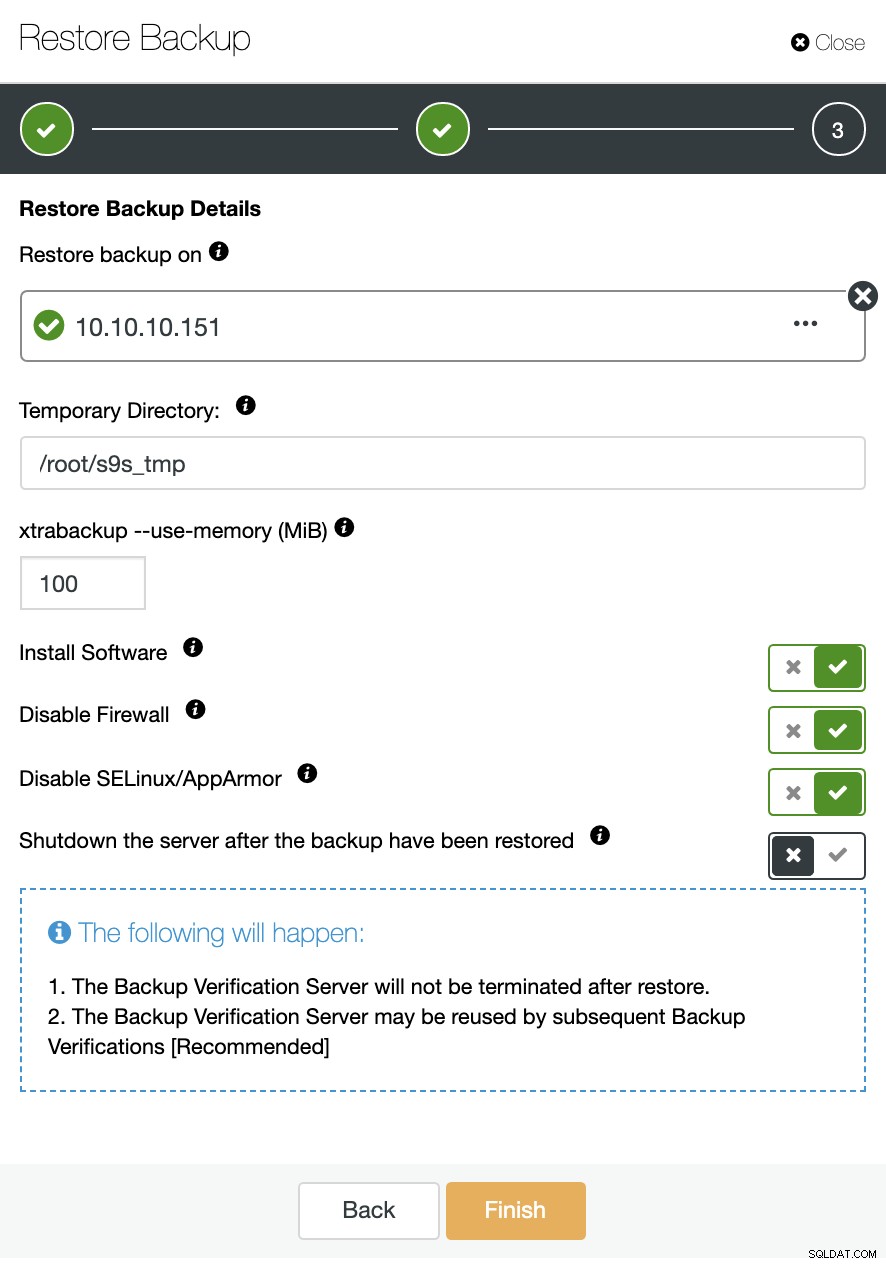
Du kan holde noden oppe og køre, eller ClusterControl kan lukke databasetjenesten ned indtil næste gendannelsesjob. Når den er færdig, vil du se den gendannede/verificerede sikkerhedskopi på backuplisten markeret med et flueben.
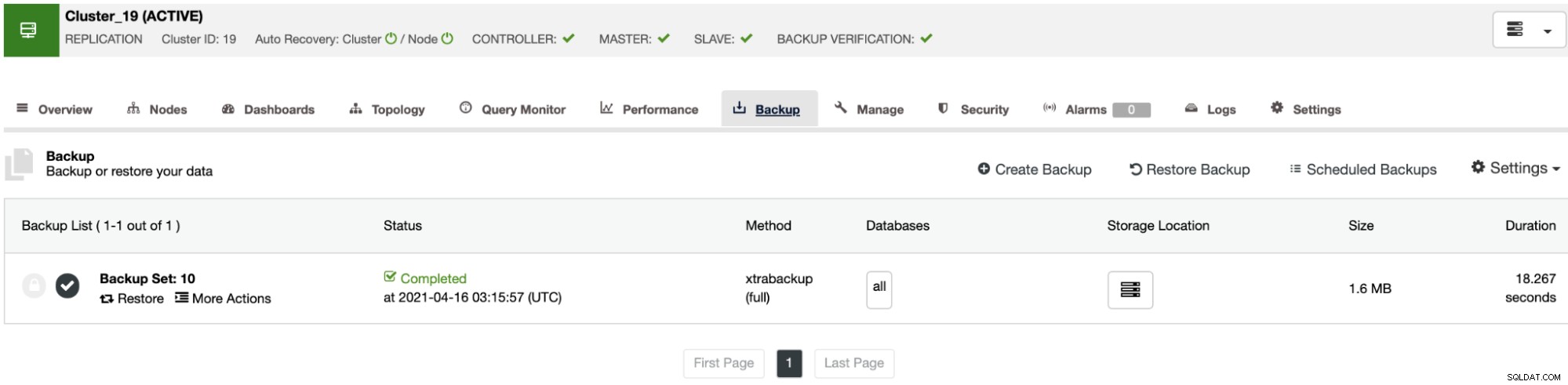
Hvis du ikke ønsker at udføre denne opgave manuelt, kan du planlægge denne proces ved at bruge funktionen Bekræft sikkerhedskopiering for at gentage dette job med jævne mellemrum i et sikkerhedskopieringsjob. Vi skal se, hvordan du gør dette i næste afsnit.
Automatisk ClusterControl-sikkerhedskopibekræftelse
For at automatisere denne opgave skal du gå til ClusterControl -> Vælg din klynge -> Sikkerhedskopiering -> Opret sikkerhedskopi, og vælg indstillingen Planlagt sikkerhedskopiering.
Den automatiske Bekræft sikkerhedskopiering er kun tilgængelig for planlagte sikkerhedskopier, og processen er den samme, som vi har beskrevet i et tidligere afsnit. I det andet trin skal du sikre dig, at du har aktiveret indstillingen Bekræft sikkerhedskopiering, og udfyld de nødvendige oplysninger.
Når jobbet er færdigt, kan du se bekræftelsesikonet i ClusterControl Backup sektionen, det samme som du vil have ved at udføre verifikationen på den manuelle måde, med den forskel, at du ikke behøver at bekymre sig om restaureringsopgaven. ClusterControl vil gendanne sikkerhedskopien hver gang automatisk, og du kan teste din applikation med de seneste data.
Autogendannelse og failover
Hvis autogendannelsesfunktionen er aktiveret, vil ClusterControl i tilfælde af fejl promovere den mest avancerede slaveknude, der skal mestres, samt give dig besked om problemet. Det mislykkes også over resten af slaveknuderne at replikere fra den nye masterserver.
Hvis der er Load Balancers i topologien, vil ClusterControl omkonfigurere dem til at anvende topologiændringerne.
Du kan også køre en failover manuelt, hvis det er nødvendigt. Gå til ClusterControl -> Vælg klyngen -> Noder -> Vælg den node, der skal forfremmes -> Nodehandlinger -> Promoter slave.
På denne måde, hvis noget går galt under opgraderingen, kan du bruge ClusterControl til at rette det ASAP.
Automatisering af ting med ClusterControl CLI
ClusterControl CLI, også kendt som s9s, er et kommandolinjeværktøj introduceret i ClusterControl version 1.4.1 til at interagere, kontrollere og administrere databaseklynger ved hjælp af ClusterControl-systemet. ClusterControl CLI åbner en dør til klyngeautomatisering, hvor du nemt kan integrere den med eksisterende implementeringsautomatiseringsværktøjer som Ansible, Puppet, Chef osv. Lad os nu se nogle eksempler på dette værktøj.
Opgrader
$ s9s cluster --cluster-id=19 \
--check-pkg-upgrades \
--log
$ s9s cluster --cluster-id=19 \
--available-upgrades \
--nodes='10.10.10.146' \
--log \
--print-json
$ s9s cluster --cluster-id=19 \
--upgrade-cluster \
--nodes='10.10.10.146' \
--logOpret sikkerhedskopi
$ s9s backup --create \
--backup-method=mysqldump \
--cluster-id=2 \
--nodes=10.10.10.146:3306 \
--on-controller \
--backup-directory=/storage/backups
--logGendan sikkerhedskopi
$ s9s backup --restore \
--cluster-id=19 \
--backup-id=3 \
--waitBekræft sikkerhedskopier
$ s9s backup --verify \
--backup-id=3 \
--test-server=10.10.10.151 \
--cluster-id=19 \
--logPromover slaveknude
$ s9s cluster --promote-slave \
--cluster-id=19 \
--nodes='10.10.10.146' \
--logKonklusion
Opgraderinger er nødvendige, men tidskrævende opgaver. Det kan være et mareridt at implementere et testmiljø hver gang du skal opgradere, og det er svært at holde dette opdateret uden noget automatiseringsværktøj.
ClusterControl giver dig mulighed for at udføre mindre opgraderinger eller endda implementere testmiljøet for at gøre opgraderingsopgaven nemmere og sikrere. Du kan også integrere det med forskellige automatiseringsværktøjer som Ansible, Puppet og mere.