I vores tidligere blogs har vi begrundet, hvorfor du har brug for en database-failover, og vi har forklaret, hvordan en failover-mekanisme fungerer. Jeg deler dette, hvis du har spørgsmål om, hvorfor du skal konfigurere en failover-mekanisme til din MySQL-database. Hvis du gør det, så læs venligst vores tidligere blogindlæg.
Sådan konfigurerer du automatisk failover
Fordelen ved at bruge MySQL eller MariaDB til automatisk at administrere din failover er, at der er tilgængelige værktøjer, du kan bruge og implementere i dit miljø. Fra open source-løsninger til virksomhedsløsninger. De fleste værktøjer er ikke kun failover-kompatible, der er andre funktioner såsom switchover, overvågning og avancerede funktioner, der kan tilbyde flere administrationsmuligheder for din MySQL-databaseklynge. Nedenfor vil vi gennemgå de mest almindelige, som du kan bruge.
Brug af MHA (Master High Availability)
Vi har taget dette emne med MHA med dets mest almindelige problemer og hvordan man løser dem. Vi har også sammenlignet MHA med MRM eller med MaxScale.
Opsætning med MHA for høj tilgængelighed er måske ikke let, men det er effektivt at bruge og fleksibelt, da der er justerbare parametre, du kan definere for at tilpasse din failover. MHA er blevet testet og brugt. Men efterhånden som teknologien udvikler sig, har MHA været bagud, da den ikke understøtter GTID til MariaDB, og den har ikke presset nogen opdateringer i de sidste 2 eller 3 år.
Ved at køre masterha_manager-scriptet
masterha_manager --conf=/etc/app1.cnfHvor en prøve /etc/app1.cnf skal se ud som følger,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parametre såsom no_master og candidate_master skal være afgørende, da du indstiller hvidlistede ønskede noder til at være din målmaster og noder, som du ikke ønsker at være en master.
Når du er indstillet, er du klar til at have failover for din MySQL-database, hvis der opstår fejl på den primære eller master. Scriptet masterha_manager administrerer failover (automatisk eller manuel), tager beslutninger om hvornår og hvor der skal failover, og administrerer slavegendannelse under promovering af kandidatmasteren for at anvende differentielle relælogfiler. Hvis masterdatabasen dør, vil MHA Manager koordinere med MHA Node-agenten, da den anvender differentielle relælogfiler til de slaver, der ikke har de seneste binlog-hændelser fra masteren.
Tjek, hvad MHA Node-agent gør, og dets involverede scripts. Dybest set er det scriptet, som MHA-administratoren vil påberåbe sig, når failover opstår. Den vil vente på sit mandat fra MHA Manager, mens den søger efter den seneste slave, der indeholder binlog-begivenhederne og kopierer manglende hændelser fra slaven ved hjælp af scp og anvender dem på sig selv. Som nævnt anvender den relælogs, renser relælogfiler eller gemmer binære logfiler.
Hvis du vil vide mere om parametre, der kan indstilles, og hvordan du tilpasser din failover-styring, kan du tjekke Parameters wiki-siden for MHA.
Brug af Orchestrator
Orchestrator er et MySQL- og MariaDB-værktøj til styring af høj tilgængelighed og replikering. Den er udgivet af Shlomi Noach under betingelserne i Apache-licensen, version 2.0. Dette er en open source-software og håndterer automatisk failover, men der er tonsvis af ting, du kan tilpasse eller gøre for at administrere din MySQL/MariaDB-database bortset fra gendannelse eller automatisk failover.
Installation af Orchestrator kan være let eller ligetil. Når du har downloadet de specifikke pakker, der kræves til dit målmiljø, er du klar til at registrere din klynge og noder, der skal overvåges af Orchestrator. Det giver en brugergrænseflade, som dette er meget let at administrere, men har masser af justerbare parametre eller sæt kommandoer, som du kan bruge til at opnå din failover-styring.
Lad os overveje, at du endelig har opsat og Registrering af klyngen ved at tilføje vores primære eller masterknude kan gøres ved hjælp af kommandoen nedenfor,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Nu har vi tilføjet vores klynge.
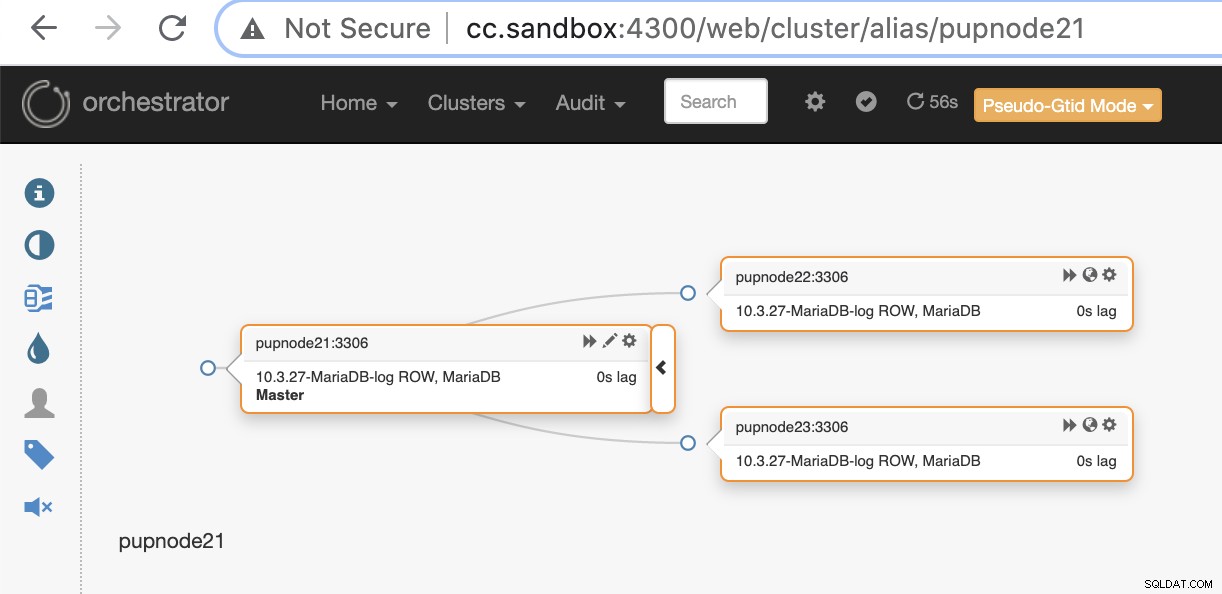
Hvis en primær node fejler (hardwarefejl eller stødt på nedbrud), vil Orchestrator finde og finde den mest avancerede node, der skal forfremmes som den primære eller master node.
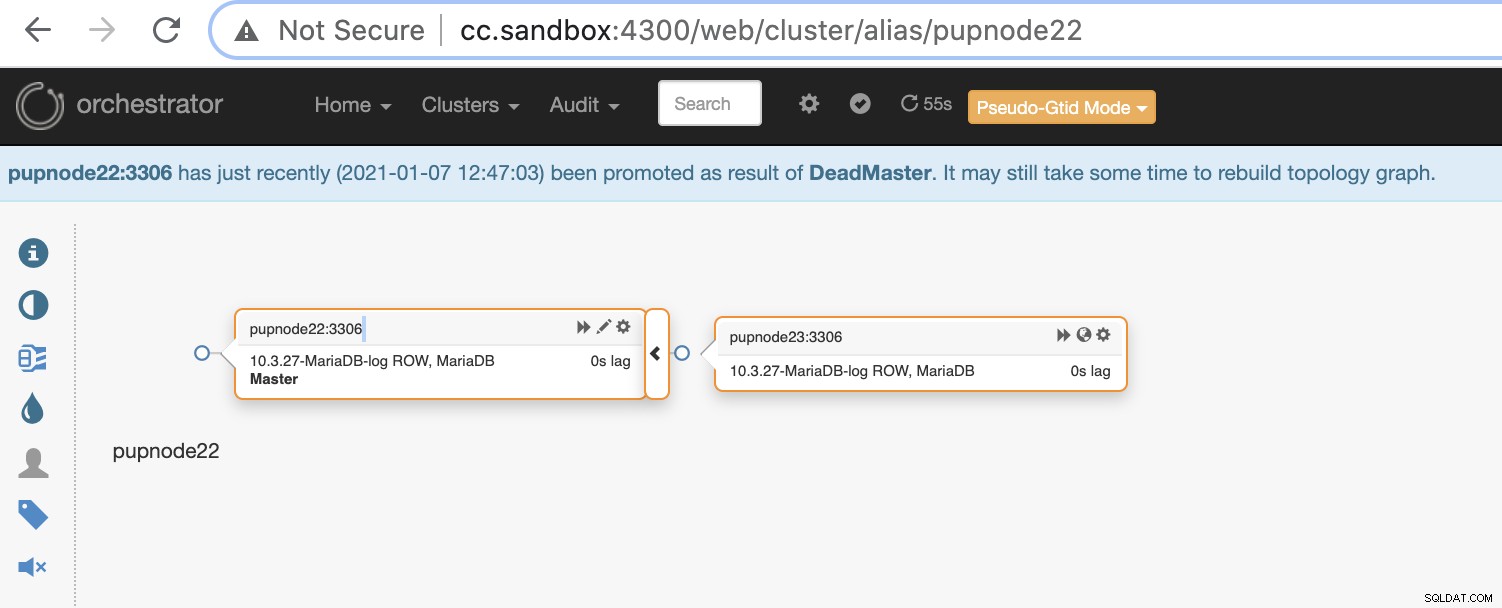
Nu har vi to noder tilbage i klyngen, mens den primære er nede .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Brug af MaxScale
MariaDB MaxScale er blevet understøttet som en databasebelastningsbalancer. I løbet af årene er MaxScale vokset og modnet, udvidet med adskillige rige funktioner, og det inkluderer automatisk failover. Siden MariaDB MaxScale 2.2 blev udgivet, introducerer den adskillige nye funktioner, herunder styring af replikeringsklynge-failover. Du kan læse vores tidligere blog om MaxScale failover-mekanisme.
Brug af MaxScale er under BSL, selvom softwaren er frit tilgængelig, men kræver, at du i det mindste køber service med MariaDB. Det er måske ikke egnet, men i tilfælde af at du har erhvervet MariaDB enterprise services, så kan dette være en stor fordel, hvis du har brug for failover-styring og dens andre funktioner.
Installation af MaxScale er let, men opsætning af den nødvendige konfiguration og definering af dens parametre er det ikke, og det kræver, at du skal forstå softwaren. Du kan se deres konfigurationsvejledning.
For hurtig og hurtig implementering kan du bruge ClusterControl til at installere MaxScale for dig i dit eksisterende MySQL/MariaDB-miljø.
Når den er installeret, kan opsætning af din Moodle-database gøres ved at pege din vært på MaxScale IP eller værtsnavn og læse-skriveporten. For eksempel,
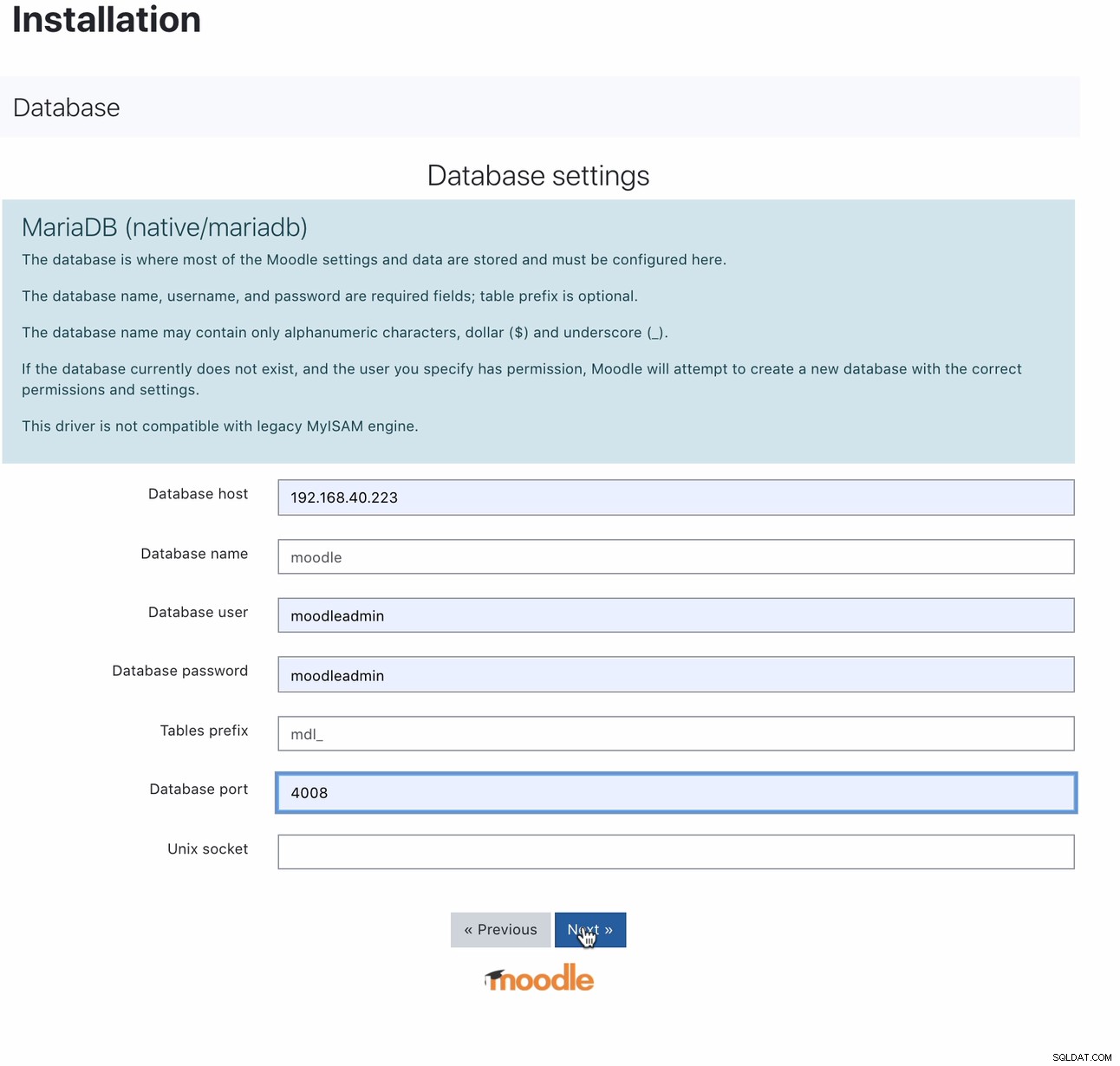
For hvilken port 4008 er din læse-skrive til din tjenestelytter. For eksempel, her er følgende service- og lyttekonfiguration for min MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseMens du er i din skærmkonfiguration, må du ikke glemme at aktivere den automatiske failover eller også aktivere auto rejoin, hvis du ønsker, at den tidligere master ikke automatisk kan tilslutte sig igen, når du går online igen. Det går sådan her,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Bemærk, at de variabler, jeg har angivet, ikke er beregnet til produktionsbrug, men kun til dette blogindlæg og testformål. Det gode med MaxScale, når først den primære eller master går ned, er MaxScale smart nok til at fremme den ideelle eller bedste kandidat til at tage rollen som master. Derfor er det ikke nødvendigt at ændre din IP og port, da vi har brugt værten/IP'en for vores MaxScale node og dens port som vores slutpunkt, når masteren går ned. For eksempel,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Node DB_123, som peger på 192.168.40.221, er den aktuelle master. Afslutning af noden DB_123 vil udløse MaxScale til at udføre en failover, og det skal se sådan ud,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Mens vores Moodle-database stadig er oppe og køre, da vores MaxScale peger på den seneste master, der blev promoveret.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Brug af ClusterControl
ClusterControl kan downloades gratis og tilbyder licenser til Community, Advance og Enterprise. Den automatiske failover er kun tilgængelig på Advance og Enterprise. Automatisk failover er dækket af vores Auto-Recovery-funktion, som forsøger at gendanne en mislykket klynge eller en mislykket node. Hvis du vil have flere detaljer om, hvordan du udfører dette, så tjek vores tidligere indlæg How ClusterControl udfører automatisk databasegendannelse og failover. Det tilbyder indstillelige parametre, som er meget praktiske og nemme at bruge. Læs venligst vores tidligere indlæg også om Sådan automatiseres databasefailover med ClusterControl.
Administration af din automatiske failover for din Moodle-database skal som minimum kræve en virtuel IP (VIP) som dit slutpunkt for din Moodle-applikationsklient, der har grænseflade til din database-backend. For at gøre dette kan du implementere Keepalived med HAProxy (eller ProxySQL - afhænger af dit valg af load balancer) ovenpå. I dette tilfælde skal dit Moodle-databaseslutpunkt pege på den virtuelle IP, som dybest set er tildelt af Keepalved, når du har implementeret den, på samme måde som vi viste dig tidligere, da vi satte MaxScale op. Du kan også tjekke denne blog om, hvordan du gør det.
Som nævnt ovenfor er tunbare parametre tilgængelige, som du bare kan indstille via din /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replikeringsstop_ved_fejl
ClusterControl er meget fleksibel, når du administrerer failover, så du kan udføre nogle præ-failover eller post-failover opgaver.
Konklusion
Der er andre gode valg, når du opsætter og automatisk administrerer din failover for din MySQL-database til Moodle. Det afhænger af dit budget og hvad du sandsynligvis skal bruge penge til. Brug af open source-systemer kræver ekspertise og kræver flere tests for at blive fortrolige, da der ikke er nogen support, du kan køre, når du har brug for hjælp ud over fællesskabet. Med virksomhedsløsninger kommer det med en pris, men det giver dig støtte og lethed, da det tidskrævende arbejde kan mindskes. Vær opmærksom på, at hvis failover bruges fejlagtigt, kan det koste skade på din database, hvis det ikke håndteres og administreres korrekt. Fokuser på, hvad der er vigtigere, og hvordan du er i stand til de løsninger, du bruger til at administrere din Moodle-database-failover.