Hvis du ikke har set det, har vi netop udgivet ClusterControl 1.7.5 med store forbedringer og nye nyttige funktioner. Nogle af funktionerne inkluderer Cluster Wide Maintenance, support til version CentOS 8 og Debian 10, PostgreSQL 12 Support, MongoDB 4.2 og Percona MongoDB v4.0 support, samt den nye MySQL Freeze Frame.
Vent, men hvad er en MySQL Freeze Frame? Er dette noget nyt i MySQL?
Det er ikke noget nyt i selve MySQL-kernen. Det er en ny funktion, vi tilføjede til ClusterControl 1.7.5, som er specifik for MySQL-databaser. MySQL Freeze Frame i ClusterControl 1.7.5 vil dække følgende ting:
- Snapshot MySQL-status før klyngefejl.
- Snapshot MySQL-procesliste før klyngefejl (kommer snart).
- Inspicer klyngehændelser i driftsrapporter eller fra s9s kommandolinjeværktøj.
Dette er værdifulde sæt oplysninger, der kan hjælpe med at spore fejl og rette dine MySQL/MariaDB-klynger, når tingene går sydpå. I fremtiden planlægger vi også at inkludere snapshots af SHOW ENGINE InnoDB-statusværdierne. Så følg venligst med på vores fremtidige udgivelser.
Bemærk, at denne funktion stadig er i betatilstand, vi forventer at indsamle flere datasæt, efterhånden som vi arbejder med vores brugere. I denne blog vil vi vise dig, hvordan du kan udnytte denne funktion, især når du har brug for yderligere information, når du skal diagnosticere din MySQL/MariaDB-klynge.
ClusterControl om håndtering af klyngefejl
For klyngefejl gør ClusterControl intet, medmindre automatisk gendannelse (klynge/node) er aktiveret ligesom nedenfor:

Når det er aktiveret, vil ClusterControl forsøge at gendanne en node eller gendanne klyngen ved at bringer hele klyngetopologien frem.
For MySQL, for eksempel i en master-slave-replikering, skal den have mindst én master i live på et givet tidspunkt, uanset antallet af tilgængelige slaver. ClusterControl forsøger at korrigere topologien mindst én gang for replikeringsklynger, men giver flere genforsøg til multi-master replikering som NDB Cluster og Galera Cluster. Node recovery forsøger at gendanne en defekt databasenode, f.eks. når processen blev dræbt (unormal nedlukning), eller processen led en OOM (Out-of-Memory). ClusterControl vil oprette forbindelse til noden via SSH og forsøge at hente MySQL. Vi har tidligere blogget om, hvordan ClusterControl udfører automatisk databasegendannelse og failover, så besøg venligst denne artikel for at lære mere om ordningen for automatisk gendannelse af ClusterControl.
I den tidligere version af ClusterControl <1.7.5 udløste disse forsøg på gendannelse alarmer. Men én ting, vores kunder savnede, var en mere komplet hændelsesrapport med tilstandsoplysninger lige før klyngesvigt. Indtil vi indså denne mangel og tilføjede denne funktion i ClusterControl 1.7.5. Vi kaldte det "MySQL Freeze Frame". MySQL Freeze Frame tilbyder, når dette skrives, en kort oversigt over hændelser, der fører til klyngetilstandsændringer lige før nedbruddet. Vigtigst er det, at det i slutningen af rapporten inkluderer listen over værter og deres MySQL Global Status-variabler og -værdier.
Hvordan adskiller MySQL Freeze Frame sig fra automatisk gendannelse?
MySQL Freeze Frame er ikke en del af den automatiske gendannelse af ClusterControl. Uanset om automatisk gendannelse er deaktiveret eller aktiveret, vil MySQL Freeze Frame altid gøre sit arbejde, så længe en klynge- eller nodefejl er blevet opdaget.
Hvordan fungerer MySQL Freeze Frame?
I ClusterControl er der visse tilstande, som vi klassificerer som forskellige typer af Cluster Status. MySQL Freeze Frame vil generere en hændelsesrapport, når disse to tilstande udløses:
- KLUSTER_DEGRADERET
- CLUSTER_FAILURE
I ClusterControl er en CLUSTER_DEGRADED, når du kan skrive til en klynge, men en eller flere noder er nede. Når dette sker, genererer ClusterControl hændelsesrapporten.
For CLUSTER_FAILURE, selvom dens nomenklatur forklarer sig selv, er det den tilstand, hvor din klynge fejler og ikke længere er i stand til at behandle læsninger eller skrivninger. Så er det en CLUSTER_FAILURE-tilstand. Uanset om en automatisk gendannelsesproces forsøger at løse problemet, eller om den er deaktiveret, genererer ClusterControl hændelsesrapporten.
Hvordan aktiverer du MySQL Freeze Frame?
ClusterControls MySQL Freeze Frame er aktiveret som standard og genererer kun en hændelsesrapport, når tilstandene CLUSTER_DEGRADED eller CLUSTER_FAILURE udløses eller stødes på. Så der er ikke behov for i brugerens ende at indstille nogen ClusterControl-konfigurationsindstilling, ClusterControl vil gøre det automatisk for dig.
Sådan finder du MySQL Freeze Frame Incident Report
Når dette skrives, er der 4 måder, hvorpå du kan finde hændelsesrapporten. Disse kan findes ved at gøre følgende afsnit nedenfor.
Brug af fanen Driftsrapporter
Driftsrapporterne fra de tidligere versioner bruges kun til at oprette, planlægge eller liste de driftsrapporter, der er blevet genereret af brugere. Siden version 1.7.5 har vi inkluderet hændelsesrapporten genereret af vores MySQL Freeze Frame-funktion. Se eksemplet nedenfor:
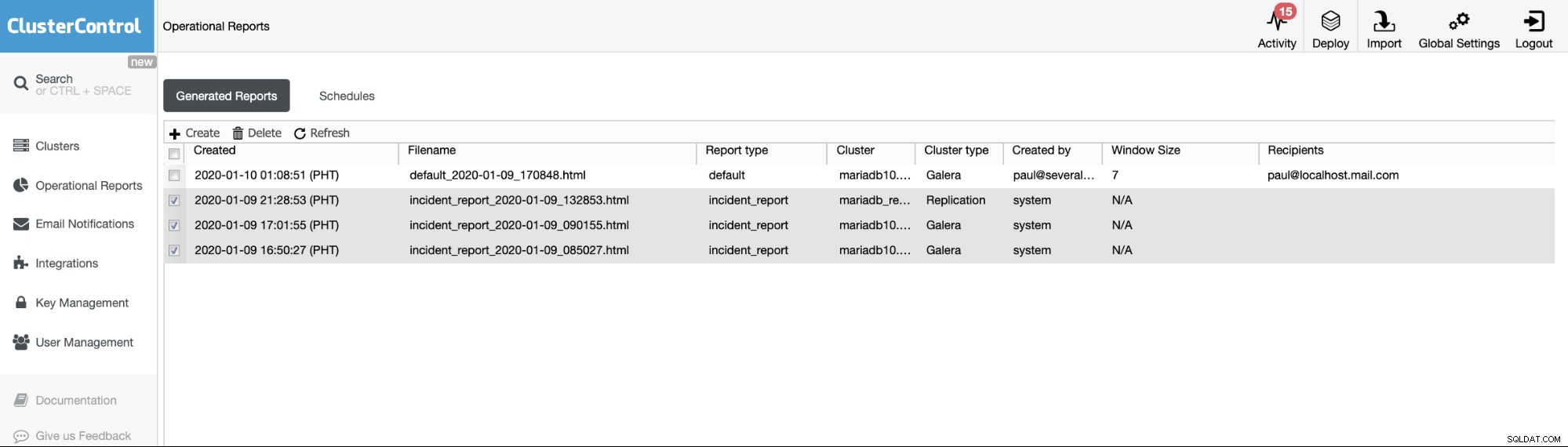
De markerede elementer eller elementer med rapporttype ==incident_report, er hændelsen rapporter genereret af MySQL Freeze Frame-funktionen i ClusterControl.
Brug af fejlrapporter
Ved at vælge klyngen og generere en fejlrapport, dvs. gå gennem denne proces:
Brug af s9s CLI-kommandolinje
På en genereret hændelsesrapport indeholder den instruktioner eller tip til, hvordan du kan bruge dette med s9s CLI-kommando. Nedenfor er det, der vises i hændelsesrapporten:
Tip! Ved at bruge s9s CLI-værktøjet kan du nemt håndtere data i denne rapport, f.eks.:
s9s report --list --long
s9s report --cat --report-id=NSå hvis du vil finde og generere en fejlrapport, kan du bruge denne fremgangsmåde:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportHvis jeg vil bruge wsrep_*-variablerne på en bestemt vært, kan jeg gøre følgende:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Manuel lokalisering via systemfilstien
ClusterControl genererer disse hændelsesrapporter i den vært, hvor ClusterControl kører. ClusterControl opretter en mappe i /home/
Er der nogen farer eller forbehold ved brug af MySQL Freeze Frame?
ClusterControl ændrer eller modificerer ikke noget i dine MySQL-noder eller -klynge. MySQL Freeze Frame vil bare læse VIS GLOBAL STATUS (fra dette tidspunkt) med bestemte intervaller for at gemme poster, da vi ikke kan forudsige tilstanden af en MySQL-node eller -klynge, hvornår den kan gå ned, eller hvornår den kan have hardware- eller diskproblemer. Det er ikke muligt at forudsige dette, så vi gemmer værdierne og derfor kan vi generere en hændelsesrapport, hvis en bestemt node går ned. I så fald er faren for at have dette tæt på ingen. Det kan teoretisk tilføje en række klientanmodninger til serveren/serverne i tilfælde af at nogle låse holdes i MySQL, men vi har ikke bemærket det endnu. Serien af test viser dette ikke, så vi ville være glade, hvis du kan lade os kender eller indsender en supportbillet, hvis der opstår problemer.
Der er visse situationer, hvor en hændelsesrapport muligvis ikke er i stand til at indsamle globale statusvariabler, hvis et netværksproblem var problemet, før ClusterControl fryser en bestemt ramme for at indsamle data. Det er fuldstændig rimeligt, fordi der ikke er nogen måde, ClusterControl kan indsamle data til yderligere diagnose, da der ikke er nogen forbindelse til noden i første omgang.
Til sidst kan du undre dig over, hvorfor ikke alle variabler vises i GLOBAL STATUS-sektionen? I mellemtiden sætter vi et filter, hvor tomme eller 0 værdier udelukkes i hændelsesrapporten. Årsagen er, at vi gerne vil spare noget diskplads. Når disse hændelsesrapporter ikke længere er nødvendige, kan du slette dem via fanen Driftsrapporter.
Test af MySQL Freeze Frame-funktionen
Vi tror på, at du er ivrig efter at prøve denne og se, hvordan den virker. Men sørg venligst for, at du ikke kører eller tester dette i et live- eller produktionsmiljø. Vi vil dække 2-faser af scenarier i MySQL/MariaDB, en til master-slave-opsætning og en til Galera-type-opsætning.
Master-Slave Setup Test Scenario
I en master-slave-opsætning er det nemt og enkelt at prøve.
Trin 1
Sørg for, at du har deaktiveret automatisk gendannelsestilstande (klynge og node), som nedenfor:

så den vil ikke prøve eller forsøge at rette testscenariet.
Trin to
Gå til din masterknude, og prøv at indstille til skrivebeskyttet:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Trin tre
Denne gang blev der slået en alarm og derfor genereret en hændelsesrapport. Se nedenfor, hvordan min klynge ser ud:

og alarmen blev udløst:

og hændelsesrapporten blev genereret:

Galera Cluster Setup Test Scenario
For Galera-baseret opsætning skal vi sikre os, at klyngen ikke længere er tilgængelig, dvs. en fejl i hele klyngen. I modsætning til Master-Slave-testen kan du lade Auto Recovery aktiveret, da vi leger med netværksgrænseflader.
Bemærk:For denne opsætning skal du sikre dig, at du har flere grænseflader, hvis du tester noderne i en fjernforekomst, da du ikke kan få grænsefladen op, når du nedsætter den grænseflade, hvor du er tilsluttet.
Trin 1
Opret en Galera-klynge med 3 noder (f.eks. ved hjælp af vagrant)
Trin to
Udfør kommandoen (ligesom nedenfor) for at simulere netværksproblem og gør dette til alle noderne
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Trin tre
Nu tog den min klynge ned og har denne tilstand:

rejste en alarm,

og det genererer en hændelsesrapport:

Du kan bruge denne råfil og gemme den til en eksempelrapport om hændelser som html.
Det er ret nemt at prøve, men igen, gør venligst dette kun i et ikke-live og ikke-prod miljø.
Konklusion
MySQL Freeze Frame i ClusterControl kan være nyttigt ved diagnosticering af nedbrud. Ved fejlfinding har du brug for et væld af informationer for at fastslå årsagen, og det er præcis, hvad MySQL Freeze Frame giver.