I dag er det almindeligt at se en stor mængde data i en virksomheds database, men afhængigt af størrelsen kan det være svært at administrere, og ydeevnen kan blive påvirket under høj trafik, hvis vi ikke konfigurerer eller implementerer det på en korrekt måde . Generelt, hvis vi har en enorm database, og vi vil have en lav svartid, vil vi gerne skalere den. PostgreSQL er ikke undtagelsen fra dette punkt. Der er mange tilgængelige tilgange til at skalere PostgreSQL, men lad os først lære, hvad skalering er.
Skalerbarhed er et system/databases egenskab til at håndtere en voksende mængde krav ved at tilføje ressourcer.
Årsagerne til denne mængde efterspørgsel kan være tidsmæssige, for eksempel hvis vi lancerer en rabat på et udsalg, eller permanent, for en stigning i kunder eller medarbejdere. Under alle omstændigheder bør vi være i stand til at tilføje eller fjerne ressourcer for at styre disse ændringer på krav eller øget trafik.
I denne blog vil vi se på, hvordan vi kan skalere vores PostgreSQL-database, og hvornår vi skal gøre det.
Horisontal skalering vs vertikal skalering
Der er to hovedmåder at skalere vores database...
- Horisontal skalering (udskalering):Det udføres ved at tilføje flere databasenoder, der skaber eller øger en databaseklynge.
- Lodret skalering (opskalering):Det udføres ved at tilføje flere hardwareressourcer (CPU, hukommelse, disk) til en eksisterende databasenode.
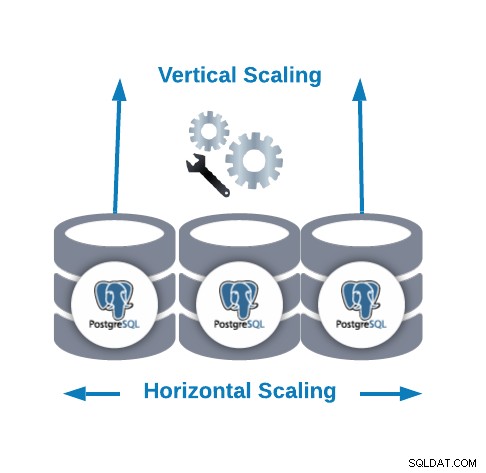
Til horisontal skalering kan vi tilføje flere databasenoder som slaveknudepunkter. Det kan hjælpe os med at forbedre læseydelsen ved at balancere trafikken mellem noderne. I dette tilfælde bliver vi nødt til at tilføje en belastningsbalancer for at distribuere trafik til den korrekte node afhængigt af politikken og nodetilstanden.
For at undgå et enkelt fejlpunkt, der kun tilføjer én belastningsbalancer, bør vi overveje at tilføje to eller flere load balancer-noder og bruge et eller andet værktøj som "Keepalived", for at sikre tilgængeligheden.
Da PostgreSQL ikke har indbygget multi-master-understøttelse, skal vi bruge et eksternt værktøj til denne opgave, hvis vi vil implementere det for at forbedre skriveydeevnen.
For vertikal skalering kan det være nødvendigt at ændre nogle konfigurationsparametre for at tillade PostgreSQL at bruge en ny eller bedre hardwareressource. Lad os se nogle af disse parametre fra PostgreSQL-dokumentationen.
- work_mem:Specificerer mængden af hukommelse, der skal bruges af interne sorteringsoperationer og hashtabeller, før der skrives til midlertidige diskfiler. Flere løbesessioner kunne udføre sådanne operationer samtidigt, så den samlede hukommelse, der bruges, kan være mange gange værdien af work_mem.
- maintenance_work_mem:Angiver den maksimale mængde hukommelse, der skal bruges af vedligeholdelsesoperationer, såsom VACUUM, CREATE INDEX og ALTER TABLE ADD FOREIGN KEY. Større indstillinger kan forbedre ydeevnen til støvsugning og til gendannelse af databasedumps.
- autovacuum_work_mem:Specificerer den maksimale mængde hukommelse, der skal bruges af hver autovacuum-arbejdsproces.
- autovacuum_max_workers:Angiver det maksimale antal autovacuum-processer, der kan køre på ethvert tidspunkt.
- max_worker_processes:Indstiller det maksimale antal baggrundsprocesser, som systemet kan understøtte. Angiv grænsen for processen som støvsugning, kontrolpunkter og flere vedligeholdelsesjob.
- max_parallel_workers:Indstiller det maksimale antal arbejdere, som systemet kan understøtte for parallelle operationer. Parallelle arbejdere tages fra puljen af arbejdsprocesser etableret af den foregående parameter.
- max_parallel_maintenance_workers:Indstiller det maksimale antal parallelle arbejdere, der kan startes af en enkelt hjælpekommando. I øjeblikket er den eneste parallelle hjælpekommando, der understøtter brugen af parallelle arbejdere, CREATE INDEX, og kun ved opbygning af et B-træindeks.
- effective_cache_size:Indstiller planlæggerens antagelse om den effektive størrelse af diskcachen, der er tilgængelig for en enkelt forespørgsel. Dette er indregnet i estimater af omkostningerne ved at bruge et indeks; en højere værdi gør det mere sandsynligt, at indeksscanninger vil blive brugt, en lavere værdi gør det mere sandsynligt, at sekventielle scanninger vil blive brugt.
- shared_buffers:Indstiller mængden af hukommelse, databaseserveren bruger til delt hukommelsesbuffere. Indstillinger, der er væsentligt højere end minimum, er normalt nødvendige for god ydeevne.
- temp_buffers:Indstiller det maksimale antal midlertidige buffere, der bruges af hver databasesession. Disse er sessionslokale buffere, der kun bruges til adgang til midlertidige tabeller.
- effective_io_concurrency:Indstiller antallet af samtidige disk I/O-operationer, som PostgreSQL forventer kan udføres samtidigt. At hæve denne værdi vil øge antallet af I/O-operationer, som enhver individuel PostgreSQL-session forsøger at starte parallelt. I øjeblikket påvirker denne indstilling kun bitmap-heap-scanninger.
- max_connections:Bestemmer det maksimale antal samtidige forbindelser til databaseserveren. Forøgelse af denne parameter tillader PostgreSQL at køre flere backend-processer samtidigt.
På dette tidspunkt er der et spørgsmål, som vi må stille. Hvordan kan vi vide, om vi har brug for at skalere vores database, og hvordan kan vi vide, hvordan vi bedst gør det?
Overvågning
At skalere vores PostgreSQL-database er en kompleks proces, så vi bør tjekke nogle metrics for at kunne bestemme den bedste strategi til at skalere den.
Vi kan overvåge CPU-, hukommelses- og diskforbruget for at afgøre, om der er et eller andet konfigurationsproblem, eller om vi faktisk skal skalere vores database. For eksempel, hvis vi ser en høj serverbelastning, men databaseaktiviteten er lav, er det sandsynligvis ikke nødvendigt at skalere den, vi behøver kun at kontrollere konfigurationsparametrene for at matche den med vores hardwareressourcer.
Kontrol af diskpladsen, der bruges af PostgreSQL-noden pr. database, kan hjælpe os med at bekræfte, om vi har brug for mere disk eller endda en tabelopdeling. For at kontrollere diskpladsen, der bruges af en database/tabel, kan vi bruge nogle PostgreSQL-funktioner som pg_database_size eller pg_table_size.
Fra databasesiden bør vi tjekke
- Mængde af forbindelse
- Kører forespørgsler
- Indeksbrug
- Blæst
- Replikeringsforsinkelse
Disse kunne være klare målinger for at bekræfte, om skalering af vores database er nødvendig.
ClusterControl som et skalerings- og overvågningssystem
ClusterControl kan hjælpe os med at klare både skaleringsmåder, som vi så tidligere, og med at overvåge alle nødvendige målinger for at bekræfte skaleringskravet. Lad os se hvordan...
Hvis du ikke bruger ClusterControl endnu, kan du installere det og implementere eller importere din nuværende PostgreSQL-database ved at vælge "Import"-indstillingen og følge trinene for at drage fordel af alle ClusterControl-funktionerne som sikkerhedskopier, automatisk failover, advarsler, overvågning, og mere.
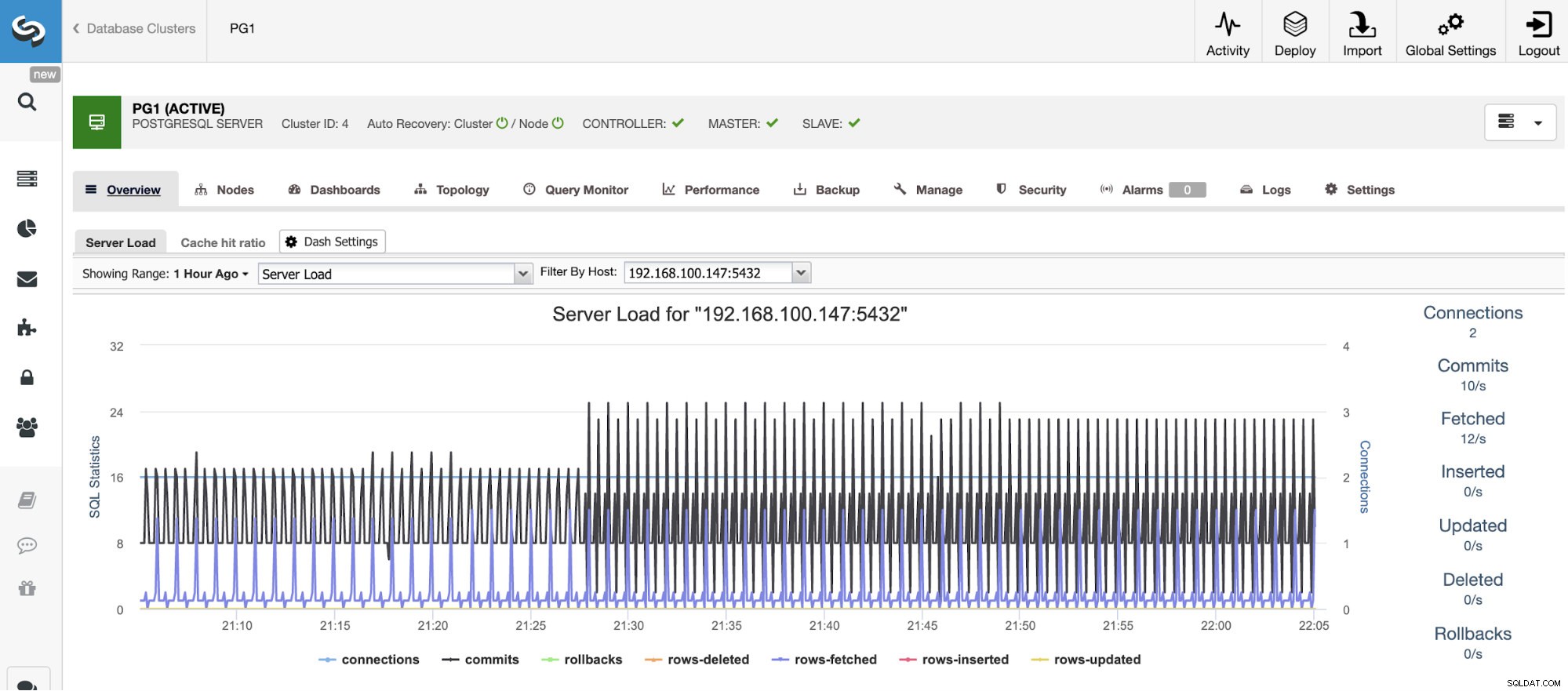
Horisontal skalering
For horisontal skalering, hvis vi går til klyngehandlinger og vælger "Tilføj replikeringsslave", kan vi enten oprette en ny replika fra bunden eller tilføje en eksisterende PostgreSQL-database som en replika.
Lad os se, hvordan det kan være en rigtig nem opgave at tilføje en ny replikeringsslave.
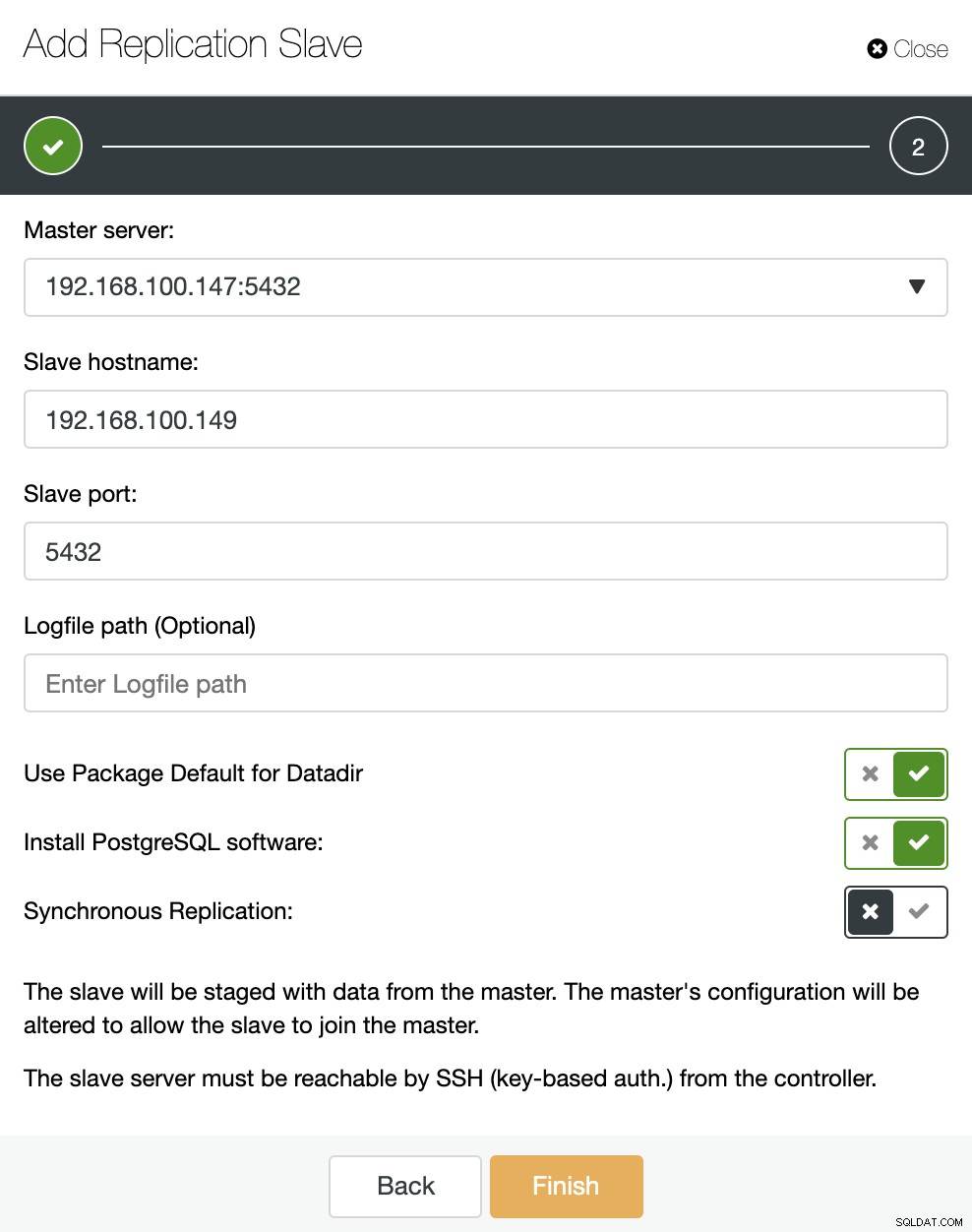
Som du kan se på billedet, skal vi kun vælge vores Master server, indtaste IP adressen til vores nye slave server og database porten. Derefter kan vi vælge, om vi vil have ClusterControl til at installere softwaren for os, og om replikeringsslaven skal være Synchronous eller Asynchronous.
På denne måde kan vi tilføje så mange replikaer, som vi vil, og sprede læst trafik mellem dem ved hjælp af en load balancer, som vi også kan implementere med ClusterControl.
Hvis vi nu går til klyngehandlinger og vælger "Tilføj Load Balancer", kan vi implementere en ny HAProxy Load Balancer eller tilføje en eksisterende.
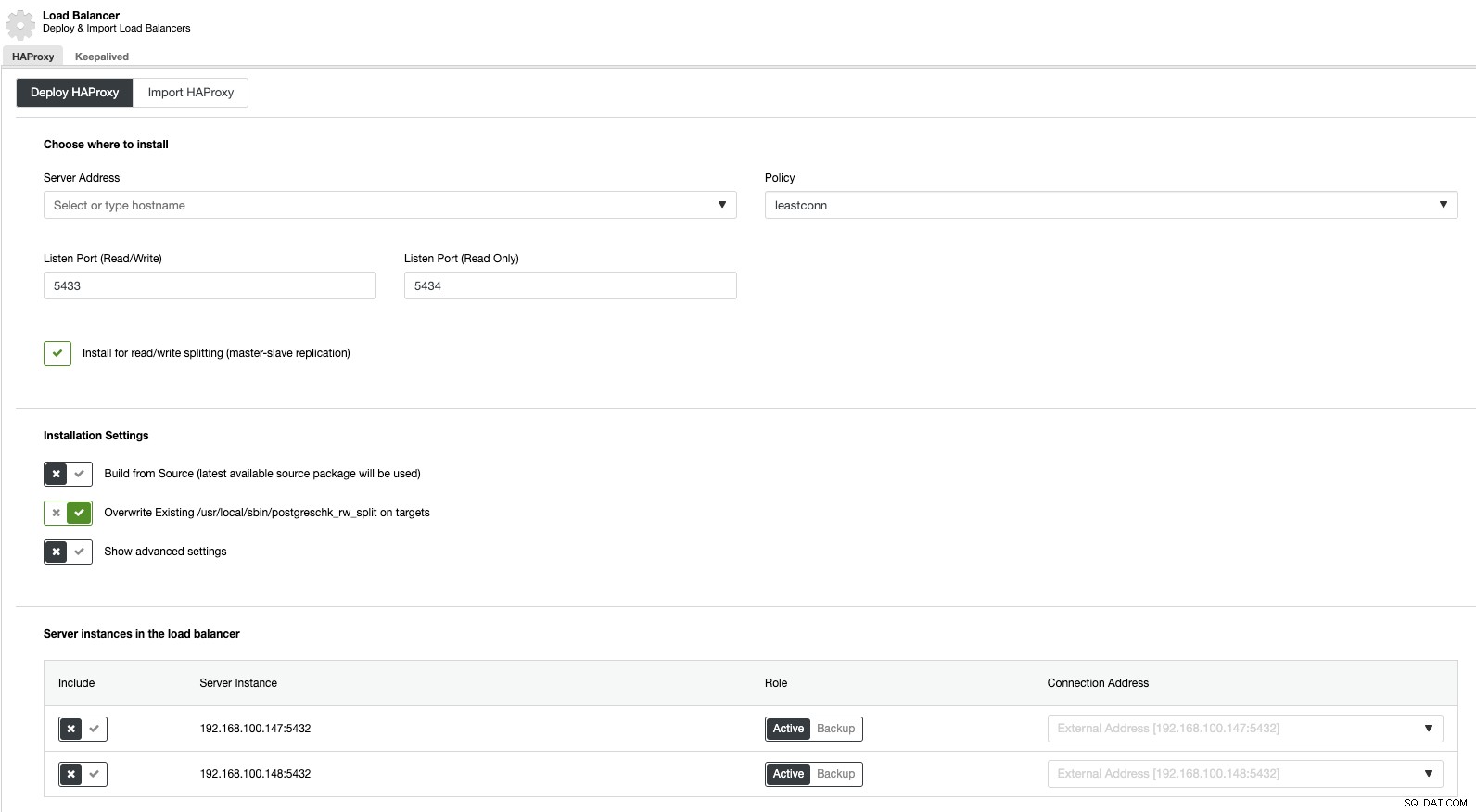
Og så kan vi i den samme load balancer sektion tilføje en Keepalved service, der kører på load balancer noderne for at forbedre vores høje tilgængelighedsmiljø.
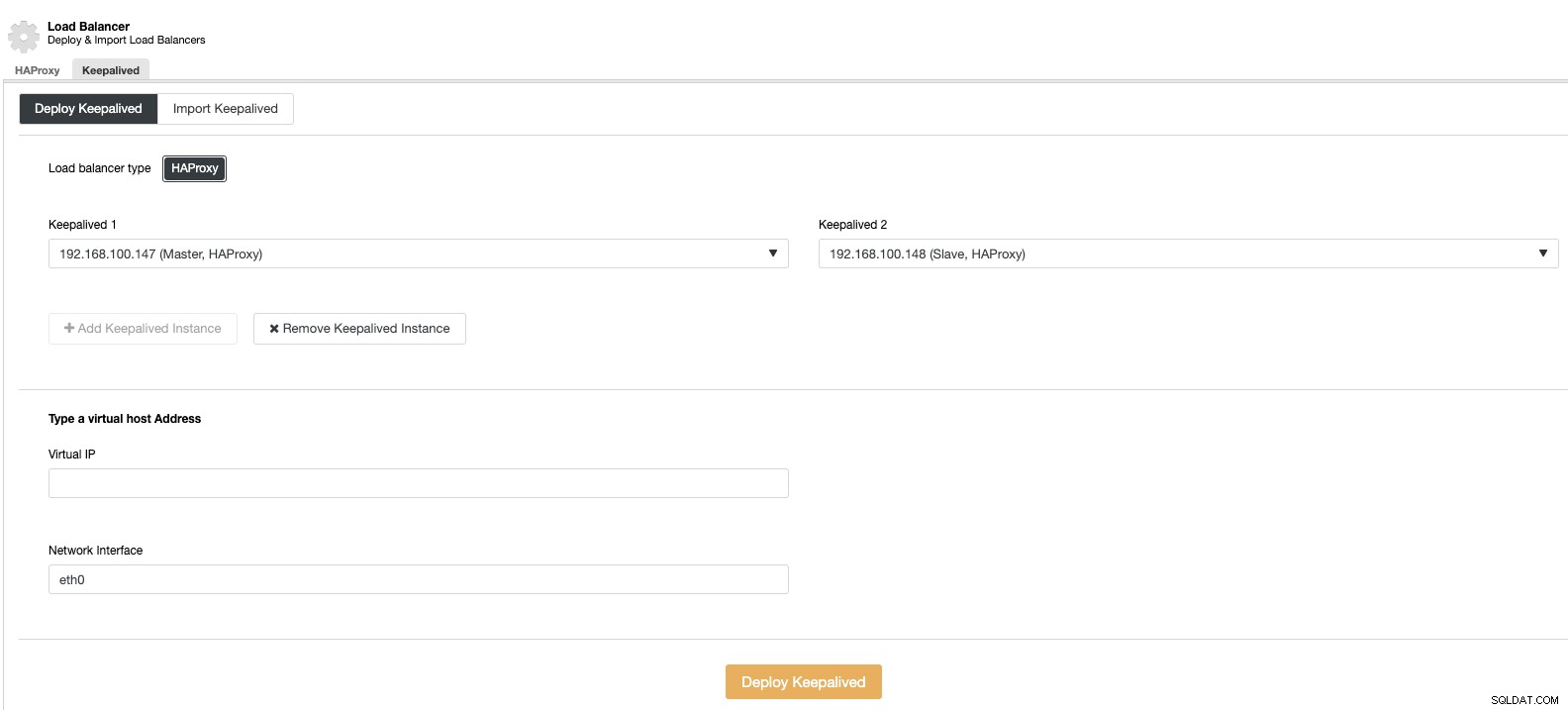
Lodret skalering
Til vertikal skalering kan vi med ClusterControl overvåge vores databasenoder fra både operativsystemet og databasesiden. Vi kan tjekke nogle målinger som CPU-brug, hukommelse, forbindelser, topforespørgsler, kørende forespørgsler og endnu mere. Vi kan også aktivere Dashboard-sektionen, som giver os mulighed for at se metrics mere detaljeret og på en mere venlig måde vores metrics.
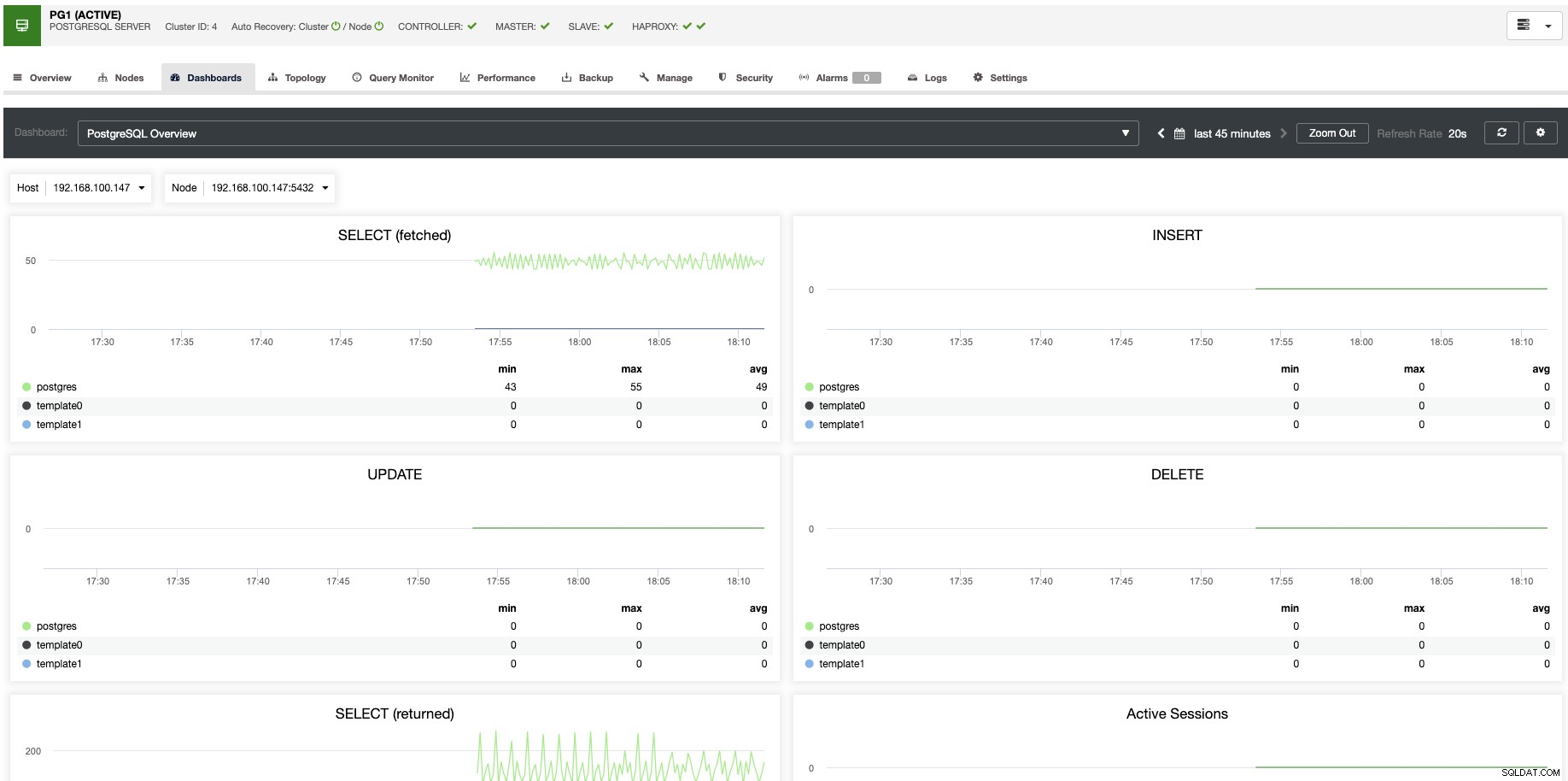
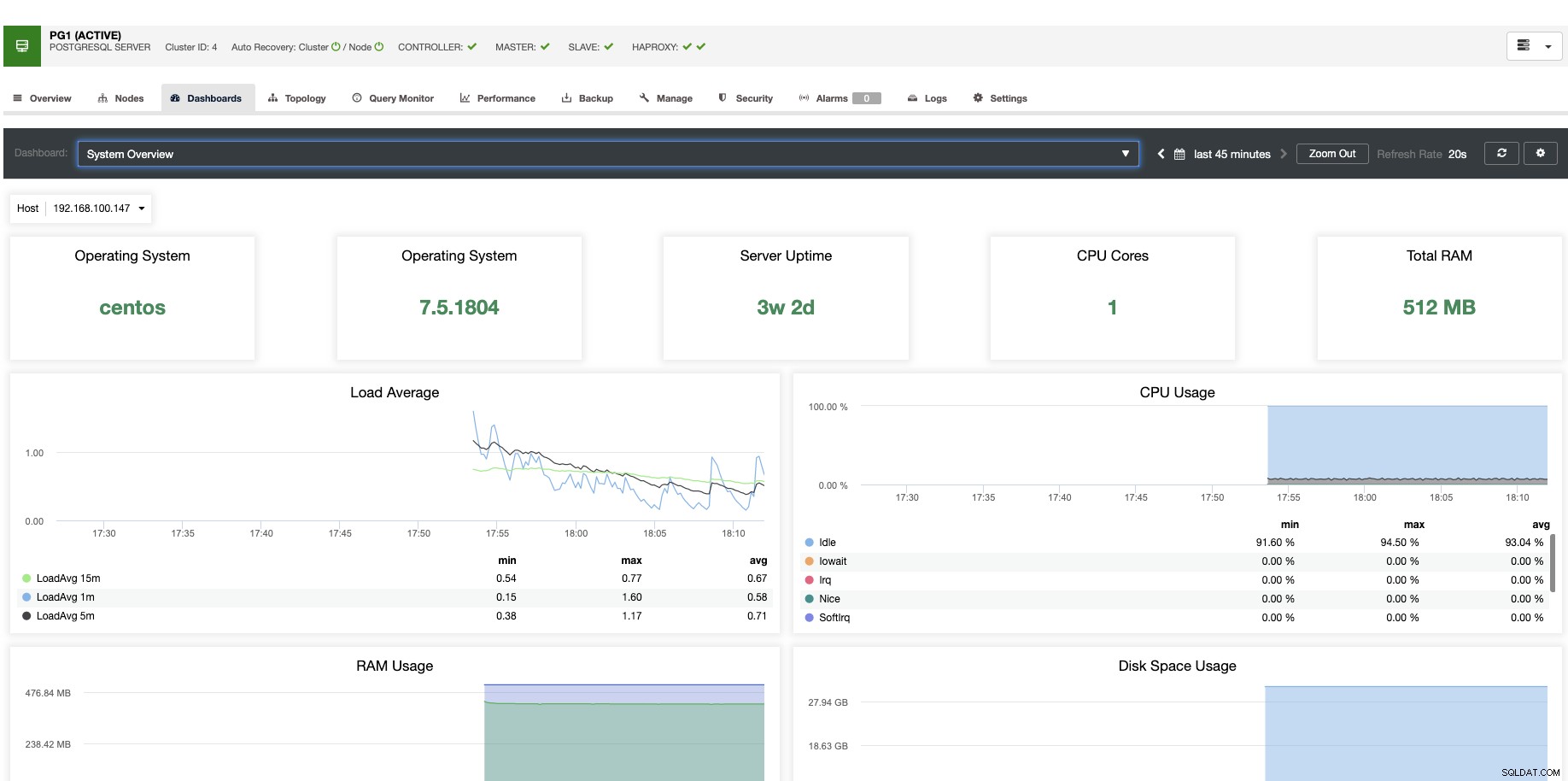
Fra ClusterControl kan du også udføre forskellige administrationsopgaver såsom Genstart vært, Genopbyg replikeringsslave eller Fremme slave med et enkelt klik.
Konklusion
At udskalere PostgreSQL-databaser kan være en tidskrævende opgave. Vi skal vide, hvad vi skal skalere, og hvad den bedste måde er at gøre det på. I sidste ende bliver styring og skalering af klynger manuelt ret byrdefuldt efter et vist punkt, så de fleste bruger værktøjer som vores.
Hvis du vælger den manuelle rute, så tjek hvornår du bør overveje at tilføje en ekstra node til din klynge. Vil du undgå besværet? Evaluer ClusterControl gratis i 30 dage for at se, hvordan dets funktioner gør håndteringen af storstilet open source enkel og effektiv.
Uanset hvordan du vil administrere og skalere dine databaser, følg os på Twitter eller LinkedIn, eller abonner på vores nyhedsbrev for at få de seneste nyheder og bedste praksis, når du administrerer open source-baseret databaseinfrastruktur, så ses vi snart!