I vores tidligere blog om SCUMM-dashboards så vi på MySQL-oversigtsdashboardet. Den nye version af ClusterControl (ver. 1.7) byder på en række højopløselige grafer med nyttige metrikker, og vi gennemgik betydningen af hver af metrikkerne, og hvordan de hjælper dig med at fejlfinde din database. I denne blog vil vi se på MySQL Replication-dashboardet. Lad os fortsætte med detaljerne i dette dashboard om, hvad der har at tilbyde.
MySQL Replication Dashboard
MySQL-replikeringsdashboardet tilbyder et meget ligetil sæt grafer, der gør det nemmere at overvåge din MySQL-master og replika(er). Startende fra toppen viser den de vigtigste variabler og informationer for at bestemme sundheden for replikaen(erne) eller endda mesteren. Dette dashboard tilbyder en meget nyttig del, når man skal inspicere slavernes helbred eller en master i master-master-opsætning. Man kan lige så godt kontrollere masterens binære logoprettelse på dette dashboard og bestemme den overordnede dimension i form af den genererede størrelse på en bestemt given periode.
Den første ting i dette dashboard giver dig de vigtigste oplysninger, du muligvis har brug for om din kopis helbred. Se grafen nedenfor:

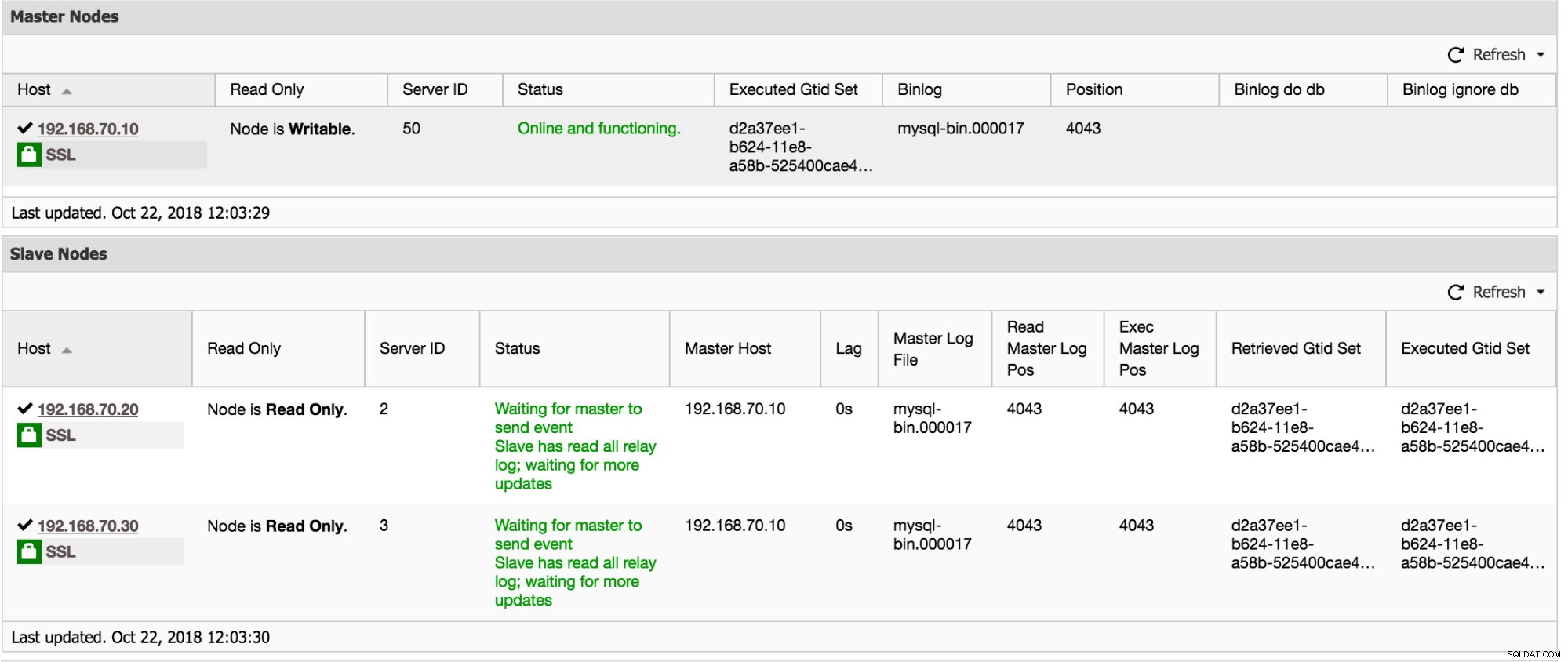
Dybest set vil den vise dig slavetrådens IO_Thread, SQL_Thread, replikeringsfejl og hvis read_only variabel er aktiveret. Fra eksempelskærmbilledet ovenfor viser al information, at min slave 192.168.70.20 er sund og kører normalt.
Derudover har ClusterControl også information at indsamle, hvis du går over til Cluster -> Oversigt. Rul ned, og du kan se grafen nedenfor:
Et andet sted at se replikeringsopsætningen er topologivisningen af replikeringsopsætningen, tilgængelig på Cluster -> Topology. Det giver et hurtigt overblik over de forskellige noder i opsætningen, deres roller, replikeringsforsinkelse, hentet GTID og mere. Se grafen nedenfor:
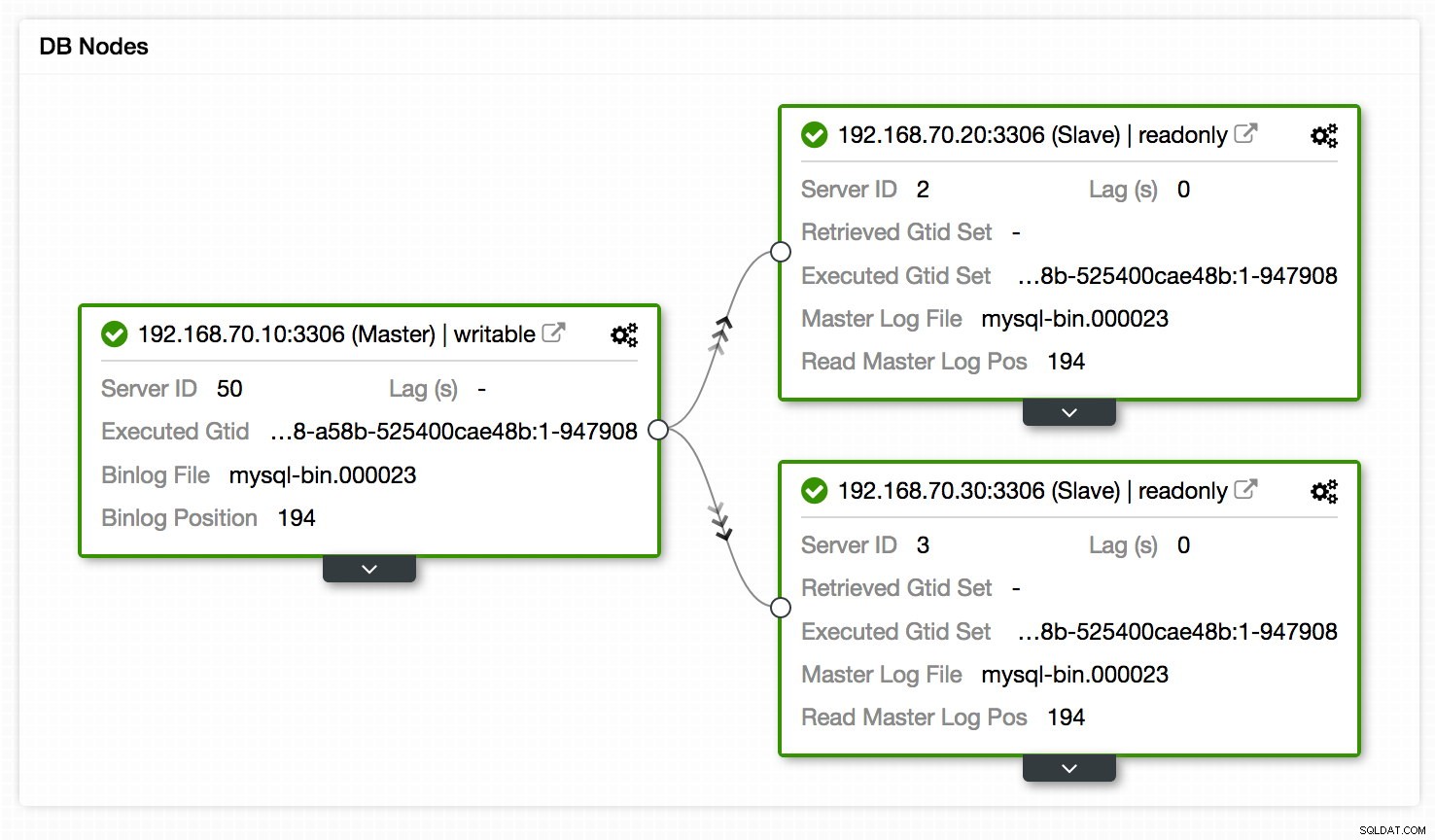
Ud over dette viser Topology View også alle de forskellige noder, der udgør en del af din databaseklynge, uanset om det er databasenoder, load balancers (ProxySQL/MaxScale/HaProxy) eller voldgiftsdommere (garbd), såvel som forbindelserne mellem dem. Noderne, forbindelserne og deres statusser opdages af ClusterControl. Da ClusterControl løbende overvåger noderne og opbevarer statusoplysninger, afspejles eventuelle ændringer i topologien i webgrænsefladen. I tilfælde af at der rapporteres fejl i noder, kan du bruge denne visning sammen med SCUMM Dashboards og se, hvilken påvirkning det kan have forårsaget.
Topologivisningen har en vis lighed med Orchestrator, hvor du kan administrere noderne, ændre master ved at trække og slippe objektet på den ønskede master, genstarte noder og synkronisere data. For at vide mere om vores topologivisning, foreslår vi, at du læser vores tidligere blog - "Visualisering af din klyngetopologi i ClusterControl".
Lad os nu fortsætte med graferne.
-
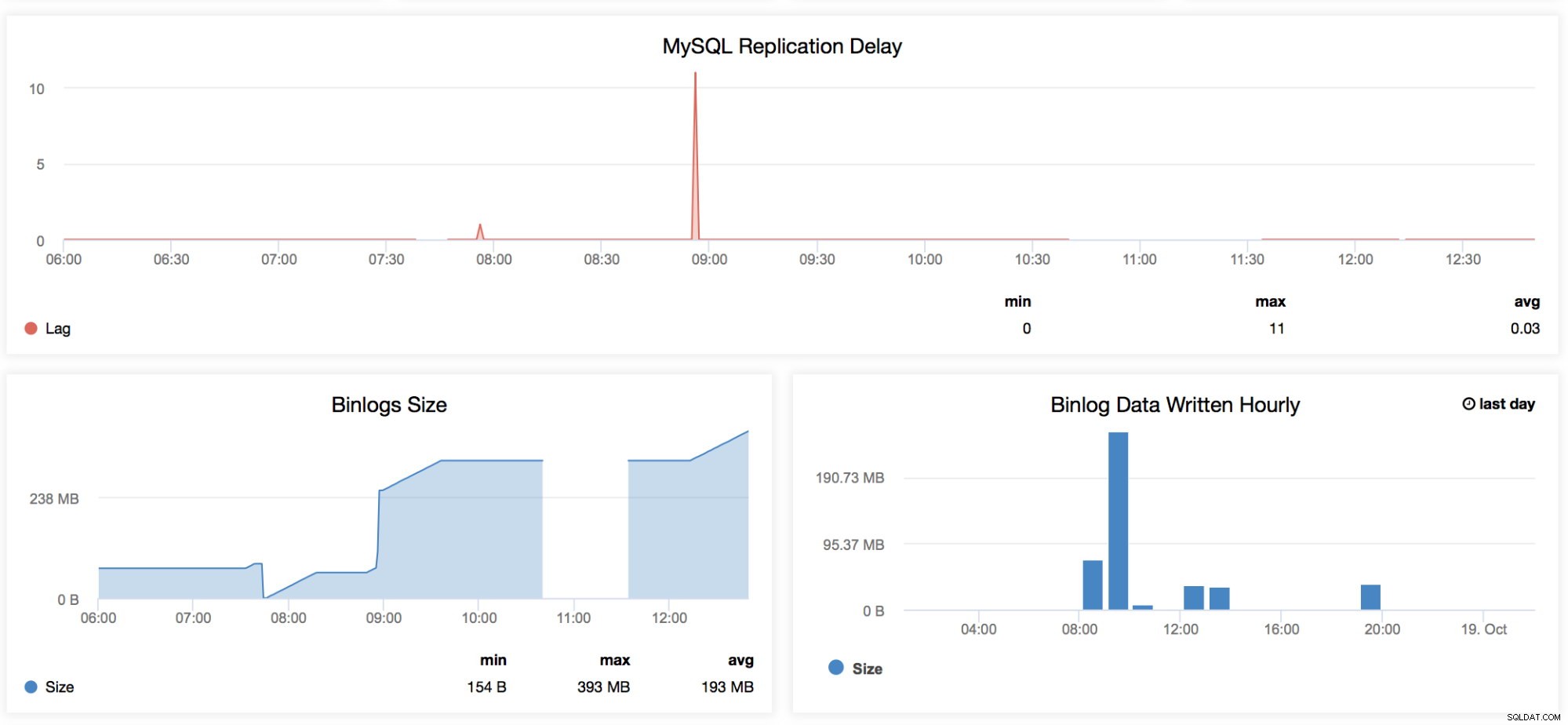
MySQL-replikeringsforsinkelse
Denne graf er meget velkendt for alle, der administrerer MySQL, især dem, der arbejder på daglig basis med deres master-slave-opsætning. Denne graf har tendenserne for alle de forsinkelser, der er registreret for et specifikt tidsinterval, der er angivet i dette dashboard. Når vi vil tjekke den periodiske faldtid, som vores replika har, så er denne graf god at se på. Der er visse tilfælde, hvor en replika kan halte af mærkelige årsager, såsom din RAID har en degraderet BBU og skal udskiftes, en tabel har ingen unik nøgle, men ikke på masteren, en uønsket fuld tabelscanning eller fuld indeksscanning eller en dårlig forespørgsel blev efterladt kørende af en udvikler. Dette er også en god indikator til at afgøre, om slaveforsinkelse er et nøgleproblem, så vil du måske drage fordel af parallel replikering. -
Binlog Størrelse
Disse grafer er relateret til hinanden. Binlog Size-grafen viser dig, hvordan din node genererer den binære log og hjælper med at bestemme dens dimension baseret på den tidsperiode, du scanner. -
Binlog-data skrevet hver time
Binlog-data skrevet timevis er en graf baseret på den aktuelle dag og den foregående registrerede dag. Dette kan være nyttigt, når du vil identificere, hvor stor din node er, der accepterer skrivninger, som du senere kan bruge til kapacitetsplanlægning.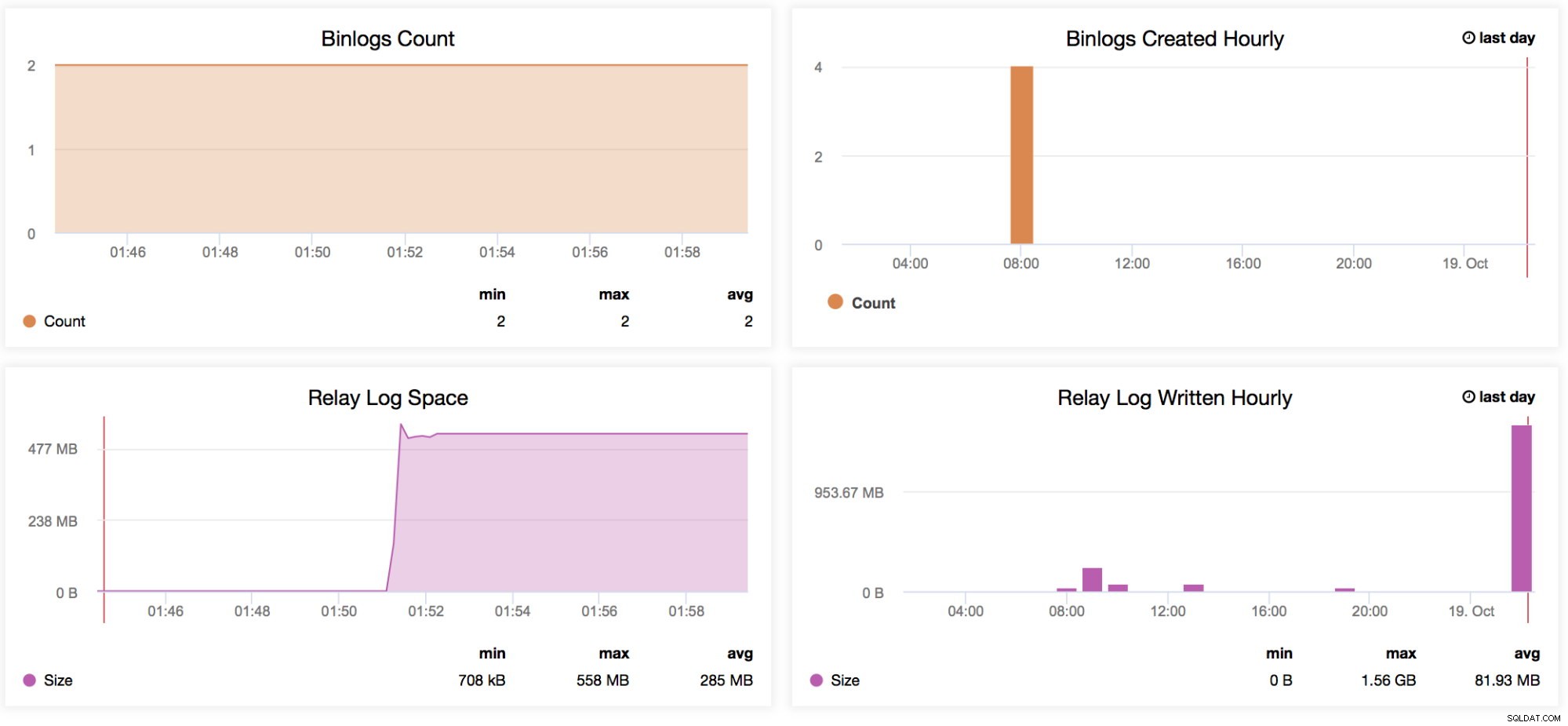
-
Binlogs Antal
Lad os sige, at du forventer høj trafik i en given uge. Du ønsker at sammenligne, hvor store skriverier der går gennem din herre og slaver med den foregående uge. Denne graf er meget nyttig til denne slags situationer - For at bestemme, hvor høje de genererede binære logfiler var på selve masteren eller endda på slaverne, hvis log_slave_updates-variablen er aktiveret. Du kan også bruge denne indikator til at bestemme dine genererede master vs slaves binære logdata, især hvis du filtrerer nogle tabeller eller skemaer (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) på dine slaver, der blev genereret, mens log_slave_updates er aktiveret. -
Binlogs oprettet hver time
Denne graf er en hurtig oversigt til at sammenligne din oprettelse af binlogs hver time fra i går og dagens dato. -
Relælogplads
Denne graf tjener som grundlag for de genererede relælogfiler fra din replika. Når det bruges sammen med MySQL-replikeringsforsinkelsesgrafen, hjælper det med at bestemme, hvor stort antallet af genererede relælogfiler er, hvilket administratoren skal overveje med hensyn til disktilgængelighed for den aktuelle replika. Det kan forårsage problemer, når din slave halter hårdt og genererer et stort antal relælogfiler. Dette kan hurtigt optage din diskplads. Der er visse situationer, hvor slaven/replikaen på grund af et højt antal skrivninger fra masteren vil halte enormt, og generering af en stor mængde logfiler kan forårsage nogle alvorlige problemer på den replika. Dette kan hjælpe operationsteamet, når de taler med deres ledelse om kapacitetsplanlægning. -
Relælog skrevet hver time
Samme som relælogrummet, men tilføjer et hurtigt overblik for at sammenligne dine relælogs skrevet fra i går og dagens dato.
Konklusion
Du lærte, at brug af SCUMM til at overvåge din MySQL-replikering tilføjer mere produktivitet og effektivitet til driftsteamet. At bruge de funktioner, vi har fra tidligere versioner, kombineret med de grafer, der leveres med SCUMM, er som at gå i fitnesscenteret og se massive forbedringer i din produktivitet. Dette er, hvad SCUMM kan tilbyde:overvågning på steroider! (nu er vi ikke fortaler for, at du skal tage steroider, når du går i fitnesscenter!)
I del 3 af denne blog vil jeg diskutere InnoDB Metrics og MySQL Performance Schema Dashboards.