Vi får nogle gode tilbagemeldinger med hensyn til vores produkt ClusterControl, især hvor nemt det er at installere og komme i gang. Installation af ny software er én ting, men at bruge den korrekt er en anden.
Det er ikke ualmindeligt at være utålmodig efter at teste ny software, og man vil hellere lege med en ny spændende applikation end at læse dokumentation, inden man går i gang. Det er lidt uheldigt, da du kan gå glip af vigtige funktioner eller misforstå, hvordan du bruger dem.
Denne blogserie dækker alle de grundlæggende funktioner i ClusterControl til MySQL, MongoDB &PostgreSQL med eksempler på, hvordan du får mest muligt ud af din opsætning. Det giver dig et dybt dyk i forskellige emner for at spare dig tid.
Disse er emnerne i denne serie:
- Implementering af de første klynger
- Tilføjelse af din eksisterende infrastruktur
- Ydeevne og sundhedsovervågning
- Gør dine komponenter til HA
- Workflowstyring
- Beskyttelse af dine data
- Beskyttelse af dine data
- Indgående brugssag
I dagens indlæg dækker vi installation af ClusterControl og implementering af dine første klynger.
Forberedelser
I denne serie vil vi gøre brug af et sæt Vagrant-kasser, men du kan bruge din egen infrastruktur, hvis du vil. Hvis du ønsker at teste det med Vagrant, har vi gjort et eksempel på opsætning tilgængelig fra følgende Github-lager:https://github.com/severalnines/vagrant
Klon repoen til din egen maskine:
$ git clone example@sqldat.com:severalnines/vagrant.gitTopologien af de omstrejfende noder er som følger:
- vm1:clustercontrol
- vm2:database node1
- vm3:database node2
- vm4:database node3
Du kan nemt tilføje yderligere noder, hvis du vil, ved at ændre følgende linje:
4.times do |n|Vagrant-filen er konfigureret til automatisk at installere ClusterControl på den første node og videresende brugergrænsefladen for ClusterControl til port 8080 på din vært, der kører Vagrant. Så hvis din værts ip-adresse er 192.168.1.10, finder du ClusterControl UI her:https://192.168.1.10:8080/clustercontrol/
Installation af ClusterControl
Du kan springe dette over, hvis du vælger at bruge Vagrant-filen, og få den automatiske installation. Men installationen af ClusterControl er ligetil og vil tage mindre end fem minutter.
Med pakkeinstallationen skal du blot udstede følgende tre kommandoer på ClusterControl-noden for at få den installeret:
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userDet er det:det kan ikke blive nemmere end dette. Hvis installationsscriptet ikke er stødt på nogen problemer, skal ClusterControl være installeret og kørende. Du kan nu logge ind på ClusterControl på følgende URL:https://192.168.1.210/clustercontrol
Når du har oprettet en administratorkonto og logget ind, bliver du bedt om at tilføje din første klynge.
Implementer en Galera-klynge
Du bliver bedt om at oprette en ny databaseserver/klynge eller importere en eksisterende (dvs. allerede implementeret) server eller klynge:
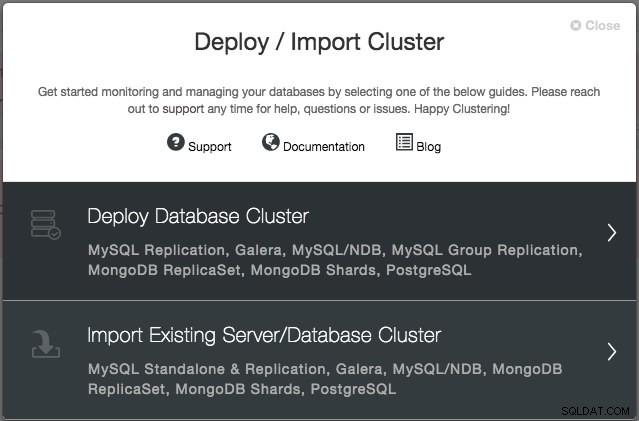
Vi vil implementere en Galera-klynge. Der er to sektioner, der skal udfyldes. Den første fane er relateret til SSH og generelle indstillinger:
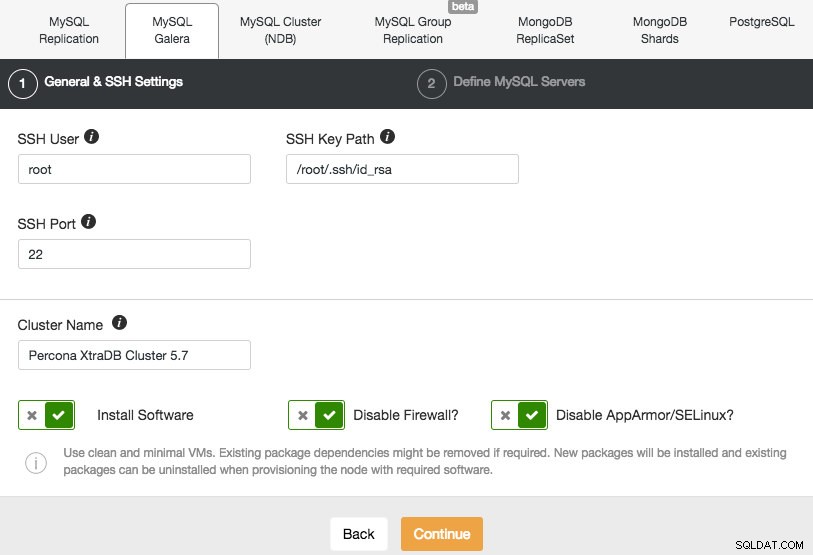
For at tillade ClusterControl at installere Galera-noderne, bruger vi root-brugeren, der fik SSH-adgang af Vagrant-bootstrap-scripts. I tilfælde af at du vælger at bruge din egen infrastruktur, skal du indtaste en bruger her, som har tilladelse til at lave adgangskodefri SSH til de noder, som ClusterControl vil kontrollere. Bare husk på, at du selv skal konfigurere adgangskodefri SSH fra ClusterControl til alle databasenoder på forhånd.
Sørg også for at deaktivere AppArmor/SELinux. Se her hvorfor.
Fortsæt derefter til anden fase og angiv de databaserelaterede oplysninger og målværterne:
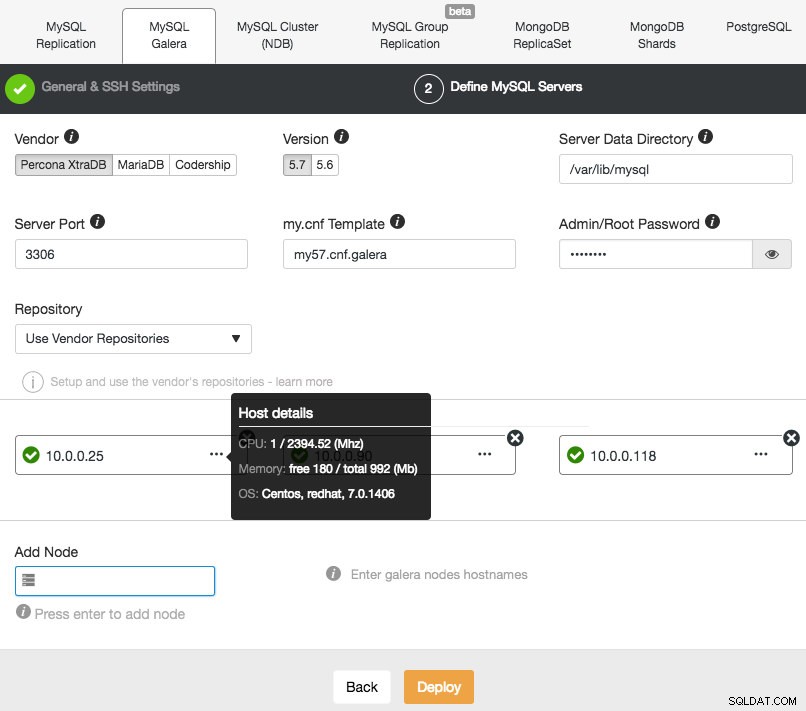
ClusterControl vil straks udføre nogle sundhedstjek, hver gang du trykker på Enter, når du tilføjer en node. Du kan se værtsoversigten ved at holde markøren over hver defineret node. Når alt er grønt, betyder det, at ClusterControl har forbindelse til alle noder, du kan klikke på Deploy. Et job vil blive skabt for at bygge den nye klynge. Det gode er, at du kan holde styr på forløbet af dette job ved at klikke på Aktivitet -> Jobs -> Opret klynge -> Fuld jobdetaljer :
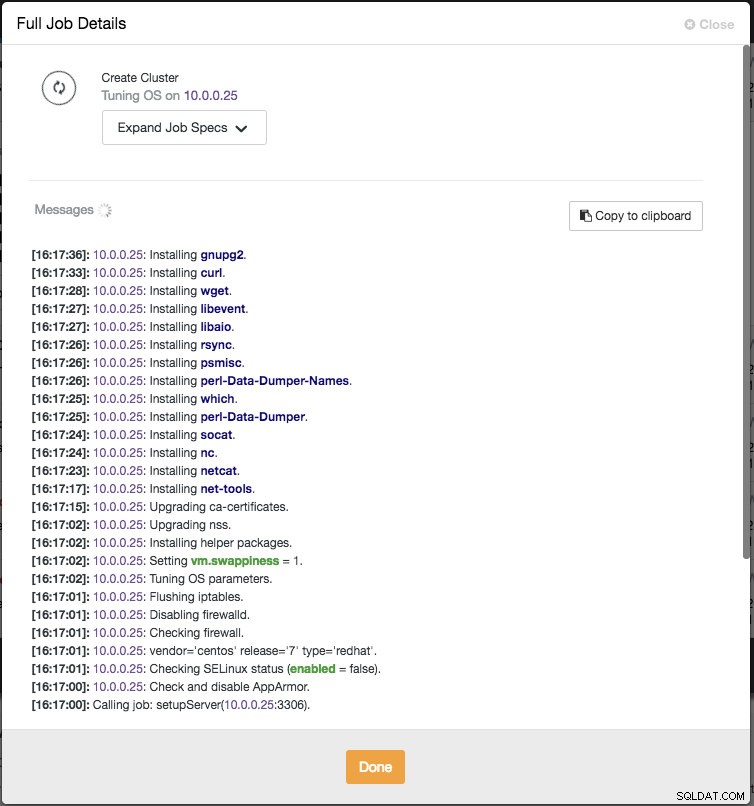
Når jobbet er afsluttet, har du lige oprettet din første klynge. Klyngeoversigten skulle se sådan ud:
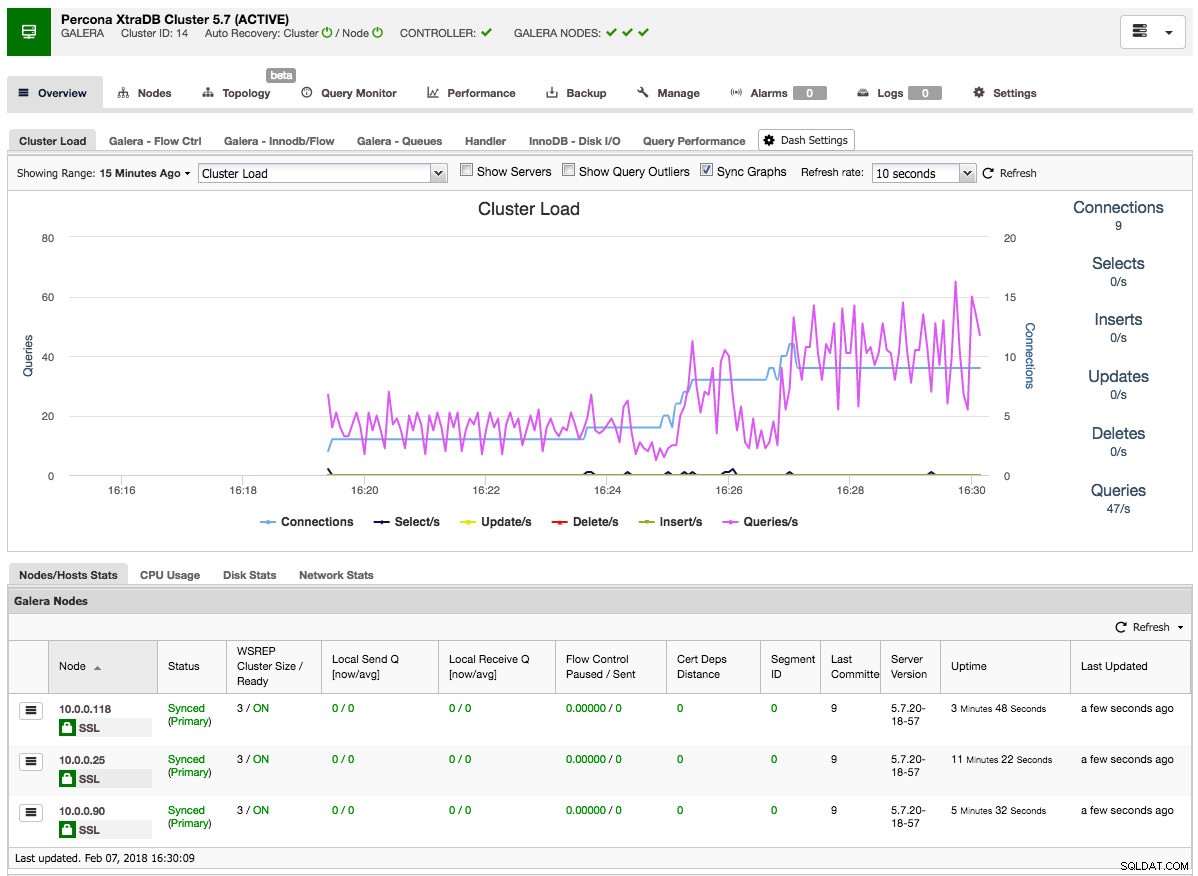
På fanen noder kan du udføre enhver handling, du normalt ville udføre på en klynge. Forespørgselsmonitoren giver dig et godt overblik over både kørende og topforespørgsler. Performance-fanen hjælper dig med at holde et vågent øje med din klynges ydeevne og indeholder også rådgivere, der hjælper dig med at handle proaktivt på datatendenser. Sikkerhedskopieringsfanen giver dig mulighed for nemt at planlægge sikkerhedskopier og gemme dem på lokalt eller skylager. Fanen Administrer giver dig mulighed for at udvide din klynge eller gøre den meget tilgængelig for dine applikationer gennem en belastningsbalancer.
Al denne funktionalitet vil blive dækket i senere blogindlæg i denne serie.
Implementer en MySQL-replikeringsklynge
Implementering af en MySQL-replikeringsopsætning ligner Galera-databaseimplementering, bortset fra at den har en ekstra fane i implementeringsdialogen, hvor du kan definere replikeringstopologien:
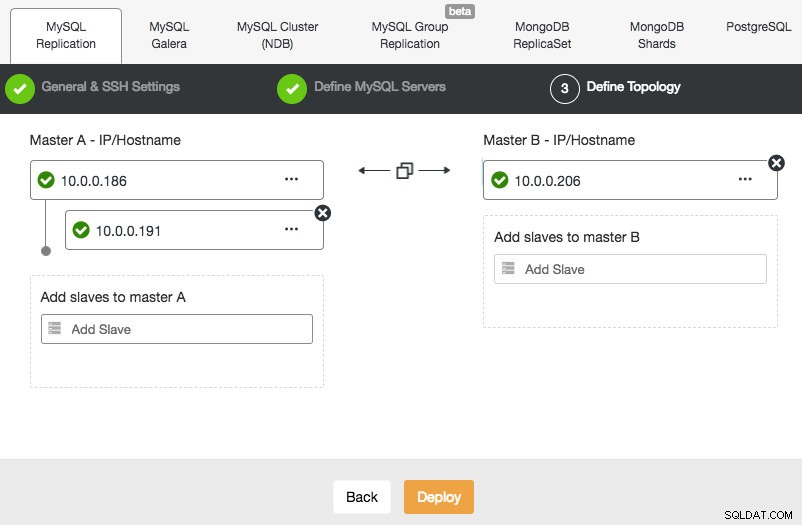
Du kan konfigurere standard master-slave-replikering såvel som master-master-replikering. I tilfælde af sidstnævnte vil kun én master forblive skrivbar ad gangen. Husk, at master-master-replikering ikke kommer med konfliktløsning og garanteret datakonsistens, som i tilfældet med Galera. Brug denne opsætning med forsigtighed, eller kig ind i Galera-klyngen. Når alt er grønt, og du har klikket på Implementer, vil et job blive skabt for at bygge den nye klynge.
Igen er implementeringsforløbet tilgængeligt under Aktivitet -> Jobs.
For at udskalere slaven (læs kopi), skal du blot bruge "Tilføj node"-indstillingen i klyngelisten:
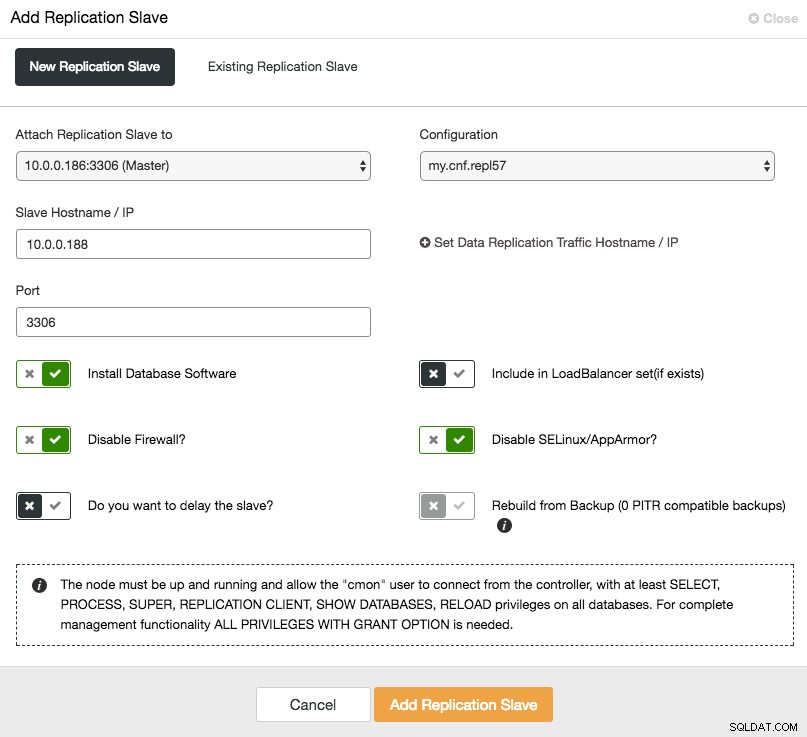
Efter tilføjelse af slaveknudepunktet vil ClusterControl forsyne slaven med en kopi af dataene fra sin master ved hjælp af Xtrabackup eller fra eksisterende PITR-kompatible sikkerhedskopier for den klynge.
Implementer PostgreSQL-replikering
ClusterControl understøtter implementeringen af PostgreSQL version 9.x og nyere. Trinene ligner MySQL-replikeringsimplementering, hvor du i slutningen af implementeringstrinnet kan definere databasetopologien, når du tilføjer noderne:
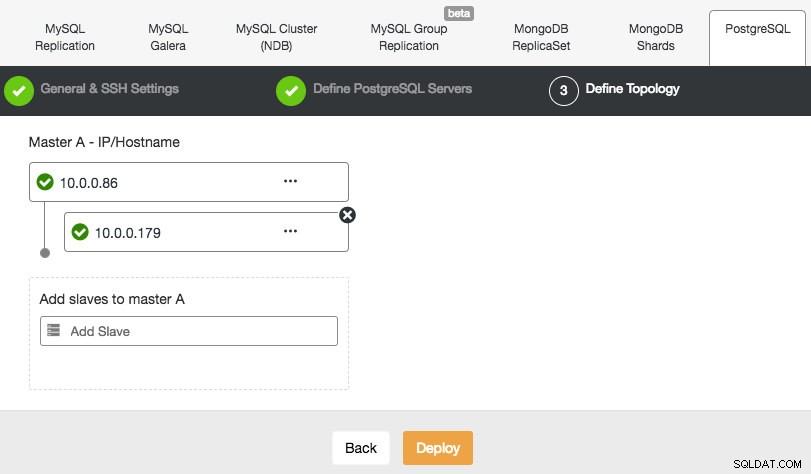
I lighed med MySQL-replikering kan du, når implementeringen er fuldført, skalere ud ved at tilføje replikeringsslave til klyngen. Trinnet er så enkelt som at vælge master og udfylde FQDN for den nye slave:
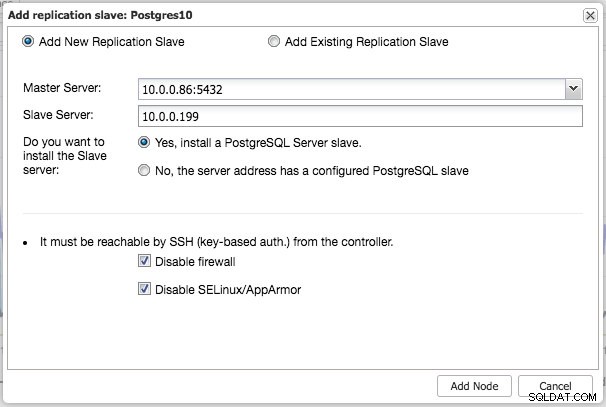
ClusterControl vil derefter udføre den nødvendige datainddeling fra den valgte master ved hjælp af pg_basebackup, konfigurere replikeringsbrugeren og aktivere streaming-replikeringen. PostgreSQL-klyngeoversigten giver dig lidt indsigt i din opsætning:
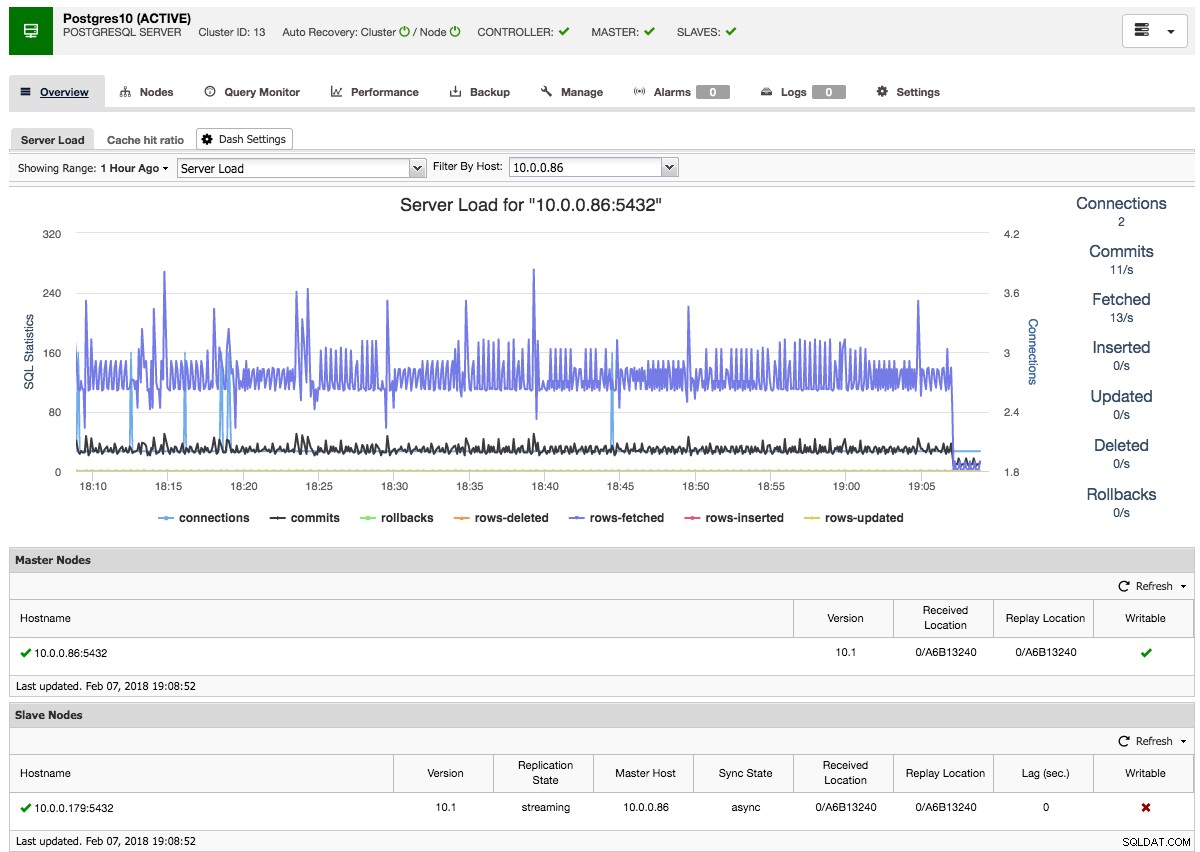
Ligesom med Galera- og MySQL-klyngeoversigterne kan du finde alle de nødvendige faner og funktioner her:forespørgselsmonitoren, ydeevne, backup-fanerne gør dig i stand til at udføre de nødvendige handlinger.
Implementer et MongoDB-replikasæt
Implementering af et nyt MongoDB Replica Set ligner de andre klynger. I dialogboksen Implementer databaseklynge skal du vælge MongoDB ReplicatSet, definere de foretrukne databaseindstillinger og tilføje databasenoder:
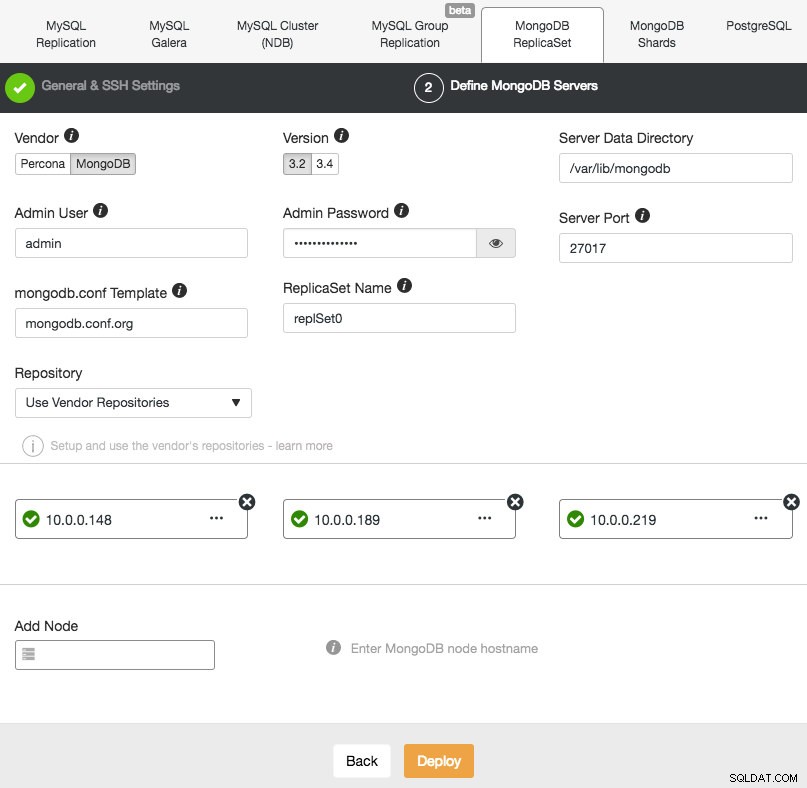
Du kan enten vælge at installere Percona Server til MongoDB fra Percona eller MongoDB Server fra MongoDB, Inc (tidligere 10gen). Du skal også angive MongoDB-administratorbrugeren og adgangskoden, da ClusterControl som standard implementerer en MongoDB-klynge med autentificering aktiveret.
Efter installation af klyngen kan du tilføje en ekstra slave- eller arbiter-knude til replikasættet ved at bruge menuen "Tilføj node" under samme rullemenu fra klyngeoversigten:
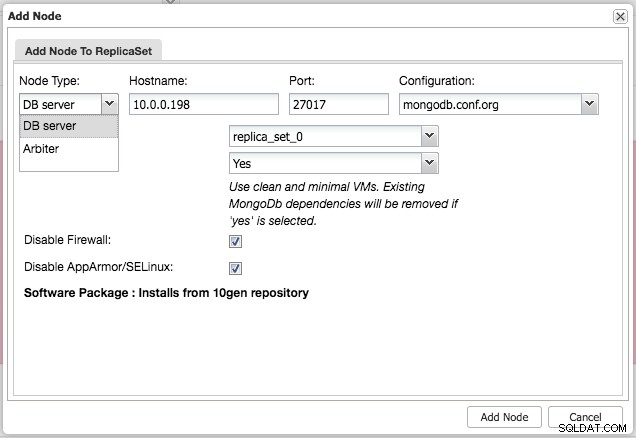
Efter at have tilføjet slaven eller dommeren til replikasættet, vil et job blive skabt. Når dette job er afsluttet, vil det tage et stykke tid, før MongoDB tilføjer det til klyngen, og det bliver synligt i klyngeoversigten:
Sidste tanker
Med disse tre eksempler har vi vist dig, hvor nemt det er at opsætte forskellige klynger fra bunden på kun et par minutter. Det smukke ved at bruge denne Vagrant-opsætning er, at lige så let som at skabe dette miljø, kan du også tage det ned og derefter spawne igen. Imponer dine kolleger ved at vise, hvor hurtigt du kan oprette et arbejdsmiljø.
Det ville selvfølgelig være lige så interessant at tilføje eksisterende værter og allerede udrullede klynger til ClusterControl, og det er det, vi vil dække næste gang.