At køre databaser på cloud-infrastruktur bliver mere og mere populært i disse dage. Selvom en cloud-VM måske ikke er så pålidelig som en server i virksomhedskvalitet, tilbyder de vigtigste cloud-udbydere en række værktøjer til at øge servicetilgængeligheden. I dette blogindlæg viser vi dig, hvordan du opbygger din MySQL- eller MariaDB-database til høj tilgængelighed i skyen. Vi vil se specifikt på Amazon Web Services og Google Cloud Platform, men de fleste af tipsene kan også bruges med andre cloud-udbydere.
Både AWS og Google tilbyder databasetjenester på deres skyer, og disse tjenester kan konfigureres til høj tilgængelighed. Det er muligt at have kopier i forskellige tilgængelighedszoner (eller zoner i GCP), for at øge dine chancer for at overleve delvis fejl i tjenester inden for en region. Selvom en hostet tjeneste er en meget bekvem måde at køre en database på, skal du være opmærksom på, at tjenesten er designet til at opføre sig på en bestemt måde, og at den måske passer til dine krav. Så for eksempel har AWS RDS til MySQL en ret begrænset liste over muligheder, når det kommer til failover-håndtering. Multi-AZ-implementeringer kommer med 60-120 sekunder failover-tid ifølge dokumentationen. Faktisk, da "skygge" MySQL-instansen skal starte fra et "korrupt" datasæt, kan dette tage endnu længere tid, da der kan kræves mere arbejde med at anvende eller rulle tilbage transaktioner fra InnoDB-redologs. Der er en mulighed for at forfremme en slave til at blive en mester, men det er ikke muligt, da du ikke kan genslave eksisterende slaver fra den nye mester. I tilfælde af en administreret service er det også i sig selv mere komplekst og sværere at spore ydeevneproblemer. Mere indsigt i RDS til MySQL og dets begrænsninger i dette blogindlæg.
På den anden side, hvis du beslutter dig for at administrere databaserne, er du i en anden verden af muligheder. En række ting, du kan gøre på bart metal, er også mulige på EC2- eller Compute Engine-instanser. Du har ikke overhead til at administrere den underliggende hardware, og alligevel bevarer du kontrollen over, hvordan systemet skal opbygges. Der er to hovedmuligheder, når du designer til MySQL tilgængelighed - MySQL-replikering og Galera Cluster. Lad os diskutere dem.
MySQL-replikering
MySQL-replikering er en almindelig måde at skalere MySQL med flere kopier af dataene. Asynkron eller semi-synkron, det giver mulighed for at udbrede ændringer udført på en enkelt writer, masteren, til replikaer/slaver - som hver vil indeholde det fulde datasæt og kan forfremmes til at blive den nye master. Replikering kan også bruges til at skalere læsninger ved at dirigere læsetrafik til replikaer og aflaste masteren på denne måde. Den største fordel ved replikering er brugervenligheden - det er så almindeligt kendt og populært (det er også nemt at konfigurere), at der er adskillige ressourcer og værktøjer til at hjælpe dig med at administrere og konfigurere det. Vores egen ClusterControl er en af dem - du kan bruge den til nemt at implementere en MySQL-replikeringsopsætning med integrerede belastningsbalancere, administrere topologiændringer, failover/gendannelse og så videre.
Et stort problem med MySQL-replikering er, at det ikke er designet til at håndtere netværksopdelinger eller masters fejl. Hvis en master går ned, skal du promovere en af replikaerne. Dette er en manuel proces, selvom den kan automatiseres med eksterne værktøjer (f.eks. ClusterControl). Der er heller ingen kvorumsmekanisme, og der er ingen støtte til indhegning af mislykkede masterforekomster i MySQL-replikering. Desværre kan dette føre til alvorlige problemer i distribuerede miljøer - hvis du promoverede en ny master, mens din gamle kommer online igen, kan du ende med at skrive til to noder, skabe datadrift og forårsage alvorlige datakonsistensproblemer.
Vi vil se nærmere på nogle eksempler senere i dette indlæg, der viser dig, hvordan du opdager netværksopdelinger og implementerer STONITH eller en anden indhegningsmekanisme til din MySQL-replikeringsopsætning.
Galera-klynge
Vi så i det foregående afsnit, at MySQL-replikering mangler hegn og kvorum-understøttelse - det er her Galera Cluster skinner. Den har en quorum support indbygget, den har også en hegnsmekanisme, der forhindrer opdelte noder i at acceptere skrivninger. Dette gør Galera Cluster mere egnet end replikering i multi-datacenter opsætninger. Galera Cluster understøtter også flere forfattere og er i stand til at løse skrivekonflikter. Du er derfor ikke begrænset til en enkelt writer i et multi-datacenter setup, det er muligt at have en writer i hvert datacenter, hvilket reducerer latensen mellem din applikation og database tier. Det fremskynder ikke skrivninger, da hver skrivning stadig skal sendes til hver Galera-knude for certificering, men det er stadig nemmere end at sende skrivninger fra alle applikationsservere på tværs af WAN til en enkelt fjernmaster.
Så god som Galera er, er det ikke altid det bedste valg til alle arbejdsopgaver. Galera er ikke en drop-in-erstatning for MySQL/InnoDB. Den deler fælles funktioner med "normal" MySQL - den bruger InnoDB som lagermaskine, den indeholder hele datasættet på hver node, hvilket gør JOINs mulige. Alligevel adskiller nogle af Galeras ydeevneegenskaber (såsom ydeevnen af skrivninger, der påvirkes af netværksforsinkelse) sig fra, hvad du ville forvente af replikeringsopsætninger. Vedligeholdelse ser også anderledes ud:håndtering af skemaændringer fungerer lidt anderledes. Nogle skemadesigns er ikke optimale:Hvis du har hotspots i dine tabeller, som ofte opdaterede tællere, kan dette føre til ydeevneproblemer. Der er også forskel på bedste praksis relateret til batchbehandling - i stedet for at udføre forespørgsler i store transaktioner, ønsker du, at dine transaktioner skal være små.
Proxy-niveau
Det er meget svært og besværligt at bygge et højt tilgængeligt setup uden proxyer. Selvfølgelig kan du skrive kode i din applikation for at holde styr på databaseforekomster, sortliste usunde, holde styr på den eller de skrivbare mastere og så videre. Men dette er meget mere komplekst end blot at sende trafik til et enkelt slutpunkt - det er her en proxy kommer ind. ClusterControl giver dig mulighed for at implementere ProxySQL, HAProxy og MaxScale. Vi vil give nogle eksempler på brug af ProxySQL, da det giver os god fleksibilitet til at kontrollere databasetrafik.
ProxySQL kan implementeres på et par måder. Til at begynde med kan den implementeres på separate værter, og Keepalived kan bruges til at levere Virtual IP. Den virtuelle IP vil blive flyttet rundt, hvis en af ProxySQL-forekomsterne fejler. I skyen kan denne opsætning være problematisk, da det normalt ikke er nok at tilføje en IP til grænsefladen. Du bliver nødt til at ændre Keepalved-konfigurationen og scripts for at arbejde med elastisk IP (eller statisk - uanset hvad din cloud-udbyder kalder det). Så ville man bruge cloud API eller CLI til at flytte denne IP-adresse til en anden vært. Af denne grund vil vi foreslå at samle ProxySQL med applikationen. Hver applikationsserver vil blive konfigureret til at oprette forbindelse til den lokale ProxySQL ved hjælp af Unix-sockets. Da ProxySQL bruger en engelproces, kan ProxySQL-nedbrud detekteres/genstartes inden for et sekund. I tilfælde af hardwarenedbrud vil den pågældende applikationsserver gå ned sammen med ProxySQL. De resterende applikationsservere kan stadig få adgang til deres respektive lokale ProxySQL-instanser. Denne særlige opsætning har yderligere funktioner. Sikkerhed - ProxySQL, fra version 1.4.8, understøtter ikke SSL på klientsiden. Det kan kun opsætte SSL-forbindelse mellem ProxySQL og backend. Samlokalisering af ProxySQL på applikationsværten og brug af Unix-sockets er en god løsning. ProxySQL har også mulighed for at cache forespørgsler, og hvis du skal bruge denne funktion, giver det mening at holde den så tæt på applikationen som muligt for at reducere latens. Vi vil foreslå at bruge dette mønster til at implementere ProxySQL.
Typiske opsætninger
Lad os tage et kig på eksempler på meget tilgængelige opsætninger.
Enkelt datacenter, MySQL-replikering
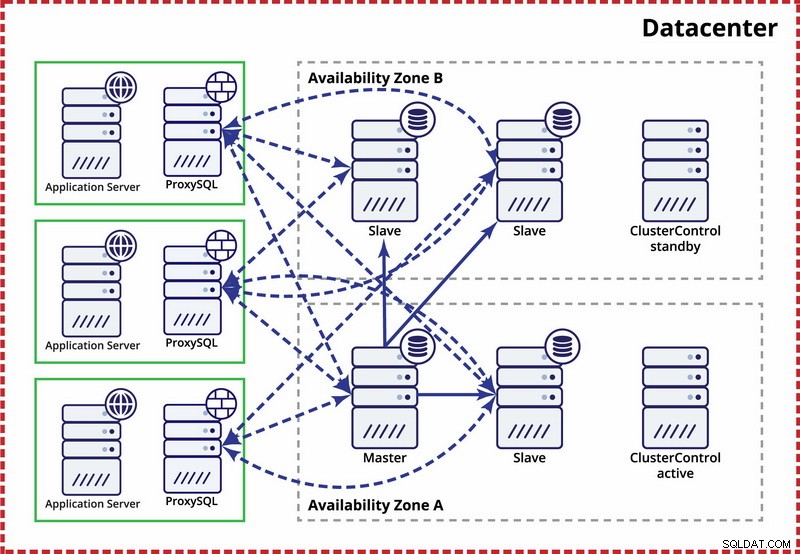
Antagelsen her er, at der er to separate zoner i datacentret. Hver zone har redundant og separat strøm, netværk og tilslutning for at reducere sandsynligheden for, at to zoner svigter samtidigt. Det er muligt at opsætte en replikeringstopologi, der spænder over begge zoner.
Her bruger vi ClusterControl til at styre failoveren. For at løse split-brain-scenariet mellem tilgængelighedszoner samler vi den aktive ClusterControl med masteren. Vi sortlister også slaver i den anden tilgængelighedszone for at sikre, at automatisk failover ikke vil resultere i, at to mastere er tilgængelige.
Flere datacentre, MySQL-replikering
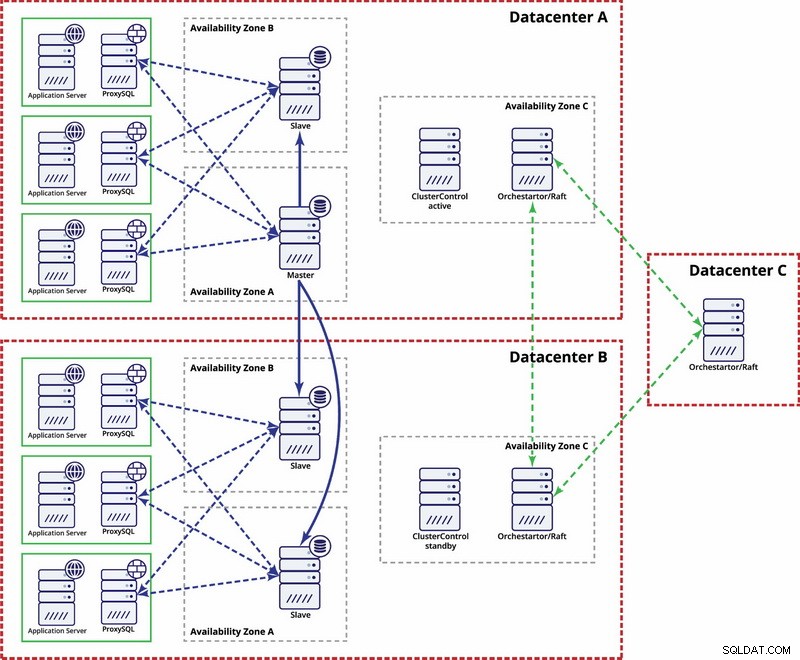
I dette eksempel bruger vi tre datacentre og Orchestrator/Raft til kvorumsberegning. Du skal muligvis skrive dine egne scripts for at implementere STONITH, hvis master er i det partitionerede segment af infrastrukturen. ClusterControl bruges til nodegendannelse og administrationsfunktioner.
Flere datacentre, Galera Cluster
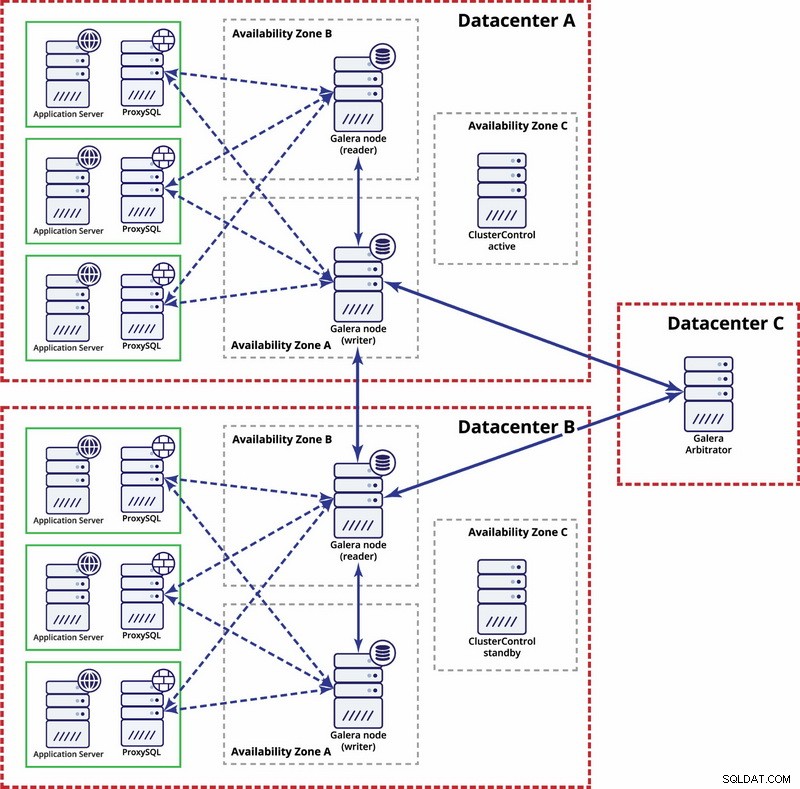
I dette tilfælde bruger vi tre datacentre med en Galera-arbitrator i det tredje - dette gør det muligt at håndtere hele datacenterfejl og reducerer risikoen for netværksopdeling, da det tredje datacenter kan bruges som relæ.
For yderligere læsning, tag et kig på hvidbogen "Sådan designer du meget tilgængelige Open Source-databasemiljøer" og se webinaret "Designing Open Source-databaser til høj tilgængelighed".