Presto er en open source, parallel distribueret, SQL-motor til big data-behandling. Det er udviklet fra bunden af Facebook. Den første interne udgivelse fandt sted i 2013 og var en ganske revolutionerende løsning på deres big data-problemer.
Med de hundredvis af geo-placerede servere og petabytes af data begyndte Facebook at lede efter en alternativ platform til deres Hadoop-klynger. Deres infrastrukturteam ønskede at reducere den tid, der var nødvendig for at køre analysebatchjobs og forenkle pipelineudviklingen ved at bruge programmeringssprog, der er almindeligt kendt i organisationen - SQL.
Ifølge Presto Foundation, "bruger Facebook Presto til interaktive forespørgsler mod flere interne datalagre, inklusive deres 300PB datavarehus. Over 1.000 Facebook-medarbejdere bruger Presto dagligt til at køre mere end 30.000 forespørgsler, der i alt scanner over en petabyte hver om dagen."
Mens Facebook har et enestående datavarehusmiljø, er de samme udfordringer til stede i mange organisationer, der beskæftiger sig med big data.
I denne blog vil vi tage et kig på, hvordan man opsætter et grundlæggende presto-miljø ved hjælp af en Docker-server fra tar-filen. Som datakilde vil vi fokusere på MySQL-datakilden, men det kunne være en hvilken som helst anden populær RDBMS.
Kørsel af Presto i Big Data-miljø
Før vi starter, lad os tage et hurtigt kig på dens vigtigste arkitekturprincipper. Presto er et alternativ til værktøjer, der forespørger HDFS ved hjælp af pipelines af MapReduce-job - såsom Hive. I modsætning til Hive bruger Presto ikke MapReduce. Presto kører med en specialforespørgselsudførelsesmotor med operatører på højt niveau og behandling i hukommelsen.
I modsætning til Hive kan Presto streame data gennem alle stadier på én gang, kørende datastykker samtidigt. Det er designet til at køre ad-hoc analytiske forespørgsler mod enkelte eller distribuerede heterogene datakilder. Den kan nå ud fra en Hadoop-platform for at forespørge relationsdatabaser eller andre datalagre som f.eks. flade filer.
Presto bruger standard ANSI SQL inklusive aggregeringer, joinforbindelser eller analytiske vinduesfunktioner. SQL er velkendt og meget nemmere at bruge sammenlignet med MapReduce skrevet i Java.
Implementering af Presto til Docker
Den grundlæggende Presto-konfiguration kan implementeres med et forudkonfigureret Docker-image eller presto-server-tarball.
Docker-serveren og Presto CLI-containere kan nemt implementeres med:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliDu kan vælge mellem to Presto-serverversioner. Community-version og Enterprise-version fra Starburst. Da vi skal køre det i et ikke-produktionssandbox-miljø, vil vi bruge Apache-versionen i denne artikel.
Forudgående krav
Presto er implementeret udelukkende i Java og kræver, at JVM er installeret på dit system. Det kører på både OpenJDK og Oracle Java. Minimumsversionen er Java 8u151 eller Java 11.
For at downloade JAVA JDK besøg https://openjdk.java.net/ eller https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Du kan tjekke din Java-version med
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto-installation
For at installere Presto vil vi downloade server tar og Presto CLI jar eksekverbar.
Tarballen vil indeholde en enkelt mappe på øverste niveau, presto-server-0.223, som vi kalder installationsmappen.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoDerudover har Presto brug for en datamappe til lagring af logfiler osv.
Det anbefales at oprette en datamappe uden for installationsmappen.
$ mkdir -p ~/data/presto/Denne placering er stedet, hvor vi starter vores fejlfinding.
Konfiguration af Presto
Før vi starter vores første instans, skal vi oprette en masse konfigurationsfiler. Start med oprettelsen af et etc/-bibliotek inde i installationsmappen. Denne placering vil indeholde følgende konfigurationsfiler:
osv/
- Knudeegenskaber - nodemiljøkonfiguration
- JVM Config (jvm.config) - Java Virtual Machine config
- Config Properties(config.properties) -konfiguration for Presto-serveren
- Katalogegenskaber - konfiguration for Connectors (datakilder)
- Log-egenskaber - Logger-konfiguration
Nedenfor kan du finde nogle grundlæggende konfigurationer til at køre Presto sandbox. Besøg dokumentationen for flere detaljer.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoDen grundlæggende etc/ struktur kan se ud som følger:

Det næste trin er at konfigurere MySQL-stikket.
Vi skal oprette forbindelse til en af de 3 noder MariaDB Cluster.
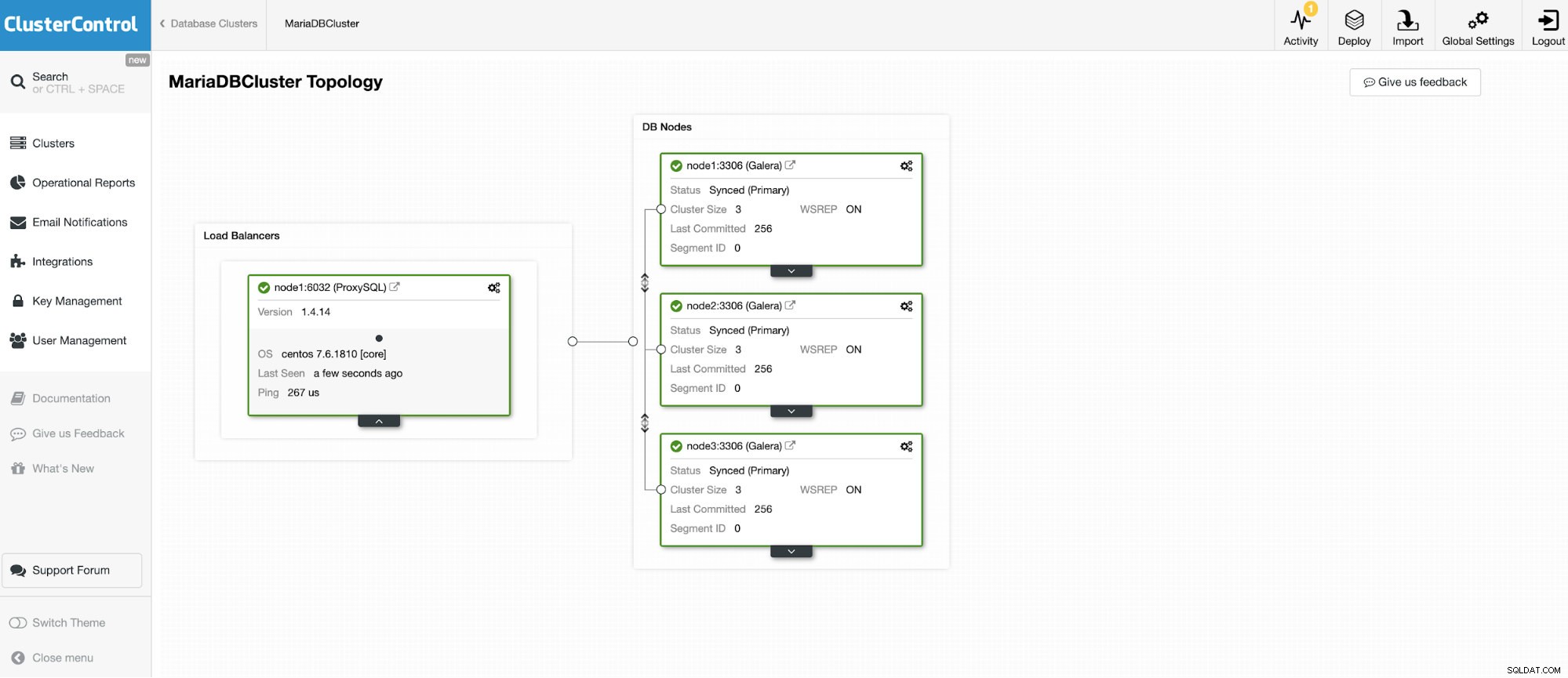
Og en anden selvstændig instans, der kører Oracle MySQL 5.7.
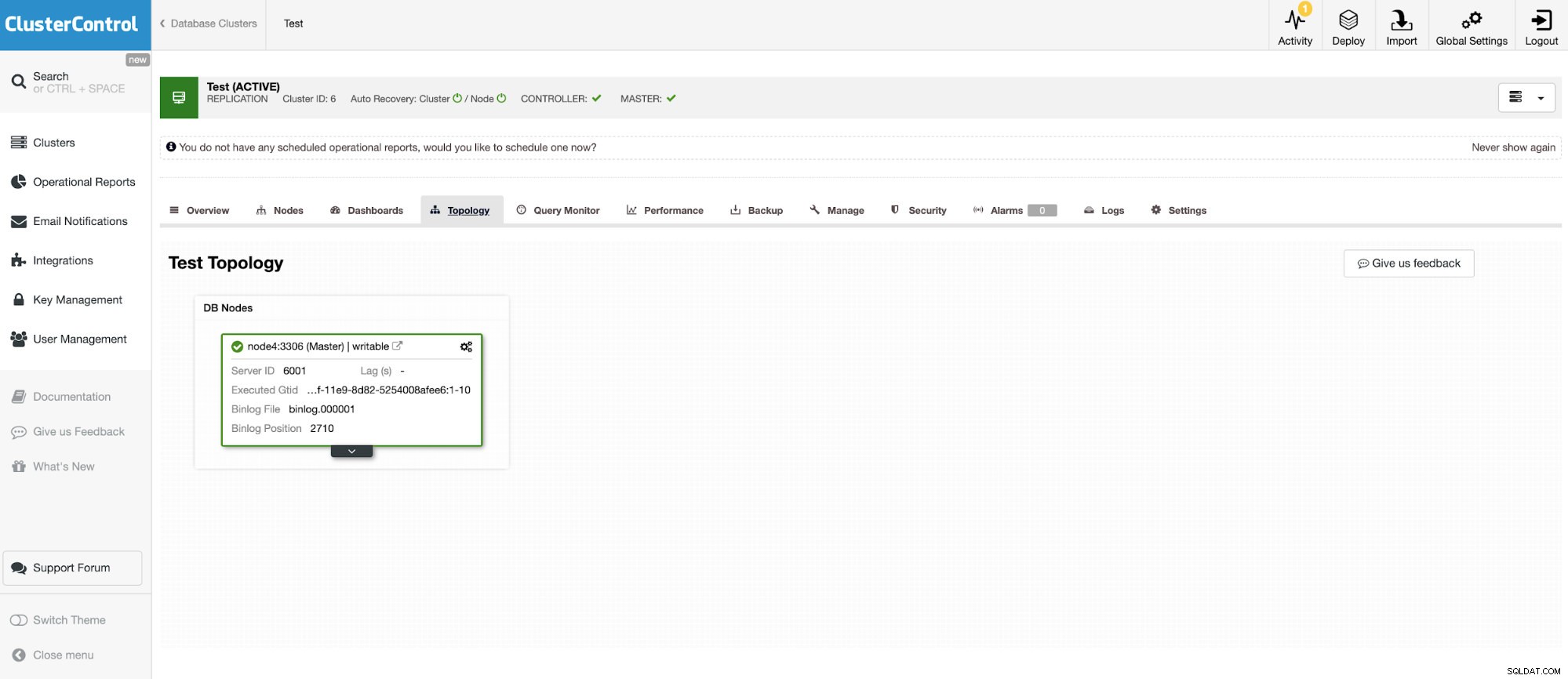
MySQL-forbindelsen tillader forespørgsler og oprettelse af tabeller i en ekstern MySQL-database. Dette kan bruges til at forbinde data mellem forskellige systemer som MariaDB og MySQL fra Oracle.
Presto bruger stikbare stik, og konfigurationen er meget nem. For at konfigurere MySQL-forbindelsen skal du oprette en katalogegenskabsfil i etc/catalog ved navn, for eksempel mysql.properties, for at montere MySQL-stikket som mysql-kataloget. Hver af filerne repræsenterer en forbindelse til en anden server. I dette tilfælde har vi to filer:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretKører Presto
Når alt er indstillet, er det tid til at starte Presto-forekomsten. For at starte presto skal du gå til bin-mappen under preso-installation og køre følgende:
$ bin/launcher start
Started as 18363For at stoppe Presto køre
$ bin/launcher stopNu når serveren er oppe at køre, kan vi oprette forbindelse til Presto med CLI og forespørge på MySQL-databasen.
Sådan starter du Presto-konsolkørsel:
./presto --server localhost:8080 --catalog mysql --schema employeesNu kan vi forespørge i vores databaser via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Begge databaser MariaDB cluster og MySQL er blevet fodret med medarbejderdatabase.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlStatus for forespørgslen er også synlig i Presto webkonsollen:https://localhost:8080/ui/#
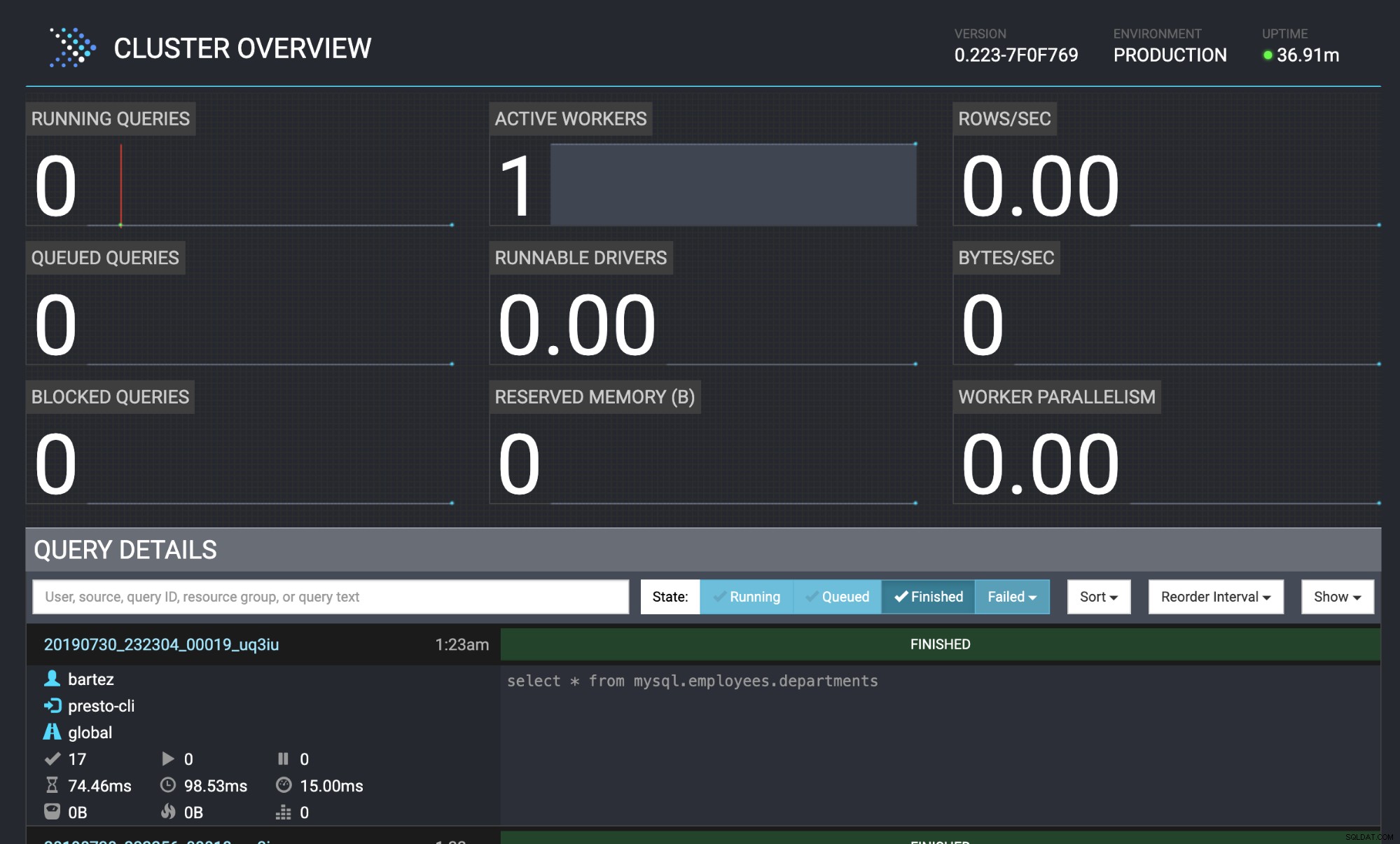 Oversigt over Presto Cluster
Oversigt over Presto Cluster Konklusion
Mange velkendte virksomheder (som Airbnb, Netflix, Twitter) anvender Presto til ydeevne med lav latency. Det er uden tvivl meget interessant software, som måske eliminerer behovet for at køre tunge ETL data warehouse processer. I denne blog tog vi lige et kort kig på MySQL-stikket, men du kan bruge det til at analysere data fra HDFS, objektlagre, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB og mange andre.