Årsag til problemet :
TOKEN metode i SSIS bruger implementeringen af strtok funktion i C++ . Jeg indsamlede disse oplysninger, mens jeg læste bogen Microsoft® SQL Server® 2012 Integration Services stærk>
. Det er nævnt som note på side 113 (Jeg kan godt lide denne bog! Masser af god information. ).
Jeg søgte efter implementeringen af strtok funktion, og jeg fandt følgende links.
INFO:strtok():C-funktion -- dokumentationstillæg - Kodeeksemplet i dette link viser, at funktionen ignorerer på hinanden følgende skilletegn.
Svarene på de følgende SO-spørgsmål påpeger, at strtok funktion er designet til at ignorere på hinanden følgende afgrænsninger.
Behov for at vide, hvornår der ikke vises data mellem to token-separatorer ved hjælp af strtok()
strtok_s adfærd med konsekutive afgrænsninger
Jeg tror, at TOKEN og TOKENCOUNT funktionerne fungerer efter design, men om det er sådan SSIS skal opføre sig, kan være et spørgsmål for Microsoft SSIS-teamet.
Original post - afsnittet ovenfor er en opdatering:
Jeg oprettede en simpel pakke i SSIS 2012 baseret på dine datainput. Som du havde beskrevet i dit spørgsmål, er TOKEN funktion ikke opfører sig efter hensigten. Jeg er enig med dig i, at funktionen ikke ser ud til at virke. Dette indlæg er ikke et svar på dit oprindelige problem.
Her er en alternativ måde at skrive udtrykket på på en relativt enklere måde. Dette virker kun, hvis det sidste segment i din inputpost altid vil have en værdi (f.eks. A1 , B2 , C3 osv.).
Udtryk kan omskrives som :
Denne sætning vil tage input-recorden som parameter, afgrænsningstegnet (^) som den anden parameter. Den tredje parameter beregner det samlede antal segmenter i posterne, når de opdeles med skilletegn. Hvis du har data i det sidste segment, har du med garanti to segmenter. Du kan derefter trække 1 fra for at hente det næstsidste segment.
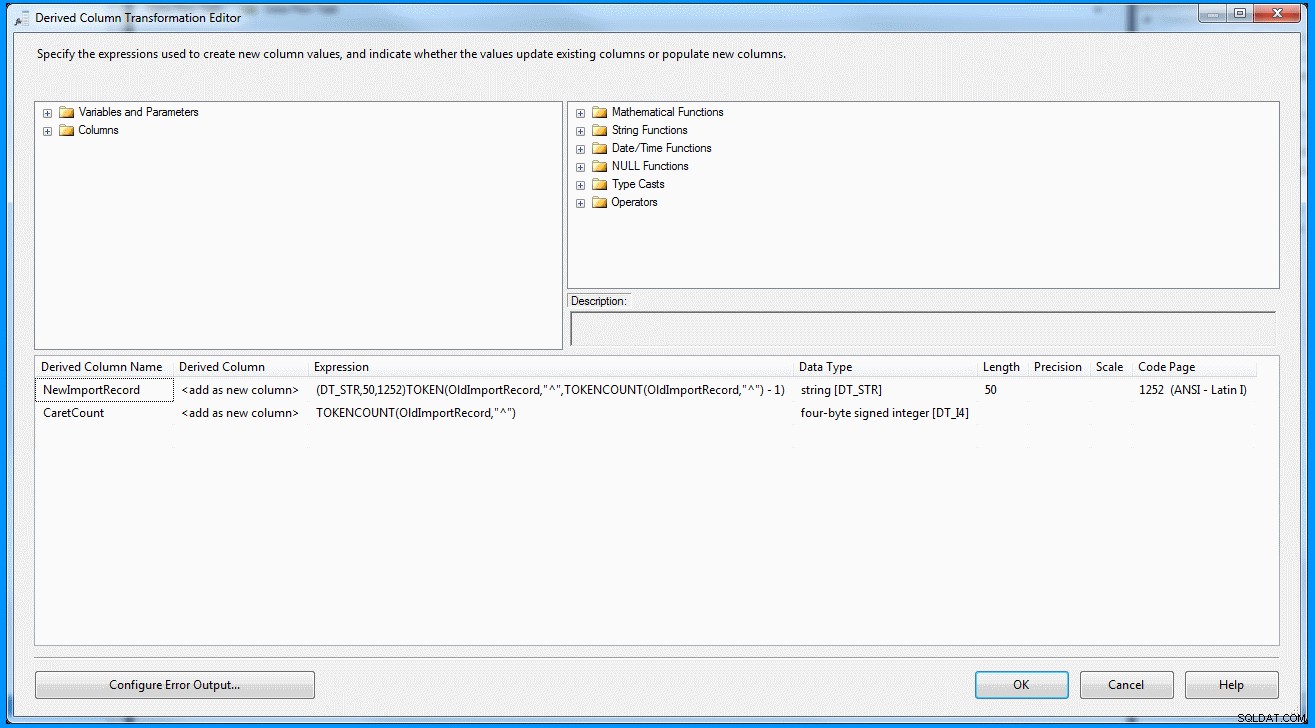
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
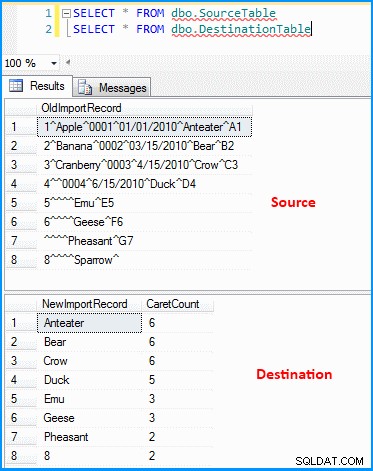
Jeg lavede en simpel pakke med dataflowopgave. OLE DB-kilden henter dataene og den afledte transformation parser og opdeler dataene som på skærmbilledet nedenfor. Outputtet indsættes derefter i destinationstabellen. Du kan se kilde- og destinationstabellerne på det sidste skærmbillede. Destinationstabellen har to kolonner. Den første kolonne gemmer de næstsidste segmentdata, og segmenterne tæller baseret på afgrænsningstegnet (som igen ikke er korrekt). Du kan bemærke, at den sidste post ikke gav de korrekte resultater. Hvis den sidste post ikke havde værdien 8 , så vil ovenstående udtryk mislykkes, fordi udtrykket vil evaluere til nul indeks.
Håber det er med til at forenkle dit udtryk.
Hvis du ikke hører fra nogen andre, vil jeg anbefale at logge dette problem på Microsoft Connect-webstedet .
Opret tabel og udfyld scripts :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Afledt kolonnetransformation i dataflowopgave :
Data i kilde- og destinationstabeller :