På et testbord hos mig ser din oprindelige plan ud som følger.
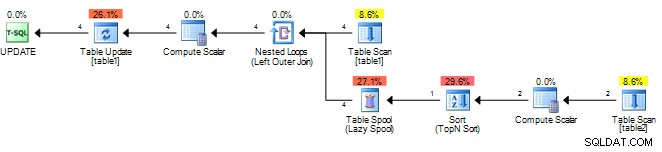
Den beregner bare resultatet én gang og cacher det i en sppol og afspiller derefter resultatet. Du kan prøve følgende, så SQL Server ser underforespørgslen som korreleret og har behov for reevaluering for hver ydre række.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
For mig giver det denne plan uden spolen.
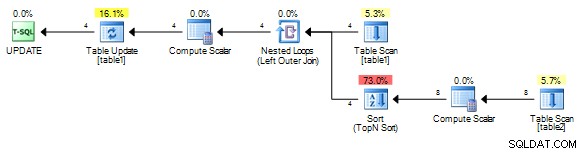
Det er vigtigt at korrelere på et unikt felt fra table1 dog således, at selvom en spole tilføjes, skal den altid spoles tilbage i stedet for tilbage (genafspilning af det sidste resultat), da korrelationsværdien vil være forskellig for hver række.
Hvis tabellerne er store vil dette være langsomt, da det nødvendige arbejde er et produkt af de to tabelrækker (for hver række i table1 den skal lave en fuld scanning af table2 )